
本文介绍如何监控k8s服务层event及报警
问题
应用或服务部署到k8s集群时,首先会经过k8s的调度,这个过程可能会出现一些问题,比如 volume 无法正常挂载,没有足够的资源部署服务,服务异常退出等。
如何及时了解这些问题,保证服务正常运行?
监控层级
监控k8s集群,大致分为下面3个层级:
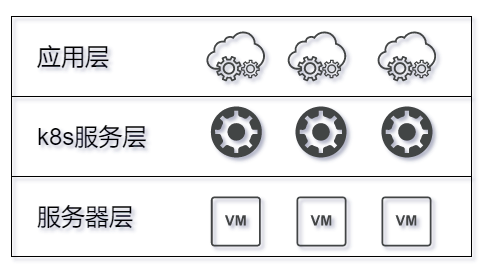
应用或服务部署到k8s集群时,k8s服务层会产生一系列的event事件,通过监控这些事件的类型,可以掌握服务状况
k8s event
k8s event是一种资源类型,当其他资源具有状态更改,错误或应向系统广播的其他消息时,会自动创建该资源类型。在调试Kubernetes集群中的问题时,它们是重要的渠道。
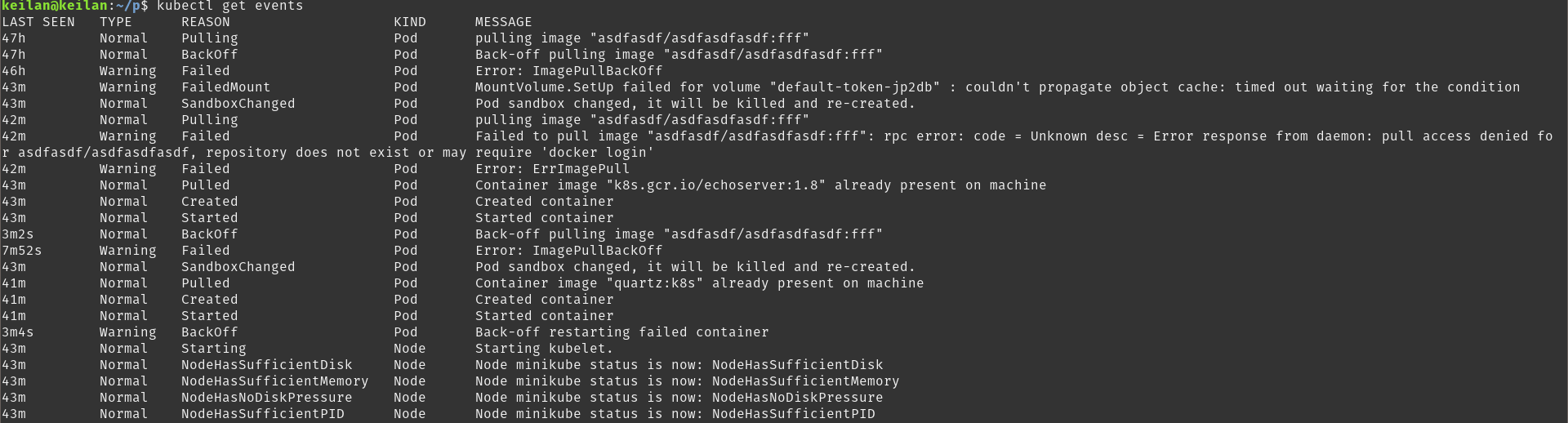
通过 kubectl get events 指令,可以看到集群当前的部分事件列表:
event源代码也可以看到有哪些event类型
type=Normal的event相当于应用层的 log.Info,比较有用的信息是 type=Warning的,可以加上过滤条件:
kubectl get events --field-selector type=Warning
可以通过Reason栏位看到更详细的信息,通过此栏位,可以根据我们服务的实际情况,来筛选出需要监控和报警的event
event 收集
使用kubernetes-event-exporter,可以方便的在k8s集群部署event收集服务并将其发送到 elasticsearch。
需要注意的是,目前该工具使用的是 elasticsearch 7.x 的api,并不兼容以下的版本。
使用 grafana 监控 event 和设定报警
在grafana中设定好 elasticsearch 的 source,然后在dashboard中建立Graph 图表(Grafana的Alert功能目前只支持 Graph 图表)。
可以通过下面两个指标来设定报警:
- type.keyword
- reason.keyword
type
部分值:
- Warning
- Normal
Warning基本上就是k8s的调度没有按照预期执行,只要有该类型的event,就可以发出alert
reason
部分值:
- UPDATE
- SuccessfulDelete
- SuccessfulCreate
- Started
- Scheduled
- ScalingReplicaSet
- SawCompletedJob
- Pulling
- Pulled
- Killing
- FailedMount
- Failed
- Created
- BackOff
可以根据服务的场景来确定需要alert的reason
Alert设定
- 在Panel中添加query:_index:[index-name] AND type:Warning
- Visualization选择graph
- Alert
- Rule设定规则,Evaluate every 1m For 2m,表示每1分钟计算一次,第3次计算仍然满足报警条件,则发出Alert
- Conditions设定报警条件,WHEN avg () OF query (A, 5m, now) IS ABOVE 0,表示检查5分钟内是否有Warning的Event
- Notifications设定Alert渠道,可以用webhook来发送消息到Server酱,调试webhook可以用在线工具webhook.site
