JDK11 加入,目前在jdk11\17这种LTS版本中均有支持,也有一些基于OpenJDK11自研的JDK也发布了GA版本,包括了ZGC,如腾讯的Kona JDK11
目前有很多公司已经在生产环境上使用ZGC,初次使用ZGC需谨慎,最好在上线前进行压力测试提前暴露一些调优空间
相比于之前的GC,ZGC放弃了划分新生代,老年代,每次GC都是整堆收集,支持TB级内存,在对比其他GC时,ZGC在内存线性增长和指数级增长方面,暂停时间均明显优于G1\Parall,同时吞吐量方面略低于Parall,与G1差不多,也就是说,ZGC在保证低停顿的基础上,吞吐量也不逊色与G1,调优后暂停时间可以低于10ms,这使得Java应用在实时业务场景中更有前景,因为10ms已经低于Linux的背景噪音,linux的调度可能会产生10ms的调度停顿
减少停顿的主要措施:
- 多视图映射
- 染色指针
- 读屏障
- 3色标记,和G1基本相同,都是增量更新和SATB
- 转移阶段并发化
垃圾回收周期

下述流程中带Pause的都是会STW的,他们的耗时应该越短越好
总体上来看,ZGC主要有2个大的阶段:标记、转移,其中标记又有初始标记、并发标记、再标记3个子步骤,转移有并发转移准备、初始转移、并发转移3个子步骤
大体看来,ZGC在回收周期上讲转移这个过程进行了并发化处理,降低了转移阶段的STW耗时
初始标记
第一个阶段是 Pause Mark Start :主要做一些全局状态的设置和全局数据结构的初始化这类轻量化的任务,标明后续并发阶段需要做 GC 的 Concurrent Mark。
并发标记/对象重定位
第二个阶段是 Concurrent Mark & Remap:将耗时占比最大的 GC Roots 进行并发化改造,支持并发 Roots 标记。从 GC Roots 进行对象图的并发标记。上一轮 GC 的指针更新(Remap)通过 Piggyback,放到当前阶段执行,从而减少对对象图的遍历。
再标记
第三个阶段是 Pause Mark End:这一阶段做 Concurrent Mark 的同步,结束并发标记阶段,同时设置部分全局变量。
并发转移准备
第四个阶段是 Concurrent Prepare:这一阶段主要做 java.lang.ref.Reference 等弱引用的处理,并选择出需要 Compact 的 ZGC Region。
初始转移
第五个阶段是 Pause Relocate Start:这一阶段和第三阶段比较类似,主要是全局同步,设置全局变量,并指示 Relocate 阶段的开始。
并发转移
第六个阶段是 Concurrent Relocate:并发的搬移对象。
相对于其他 GC,ZGC 需要三个 STW 阶段来做全局的同步,但每个 STW 中的任务都很明确,需要完成的任务的时间和 CPU 的处理速度正相关,因此可以做到 ms 级别的停顿。相对于 G1GC,ZGC 的难点在于如何进行 GC Roots 的并发化改造和对象搬移的并发化改造。
多视图映射
当应用程序创建对象时,首先在堆空间申请一个虚拟地址,ZGC同时会为该对象在M0、M1和Remapped三个视图空间分别申请一个虚拟地址,且这三个虚拟地址对应同一个物理地址。

因此 ZGC 的 Java 堆需要在虚拟地址中占用三份地址。ZGC 通过内存文件来占用实际的物理内存,然后将这个内存文件映射到 Remapped、Mark0 和 Mark1 指向的虚拟地址。可以看出,虽然表面上 ZGC 的 Java Heap 占用了三份虚拟地址,但是实际的物理地址只有一份。这也是 linux 的命令 top 或者 ps 看到启用 ZGC 的 Java 进程 RSS 内存膨胀三倍的原因,但开启 ZGC 之后观察到的 RSS 消耗并非实际物理内存消耗。
在GC过程中,对象会在多个视图间切换,M0/M1是为了区分此次GC和上一次GC,有点类似G1年轻代收集中的S0/S1的作用

可以看到开始GC时,对象的视图都处于Remapped状态,并发标记过程中,GC线程和应用线程同时运行,GC线程和应用线程能够触碰到的对象都不应该进行回收,
