python爬虫—学习笔记-4
课堂内容:
- 删除原导出文件的venv,pycham打开此文夹,重新创建本地虚拟编译器。
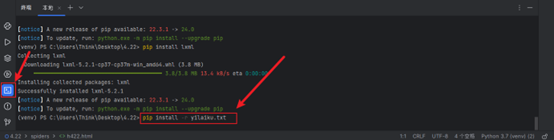
- 安装依赖库,打开pycham终端输入pip install -r yilaiku.txt,安装依赖库中的库。
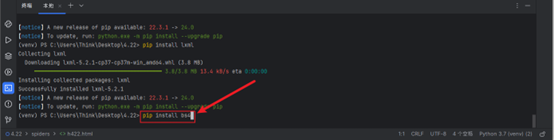
- 继续安装bs4、lxml库,命令为:pip install bs4 和 pip install lxml。
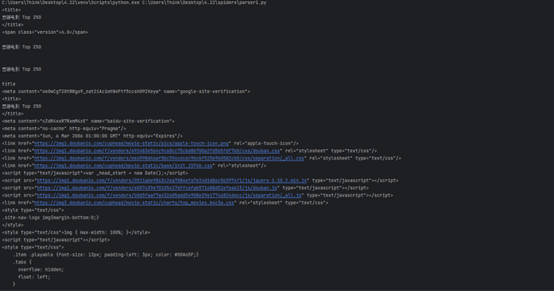
- 安装好后,pycham来到spiders目录下,新建Python项目“spider422”,爬取豆瓣250的首页HTML;
代码为:
import requests
import re
url="https://movie.douban.com/top250"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
response=requests.get(url,headers=headers)
with open('h422.html',mode='w',encoding='utf-8')as f:
f.write(response.text)
通过request识别网页信息,获取相应信息,最后写入“h422.html”文件中
- 通过bs4库解析网页中的相关信息。
代码如下:
也可用import bs4直接导入库
from bs4 import BeautifulSoup as bs //导入bs4库中的BeautifulSoup并命名为bs
with open('h422.html',mode='r',encoding='utf-8') as f:
text =f.read() //打开h422.html并存入text中
soup = bs(text,"html.parser") //通过标准的html库解析
#获取标签
# print(soup.title)
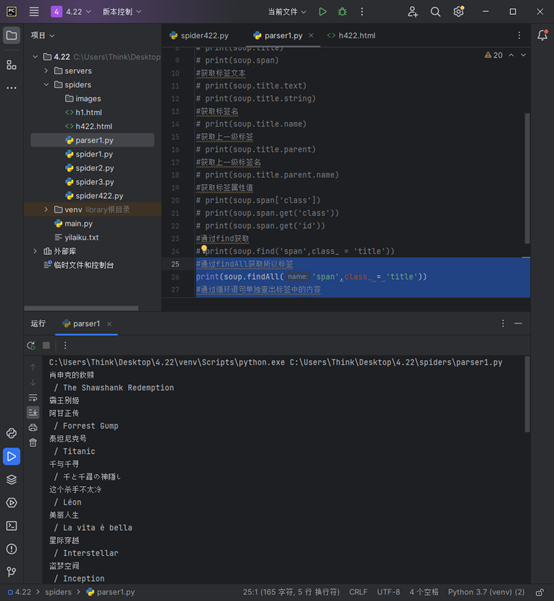
# print(soup.span)
#获取标签文本
# print(soup.title.text)
# print(soup.title.string)
#获取标签名
# print(soup.title.name)
#获取上一级标签
# print(soup.title.parent)
#获取上一级标签名
# print(soup.title.parent.name)
#获取标签属性值
# print(soup.span['class'])
# print(soup.span.get('class'))
# print(soup.span.get('id'))
#通过find获取
print(soup.find('span', class_='title')) //通过find方式获取
6.获取所以标签的内容
#通过findAll获取所以标签
print(soup.findAll('span',class_ = 'title'))
#通过循环语句单独查出标签中的内容
items = soup.findAll('span',class_ = 'title')
for item in items:
print(item.text)
7.通过select来筛选需要的标签以及层级关系筛选。
应用select参数来筛选要的东西
