Set与二分法效率
前言
stl中有set用于匹配是否存在,内部利用rbtree机制,是一种高效算法
但在c语言环境下,stl是不能直接使用,因此需要用其他算法来代替,二分法也是一种快速排序方法,代码逻辑也比较简单。
由于项目中,会碰到协议的筛选,例如跟进协议ID筛选,然后需要继续处理;
此时由于前端输入是广播数据,往往大部分数据都是"不需要处理"的,如果不进行优化,此处效率的确低下.
本来没有这篇作业的,由于测试结果并不是set效率都高于二分法的
测试条件限制:
- 每次都是拿不存在此数组的数据进行比较(最差情况下)
- 最大数组长度为102,然后50,25,12 (实际项目中一般以20~30居多)
- 测试一轮是循环1000000次,目的是容易比较结果
- 测试环境为windows环境,CPU能力较高,时间仅用于判断趋势
- 测试时间结果,每次并不一样,但总在一点范围内
先看数据截图:
二分法数据测试
被测数组长度为 102
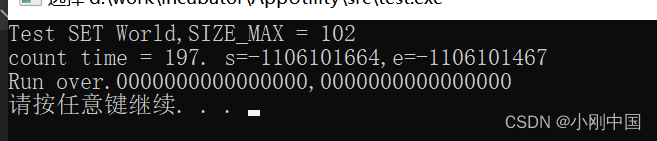
![]()
被测数组长度为 50
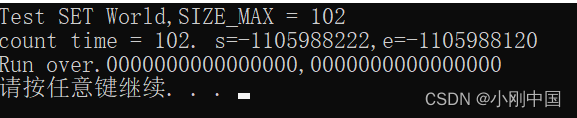
![]()
被测数组长度为 25
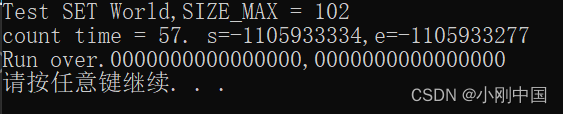
![]()
被测数组长度为 12
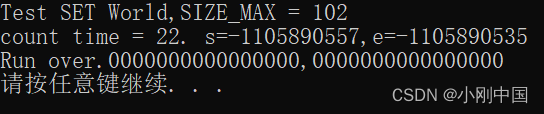
![]()
如果使用set
被测数组长度为 102

![]()
被测数组长度为 50
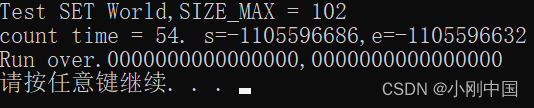
![]()
被测数组长度为 25
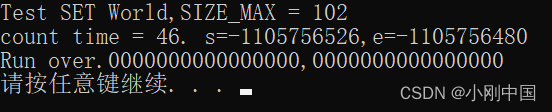
![]()
被测数组长度为 12
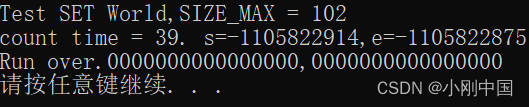
![]()
再来一张对比表格
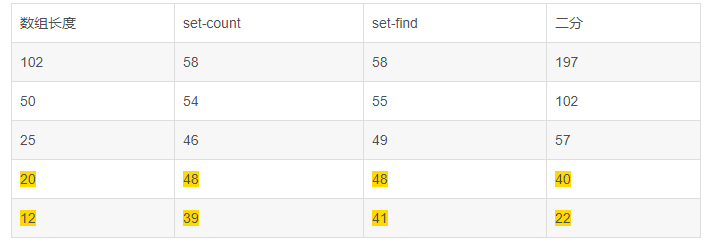
结论:
- 当数组本身比较少的时候(小于20),其实还是二分法比较快;也就是说如果本身就是小数组的时候,还不如用二分法。
- 数组成倍增加,二分法耗时也会接近成倍增加;而set明显优化好很多
- set适合数组比较大,而且随着数组越大,优势越明显
- 可能数组本身不大,且类型为基本类型,set使用count 与find去比较是否存储,几乎没有啥变化
满屏源代码,一把辐射泪,都云编程痴,谁解其中味!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号