spark load data from mysql
code first
本机通过spark-shell.cmd启动一个spark进程
SparkSession spark = SparkSession.builder().appName("Simple Application").master("local[2]").getOrCreate();
Map<String, String> map = new HashMap<>();
map.put("url","jdbc:mysql:xxx");
map.put("user", "user");
map.put("password", "pass");
String tableName = "table";
map.put("dbtable", tableName);
map.put("driver", "com.mysql.jdbc.Driver");
String lowerBound = 1 + ""; //低界限
String upperBound = 10000 + ""; //高界限
map.put("fetchsize", "100000"); //实例和mysql服务端单次拉取行数,拉取后才能执行rs.next()
map.put("numPartitions", "50"); //50个分区区间,将以范围[lowerBound,upperBound]划分成50个分区,每个分区执行一次查询
map.put("partitionColumn", "id"); //分区条件列
System.out.println("tableName:" + tableName + ", lowerBound:"+lowerBound+", upperBound:"+upperBound);
map.put("lowerBound", lowerBound);
map.put("upperBound", upperBound);
Dataset dataset = spark.read().format("jdbc").options(map).load(); //transform操作
dataset.registerTempTable("tmp__");
Dataset<Row> ds = spark.sql("select * from tmp__"); //transform操作
ds.cache().show(); //action,触发sql真正执行
执行到show时,任务开始真正执行,此时,我们单机debug,来跟踪partitionColumn的最终实现方式
debug类
org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation.buildScan
此时parts为size=50的分区列表
override def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row] = {
// Rely on a type erasure hack to pass RDD[InternalRow] back as RDD[Row]
JDBCRDD.scanTable(
sparkSession.sparkContext,
schema,
requiredColumns,
filters,
parts,
jdbcOptions).asInstanceOf[RDD[Row]]
}
单个分区内的whereClause值
whereCluase="id < 21 or id is null"

继续往下断点,到单个part的执行逻辑,此时代码应该是在Executor中的某个task线程中
org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute
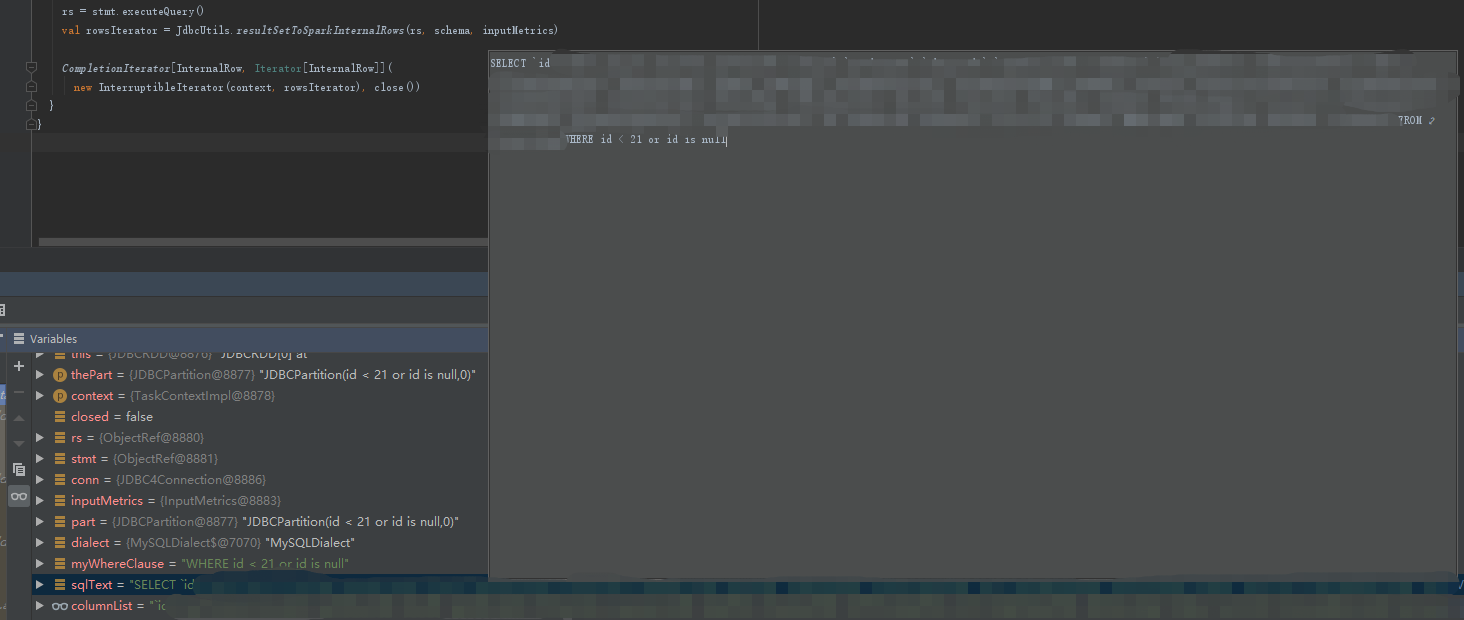
val myWhereClause = getWhereClause(part)
val sqlText = s"SELECT $columnList FROM ${options.table} $myWhereClause"
stmt = conn.prepareStatement(sqlText,
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)
stmt.setFetchSize(options.fetchSize)
rs = stmt.executeQuery()
val rowsIterator = JdbcUtils.resultSetToSparkInternalRows(rs, schema, inputMetrics)
CompletionIterator[InternalRow, Iterator[InternalRow]](
new InterruptibleIterator(context, rowsIterator), close())
此时
myWhereClause=WHERE id < 21 or id is null
最终的sql语句
sqlText=SELECT id,xx FROM tablea WHERE id < 21 or id is null
所有part都会经过compute
Executor执行完任务后,将信息发送回Driver
Executor: Finished task 7.0 in stage 2.0 (TID 12). 1836 bytes result sent to driver
总结
- numPartitions、partitionColumn、lowerBound、upperBound结合后,spark将生成很多个parts,每个part对应一个查询whereClause,最终查询数据将分成numPartitions个任务来拉取数据,因此,partitionColumn必须是索引列,否则,效率将大大降低
- 自动获取table schema,程序会执行类型select * from tablea where 1=0 来获取字段及类型
- lowerBound,upperBound仅用来生成parts区间,最终生成的sql中,不会使用它们来作为数据范围的最小或最大值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号