# print(soup.select('span'))
#单独应用select层级筛选
# print(soup.select('span.title'))
# print(soup.select('span#icp'))
print(soup.select('div > p.pl'))
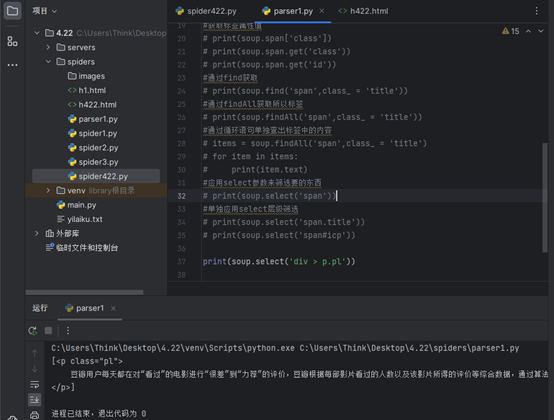
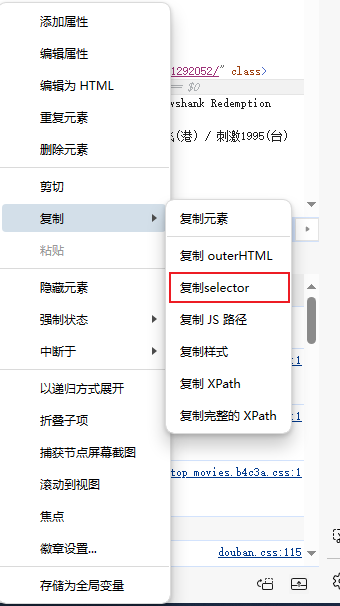
当然网页中F12可以直接复制select元素,就可以应用select层级筛选
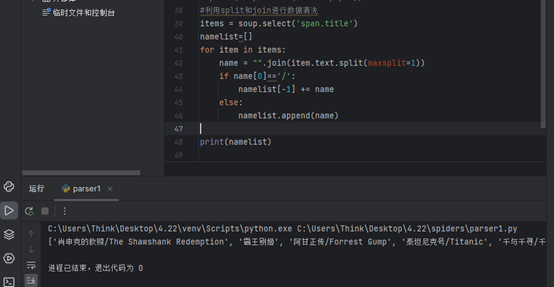
8.数据清洗,运用splist和join进行数据清洗。
#利用split和join进行数据清洗
items = soup.select('span.title') //获取数据
namelist=[]
for item in items:
name = "".join(item.text.split(maxsplit=1)) //以第一个空格为删除条件删除后连接两个数据
if name[0]=='/':
namelist[-1] += name
else:
namelist.append(name)
print(namelist)
附加知识:
Pycham****更换软件包镜像源:
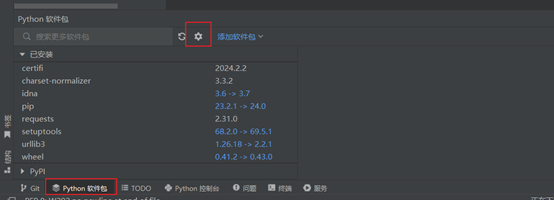
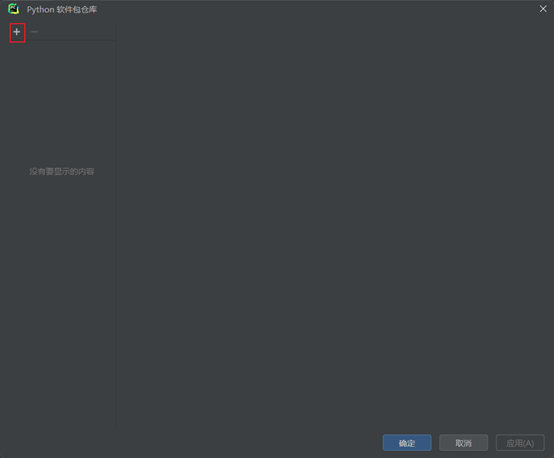
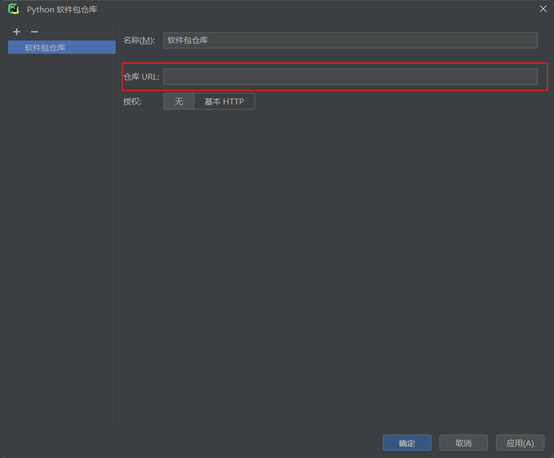
清华: https://pypi.tuna.tsinghua.edu.cn/simple
豆瓣: http://pypi.douban.com/simple/
阿里: http://mirrors.aliyun.com/pypi/simple/
Beautifulsoup的各种用法:
beautifulsoup:HTML或XML文件数据解析库
安装bs4,lxml(有的需要安装)
导入:from bs4 import BeautifulSoup as bs
解析指定内容:soup = beautifulsoup(解析内容,解析器)
解析器:
\1. python 标准库:‘html.parser':
2.lxml:
with open('h1.html',mode='r',encoding='utf-8') as f:
text = f.read()
# 定义解析对象:
soup = bs(text,'html.parser')
#标签:
print(soup.title)
print(soup.span) #输出第一个span标签
#标签文本
print(soup.title.text)
或者:
print(soup.title.string)
#标签名称:
print(soup.title.name)
#父级标签
print(soup.title.parent)
#父级标签名称:
print(soup.title.parent.name)
#第一个span 标签的class属性值:
soup.span['class']
soup.span.get('class')
soup.span.get('id') #没有则返回none
#指定属性值的标签:
print(soup.find('span', class_='title')) #注:class因为是关键字,要加下划线
print(soup.find('span', {'class': 'title'}))