并发标记阶段
- GC线程访问对象时,视图是Remapped,修改为M0,视图是M0,说明已经被其他线程标记或者是新建对象,不需处理
- 应用线程访问对象时,视图是Remapped,修改为M0,视图是M0,不需要处理,新建对象时,视图地址设置为M0
这样在并发标记阶段,如果新对象和老对象被触碰到后都会变为M0,将他们加入活跃对象信息表,其他的对象就可以安全的删除了
并发转移阶段(只转移活跃对象)
- GC线程发现对象视图M0,改为Remapped,对象Remapped,无需处理
- 应用线程发现对象在活跃信息表中,视图为Remapped,说明已经被处理,视图为M0改为Remapped,对象不在活跃信息表中的无需处理
染色指针
ZGC 则采用 Colored Pointer 来实现轻量级的 Read Barrier
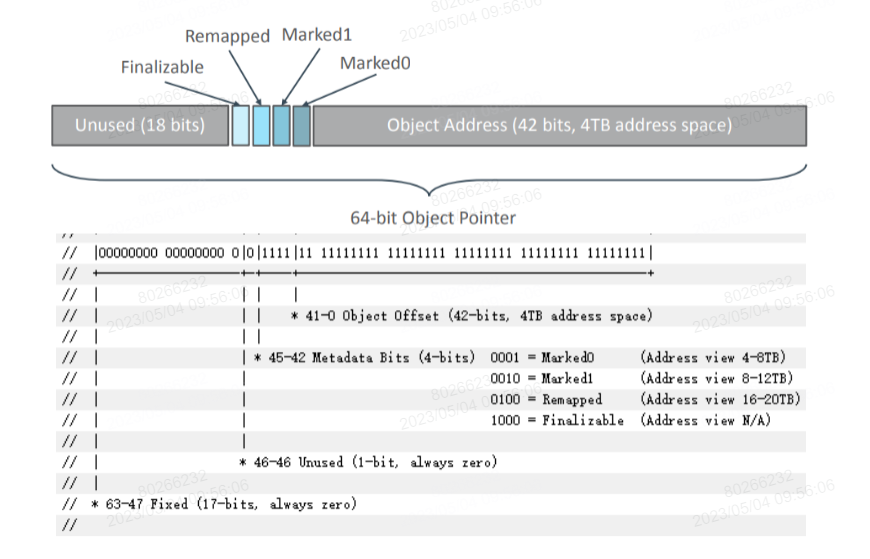
从指针中拿出高4bit来指示不同的处理状态
- Mark0/1 表明该对象指针是否被标记,区分前后不同的两次GC
- Remapped 表示当前对象指针是否已经调整为搬移之后的对象指针
- Finalizable 主要是为 Finalizable 对象服务,用来表示该对象指针是否仅经 Finalize 对象标记,主要供 Mark 阶段和弱引用处理阶段使用
Java线程在Runtime可以感知到3中状态
- Remapped 状态、Mark1 状态、Mark0 状态
为了使得这几种不同的状态(不同值的指针),指向同一份对象,ZGC的多视图映射由此而来,利用染色指针和多视图技术,ZGC不需要在对象头上记录GC分代信息,如G1将对象在哪个代记录到了对象头,每次需要修改对象的GC信息都需要进行一次内存访问,而ZGC只需要修改指针就能达到一样的效果,避免了频繁的内存访问,这也是它快的原因之一。
读屏障
GC线程和应用线程是并发执行的,所以存在应用线程去A对象内部的引用所指向的对象B的时候,这个对象B正在被GC线程移动或者其他操作,加上读屏障之后,应用线程会去探测对象B是否被GC线程操作,然后等待操作完成再读取对象,确保数据的准确性。
(CMS\G1采用的是写屏障)

读屏障是JVM向应用代码插入一小段代码的技术,相当于字节码注入。当应用线程从堆中读取对象引用时,就会执行一段代码,对象的读操作一般多于写操作,因此读屏障技术也不可避免的增加了一些开销。
主要改造点涉及的性能影响
- Read barrier 的开销
- JIT 方法的 entry barrier 开销 ZGC 对每个 JIT 代码都生成 nmethod entry barrier,会对 JIT 方法产生轻微的性能损失。
- Frame barrier 开销
- 其他 Runtime 改造产生的锁结构带来的开销。
- ZGC 中大部分的 GC 工作放在并发阶段,因此并发阶段 GC 线程和 Java 业务线程抢占 CPU,导致的对业务线程的抢占开销。
ZGC为了降低STW,采用的措施是极致的并发化改造,以轻微的性能顺序换取最低的停顿影响。
触发时机
相比于CMS和G1的GC触发机制,ZGC的GC触发机制有很大不同。ZGC的核心特点是并发,GC过程中一直有新的对象产生。如何保证在GC完成之前,新产生的对象不会将堆占满,是ZGC参数调优的第一大目标。因为在ZGC中,当垃圾来不及回收将堆占满时,会导致正在运行的线程停顿,持续时间可能长达秒级之久。
ZGC有多种GC触发机制,总结如下:
阻塞内存分配请求触发:当垃圾来不及回收,垃圾将堆占满时,会导致部分线程阻塞。我们应当避免出现这种触发方式。日志中关键字是“Allocation Stall”。
基于分配速率的自适应算法:最主要的GC触发方式,其算法原理可简单描述为”ZGC根据近期的对象分配速率以及GC时间,计算出当内存占用达到什么阈值时触发下一次GC”。自适应算法的详细理论可参考彭成寒《新一代垃圾回收器ZGC设计与实现》一书中的内容。通过ZAllocationSpikeTolerance参数控制阈值大小,该参数默认2,数值越大,越早的触发GC。我们通过调整此参数解决了一些问题。日志中关键字是“Allocation Rate”。
