
ElasticSearch结构
Elasticsearch是一种文档性存储结构,由上到下依次可分为:
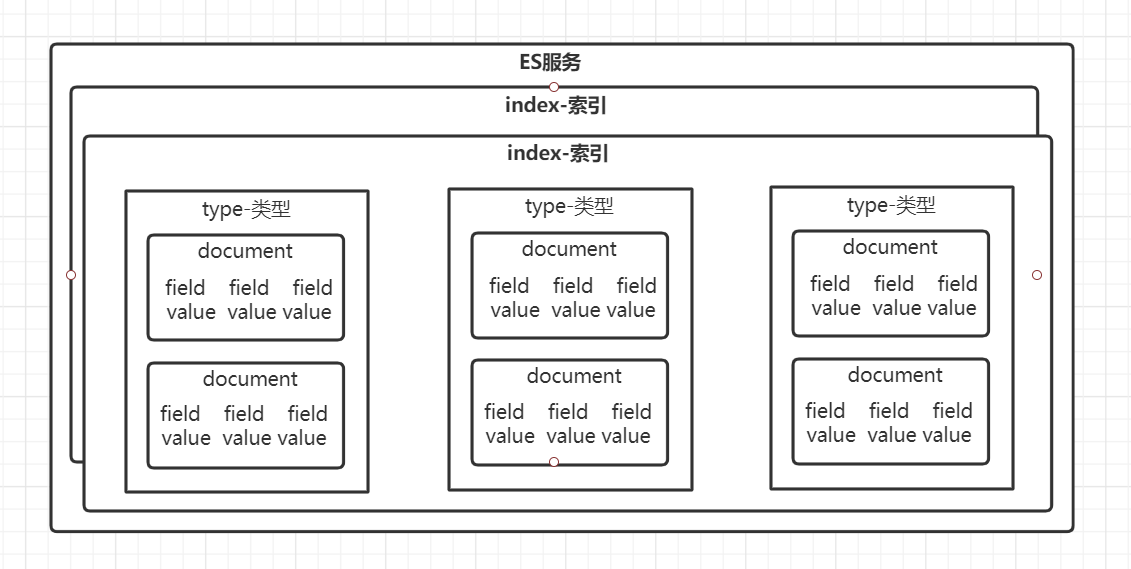
cluster(集群)→node(节点)→shard(分片)/replica(副本)→index(索引)→type(类型)→document(文档)→field(属性)
一个Elasticsearch集群可以 包含多个节点,每个节点包含多个分片,每个分片包含多个索引 ,相应的每个索引可以包含多个类型 。 这些不同的类型存储着多个文档 ,每个文档又有 多个属性 。
索引 这个词在 Elasticsearch 语境中有多种含义, 这里有必要做一些说明:
索引(名词):
如前所述,一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的地方。 索引 (index) 的复数词为 indices 或 indexes 。
索引(动词):
索引一个文档 就是存储一个文档到一个 索引 (名词)中以便被检索和查询。这非常类似于 SQL 语句中的
INSERT关键词,除了文档已存在时,新文档会替换旧文档情况之外。倒排索引:
关系型数据库通过增加一个 索引 比如一个 B树(B-tree)索引 到指定的列上,以便提升数据检索速度。Elasticsearch 和 Lucene 使用了一个叫做 倒排索引 的结构来达到相同的目的。
-
集群
ES可以作为一个独立的单个搜索服务器,不过为了处理大数据集,实现容错和高可用,ES可以运行在多台相互合作的服务器上。这些服务器的集合称为集群。
-
节点
运行了单个实例的ES主机称为节点,他是集群的一个成员,可以参与数据存储、集群索引及搜索工作。节点通过为其配置的集群名称来确定加入的集群。
-
分片
ES的分片机制,可以将一个索引内部的数据分布的存储在多个节点上。它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每个物理的Lucene索引称为分片。
这样可以把一个大的索引拆分成多分,分不到不同的节点上。减低单个服务器的压力。同时,构成分布式搜索,提高整体检索的效率。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
-
副本
副本是一个分片的精确复制,每个分片可以有多个副本。副本的作用一是提高系统的容错性,当某个分片损坏或者丢失时,可以从副本中回复。二是提高ES的查询效率,ES会自动对搜索请求进行负载均衡。
数据架构
-
索引
ES将数据存储于索引中,索引时具有类似特性的文档的集合。
索引相当于关系型数据库中的数据库。
-
类型
类型是索引内部的逻辑分区,一个索引内部可以定义一个或多个类型。
类型可类比于关系型数据库中的表。
PS:ES5.0中,一个索引中可定义多个类型;ES6.0以上只能定义一个;ES7.0中开始弃用,但一个索引中还是可以定义一个类型。ES8.0将完全删除类型。
-
文档
文档是Lucene索引和搜索的原子单位,它是包含一个或多个域的容器,基于JSON格式进行表示。
可类比于关系型数据库中的行。
-
属性
属性是对文档中每个值的描述。
相当于关系行数据库中的列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号