

软件工程个人作业4----移动端疫情展示
1.要求
求开发一款移动端的全世界疫情实时查询系统。
要求将前两周的项目合并为一个完整的项目。
采用统一的数据库。(建议MySQL数据库)
实现从数据采集、数据存储、数据查询(WEB端和移动端)一体全世界实时疫情查询系统。
以本机数据库为服务器端,web端和移动端连接远程数据库实现数据共享,要求数据库表格式统一化。
查询显示当前最新时间的数据,可以查询任一时间任一地点的数据。该系统要求在服务器端发布,可以通过IP地址访问。
2.思路分析
首先是在前两阶段已经完成的echarts可视化、利用PYTHON爬取疫情数据基础上来进行调用与完善。大致思想是在Android Studio上完成交互去调用
MYSQL数据库,并完成对数据库的查询。
3.时间表
|
阶段 |
时间 |
问题 |
备注 |
|
PYTHON爬取世界疫情信息,存入mysql |
1h |
|
改动一下上一次代码即可 |
|
android连接mysql |
8h |
初次使用android连接mysql,并通过ip地址访问 |
纯网上学习,开始未找到合适教程,耽误很长时间 |
|
android读取,查询,显示疫情信息 |
6h |
空指针 |
编写程序,读取查询数据库 |
4.截图:

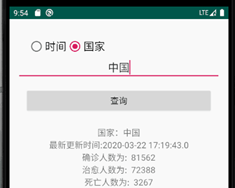
5.代码:
import requests import json from pymysql import * import requests from retrying import retry headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Mobile Safari/537.36" ,"Referer": "https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1"} def _parse_url(url): response = requests.get(url,headers=headers,timeout=3) #3秒之后返回 return response.content.decode() def parse_url(url): try: html_str = _parse_url(url) except: html_str = None return html_str class yiqing: f = 0 url="https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=316765429316" def getContent_list(self,html_str): dict_data = json.loads(html_str) #各省的数据 content_list = dict_data["data"] return content_list def saveContent_list(self,i): # 打开数据库连接(ip/数据库用户名/登录密码/数据库名) con = connect("localhost", "root", "root", "text") # 使用 cursor() 方法创建一个游标对象 cursor cursors = con.cursor() # 使用 execute() 方法执行 SQL 查询 返回的是你影响的行数 if self.f ==0 : cursors.execute("delete from citys") cursors.execute("delete from provinces") self.f = self.f+1 row = cursors.execute("insert into provinces values(%s,%s,%s,%s,%s,%s,%s,%s)", (i.get('id'),i.get('name'),i.get('total').get('confirm'), i.get('total').get('suspect'),i.get('total').get('heal'), i.get('total').get('dead'),i.get('total').get('severe'), i.get('lastUpdateTime'))) province = i.get('name') for j in i.get('children'): row = cursors.execute("insert into citys (id,name,confirm,suspect,heal,dead,severe,lastUpdateTime,province) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)", (j.get('id'),j.get('name'),j.get('total').get('confirm'), j.get('total').get('suspect'),j.get('total').get('heal'), j.get('total').get('dead'),j.get('total').get('severe'), j.get('lastUpdateTime'),province)) con.commit()#提交事务 con.close()# 关闭数据库连接 def run(self): #实现主要逻辑 #请求数据 html_str = parse_url(self.url) #获取数据 content_list = self.getContent_list(html_str) values = content_list["areaTree"][0]["children"] for i in values: self.saveContent_list(i) if __name__ == '__main__': yq = yiqing() yq.run() print('爬取,存储成功!!') python爬取其他各国数据 import requests import json from pymysql import * import requests from retrying import retry headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Mobile Safari/537.36" ,"Referer": "https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1"} def _parse_url(url): response = requests.get(url,headers=headers,timeout=3) #3秒之后返回 return response.content.decode() def parse_url(url): try: html_str = _parse_url(url) except: html_str = None return html_str class yiqing: f = 0 url="https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=316765429316" def getContent_list(self,html_str): dict_data = json.loads(html_str) #各省的数据 content_list = dict_data["data"] return content_list def saveContent_list(self,i): # 打开数据库连接(ip/数据库用户名/登录密码/数据库名) con = connect("localhost", "root", "root", "text") # 使用 cursor() 方法创建一个游标对象 cursor cursors = con.cursor() # 使用 execute() 方法执行 SQL 查询 返回的是你影响的行数 if self.f ==0 : cursors.execute("delete from world") self.f = self.f+1 row = cursors.execute("insert into world values(%s,%s,%s,%s,%s,%s,%s,%s)", (i.get('id'),i.get('name'),i.get('total').get('confirm'), i.get('total').get('suspect'),i.get('total').get('heal'), i.get('total').get('dead'),i.get('total').get('severe'), i.get('lastUpdateTime'))) con.commit()#提交事务 con.close()# 关闭数据库连接 def run(self): #实现主要逻辑 #请求数据 html_str = parse_url(self.url) #获取数据 content_list = self.getContent_list(html_str) values = content_list["areaTree"] for i in values: self.saveContent_list(i) if __name__ == '__main__': yq = yiqing() yq.run() print('爬取,存储成功!!')