基于固定时间间隔:通过ZCollectionInterval控制,适合应对突增流量场景。流量平稳变化时,自适应算法可能在堆使用率达到95%以上才触发GC。流量突增时,自适应算法触发的时机可能会过晚,导致部分线程阻塞。我们通过调整此参数解决流量突增场景的问题,比如定时活动、秒杀等场景。日志中关键字是“Timer”。
主动触发规则:类似于固定间隔规则,但时间间隔不固定,是ZGC自行算出来的时机,我们的服务因为已经加了基于固定时间间隔的触发机制,所以通过-ZProactive参数将该功能关闭,以免GC频繁,影响服务可用性。 日志中关键字是“Proactive”。
预热规则:服务刚启动时出现,一般不需要关注。日志中关键字是“Warmup”。
外部触发:代码中显式调用System.gc()触发。 日志中关键字是“System.gc()”。
元数据分配触发:元数据区不足时导致,一般不需要关注。 日志中关键字是“Metadata GC Threshold”。
https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html
调优
充足的内存下即大堆场景,ZGC 在各类 Benchmark 中能够超过 G1 大约 5%到 20%,而在小堆情况下,则要低于 G1 大约 10%
建议以下场景使用ZGC
- 超大堆应用,因为超大堆一旦发生Full GC,停顿会很久
- 高SLA需求应用,如对P999时限要求的实时或软实时应用
ZGC 之美不仅在于其超低的 STW 停顿,也在于其参数的简单,绝大部分生产场景都可以自适应,主要调优参数
- 堆大小:Xmx
- GC 触发时机:ZAllocationSpikeTolerance, ZCollectionInterval
- GC 线程:ParallelGCThreads, ConcGCThreads。ParallelGCThreads 是设置 STW 任务的 GC 线程数目,默认为 CPU 个数的 60%;ConcGCThreads 是并发阶段 GC 线程的数目,默认为 CPU 个数的 12.5%
ZGC 参数
-Xms10G -Xmx10G
-XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
-XX:ConcGCThreads=2 -XX:ParallelGCThreads=6
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/opt/logs/logs/gc-%t.log:time,tid,tags:filecount=5,filesize=50m
RSS 内存异常现象
Linux 统计进程 RSS 内存占用的算法是比较脆弱的,这种多映射的方式并没有考虑完整,因此根据当前 Linux 采用大页和小页时,其统计的开启 ZGC 的 Java 进程的内存表现是不同的。在内核使用小页的 Linux 版本上,这种三映射的同一块物理内存会被 linux 的 RSS 占用算法统计 3 次,因此通常可以看到使用 ZGC 的 Java 进程的 RSS 内存膨胀了三倍左右,但是实际占用只有统计数据的三分之一,会对运维或者其他业务造成一定的困扰
共享内存调整
mmap 节点上限调整
参考文章:https://www.infoq.cn/article/suthxzwaoeijigdp11bj
https://developer.aliyun.com/article/1084638
https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html
https://tech.meituan.com/2016/09/23/g1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号