#所有相同属性名标签的获取:
print(soup.findAll('span', class_='title'))
print(soup.findAll('span', {'class': 'title'}))
print(soup.findAll('span',attrs={'class':'title'}))
数据清洗:
split() 方法语法:str.split(str="",maxsplit=string.count(str))[n]
功能:用指定字符分割字符串,分割结果为列表,默认分割符为空格
join函数语法:'sep'.join(sep_object),
功能:连接任意数量的字符串(包括要连接的元素字符串、元组、列表、字典),用新的目标分隔符连接,返回新的字符串。
namelist=[]
for i in soup.findAll('span', {'class': 'title'}):
# 字符串处理:(数据清洗)
name="".join(i.text.split())
if name[0]=='/':
namelist[-1] += name
else:
namelist.append(name)
print(namelist)
获取图片url:
for i in soup.findAll('img'):
print(i.get('src'))
常用的字符处理函数(方法):
strip():删除字符串开头和结尾的空格或或指定字符
格式:str.strip([chars]),不指定参数时删除开头或结尾处的空格
字符串拼接:+
替换字符:replace():
格式:str.replace(old, new[, max])
大小写转换方法:lower,upper()
len( )函数计算字符串的长度
capitalize( )方法将字符串首字母大写
find()方法:查找指定字符(串)的起始位置,找不到返回-1
startswith( )方法判断字符串的开头字符(串)
endswith( )方法判断字符串的结尾字符(串)
isdigit( )方法判断字符串是否由数字组成
isalpha( )方法判断字符串是否由字母组成
isalnum( )方法判断字符串是否由数字和字母组成
select 选择器
用于选取特定标签,选取规则依赖于css,所有叫css选择器
# select 选择器
# 所有span标签
# print(soup.select('span'))
#特定类名的标签
# print(soup.select('.title'))
# # 指定id的标签
# print(soup.select('#dale_movie_top250_bottom_right'))
# 组合
# items=soup.select('span.title')
#string,text:查看文本,attrs查看所有属性,查看某个属性:attrs['class']
# for item in items:
# print(item.string,item.text,item.attrs)
# print('---------------------------------------')
# print(soup.select('div#footer'))
# 递进选择
print(soup.select('div > p.pl'))#直接父子关系
print(soup.select('div.info span.title'))#不直接(用空格)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号