
my project-----信用评分预备
1.信用评分场景
贷前审核申请评分:运营商信息、电商信息、个人信息、央行征信信息
贷后监控行为评分:还款行为、消费行为
2.开发流程
确定场景(贷款前还是贷款后)、人群、产品
数据准备与预处理:选取数据、清洗数据、特征工程
模型构建与参数估计
模型评估和性能测试
模型验证与审计:验证建模的合理性(不能和开发人员同一批人)
模型上线
持续监控并调优
3.开发必备模型
逻辑回归、决策树(对数据质量的要求低、对异常值、对缺失值也可以处理)
组合模型(怎么集成模型?优点是不容易过拟合、准确度高)
4.特征构造
从已有的字段中提炼出有价值的、可用的信息(基于对业务的理解,找到对因变量有影响的所有变量)
特征可用吗?获取难度、覆盖率、准确率
特征的构造方法

过去一段时间-----时间切片-----太短不稳定、太长效果不好

5.数据集中度:一批训练样本中,学历为本科的样本样本占全部样本的90%。
此时分情况讨论:
本科和非本科,因变量之间没有显著差别,直接把本科这个字段删除
本科和非本科,少数值的样本中坏样本率更低,比如非本科的群体坏样本更低。
如果这个字段划分出的群体,坏样本率更高,那这个地段就是好的字段
6.数据预处理
6.1数据缺失(两类缺失情况字段和样本、三种处理方式舍弃补缺视为特殊值、两种数据类型连续和离散)
字段缺失、样本缺失
处理方法:
舍弃
补缺(均值[完全随机缺失]、众数和抽样法[分类变量]、回归法[随机缺失,和某个变量有相关性]、插值法[时间序列变化])
视为特殊值:缺失样本的坏样本率更高,视为一种特殊值,作为一个特殊的分箱
6.2异常值(LR不能容忍异常值、缺失值、多重共线性)
先判断、再处理
判断:分位点法、聚类法
处理:删除、用正常值替换、但有时异常值非常大的样本是需要警惕的,例如征信查询次数过大
6.3格式统一
6.4查看多重共线性、可以计算相关系数、VIF值、分类变量如何查看相关性?
7.特征分箱
- 逻辑回归特征必须是数值型的,分类变量要进行编码。
- 为了使评分模型的稳定性,需要分箱。收入由6000涨到6200,这时的信用评分最好不要发生变化
- 如果使用哑变量,会导致变量膨胀。取值个数较多的类别型变量,也可以进行合并(如北上广合并为一个)
- 分箱要保证有序性:比如学历。
- 每个箱子的占比不要相差太大,一般不要低于5%
- 分箱要体现目标变量的趋势,如单调、U型等
- 分箱的个数适中。7个以内
- 分箱的优点:稳定、便于缺失值和异常值的处理、解决了尺度问题(如收入的单位是万、还款率是%)
- 模型代入之前要做单变量和多变量的分析
- 分箱方法:
- 有监督:卡方分箱法、决策树分箱(利用了目标变量的信息)
- 无监督:等距、等频、聚类
卡方分箱:就是做卡方检验
chimerge分箱法:


出现非单调性时:
1.继续合并箱子,缩小箱子数量
2.解决了单调性问题后,判断分箱的均匀性(16.)
8.WOE编码
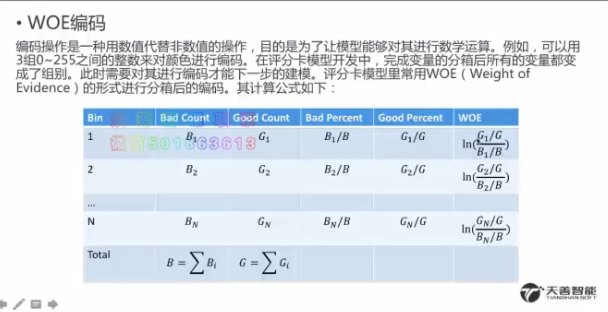

WOE就是本箱的log odds和全体的log odds的差值,即每一箱中的相对全体的log odds的超出值
每个箱子都必须同时包含好坏样本,才能使WOE值有意义
对于多类别标签的情况,多分类情况时无法计算WOE值
9.特征信息值 information value(随机森林、GBDT模型等也可以帮助判断变量的主要性)
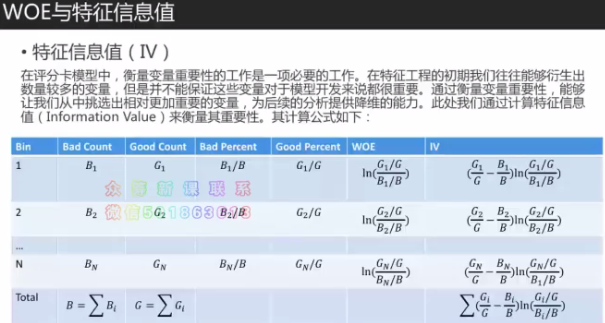





固定第一个变量,删除相关性达到0.7-0.9的变量

VIF=10是一个宽松的标准,如果高于10,一定是存在多重共线性的
10.逻辑回归参数估计:MLE和损失函数
似然函数:每个样本对应的概率密度函数 进行 相乘
让似然函数最大化,得到的样本是概率最大的样本
logit模型极大似然估计无法得到解析解,使用数值求解的方法,例如常用的梯度上升法。

LR优点:可解释性高、软分类给出的概率
LR不足:对变量要求高,需要对非数值变量进行编码、需要对缺失值做处理、对异常值做处理、变量尺度差异大时需要进行归一化、不能忍受多重共线性、需要进行变量挑选或者加上正则项
11.基于LR模型的信用风险评分
入模的变量要求:
变量间不存在较强的线性相关性和多重共线性
变量具有显著性(要检验单个变量的P值)
变量要具有合理的业务含义(系数正负号要合理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号