视频一些基础知识整理
最近接收一个项目,用到视频的内容,简单点说,就将一端的视频采集下来,然后通过网络传输到另外一端并显示出来
采集设备不是IP摄像头,是USB摄像头,因此要涉及采集原始数据的知识
由于网络传输效率问题,因此必须采用一种合理的压缩方式,最容易想到是H264,实际上传MJPG也是可以的(效率低一些)
H264那么意味着要涉及编码、解码的问题
另外显示也是个问题,还好linux有framebuffer技术
以上思路,是可行的。
事实上,对于没有接触过视频方面知识的人而言,是提不出以下这些问题的:
- 那么USB摄像头采集下来的图像是什么格式的?
- 怎么设置USB采集的格式?
- 转换H264?
- H264怎么传输给对方?
- H264要转换成什么数据?怎么转换?
对于这些问题解决,如果都能够解决,我觉得对视频相关处理知识也就差不多了。
Q1:USB摄像头采集下来的图像是什么格式的?
可以看下USB摄像头使用说明书,一般常见如MJPG、YUV
MJPG是单帧压缩,可以理解压缩成一张张JPG的图片,我们知道JPG的图片要比无压缩bmp图片小很多,大概可以做到原先10分之一的大小。
但对于视频而言,每秒25帧的图片,就算jpg也是很大的,传输通道会压力很大,因此USB采集用MJPG格式的,往往是用于本机显示,或不具备H264压缩条件地方。
YUV是另外一种颜色表示,相对于前面MJPG(传统意义上RGB),这个是亮度与颜色,YUV的原理是把亮度与色度分离,研究证明,人眼对亮度的敏感超过色度。利用这个原理,可以把色度信息减少一点,人眼也无法查觉这一点。YUV三个字母中,其中”Y”表示明亮度(Lumina nce或Luma),也就是灰阶值;而”U”和”V”表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
YUV的出现本质上还是为了节省带宽,减少冗余信息的输出。同样也存在多种定义:YUV422 YUV444 YUV420 YUV411,数字越小说明带宽越小,目前主流的是422 以及 420 ,当然相互之间是可以转换的。大致可以看下图:
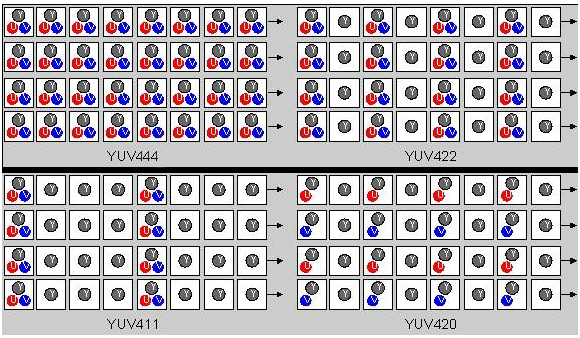
图中也明显发现,444的效率最低的,当然效果是最好的。一般采用比较多的是420 422
Q2:Linux下如何采集USB摄像头数据?
当前Linux版本,基本上都是支持的。那就是V4L2,这个应该纳入到Linux内核当中,只要未裁剪掉,应该都支持
V4L2 是专门为 linux 设备设计的一套视频框架,其主体框架在 linux 内核,可以理解为是整个 linux 系统上面的视频源捕获驱动框架。
这个库,怎么使用?网上资料很多,也不复杂,这里不啰嗦
大致流程:初始化结构体,申请空间 -> 绑定到USB设备(ioctl) -> 获取数据USB数据 然后该干嘛的干嘛
//设置分辨率与帧数
ret = v4l_capture_setup(enc, enc->src_picwidth, enc->src_picheight, enc->cmdl->fps); //开始取流 ret = v4l_start_capturing(); if (ret < 0) { return -1; } //获取摄像头数据 ret = v4l_get_capture_data(&v4l2_buf); if (ret < 0) { goto err2; } //获取V4L2摄像头数据 memcpy(inbuf,cap_buffers[v4l2_buf.index].start,cap_buffers[v4l2_buf.index].length); /////// if (src_scheme == PATH_V4L2) { v4l_put_capture_data(&v4l2_buf); }
为了后续H264压缩方便,往往USB采集的格式要使用YUV格式
对了,初始化的时候,还有告诉USB摄像头多少分辨率/帧数
带宽预算:(以800*600来考虑)
每张完整图片字节:x*y*3 =800*600*3 B = 1440000字节
每秒数据量:如果24帧,那么要*24 。24*1440000=34560000字节 ~= 32.9M
通过YUV422优化:可以节省1/3,最终大概=21.9M,是USB2.0上限了
如果USB摄像头是2.0的话,也就最多800*600*24 效果了。
否则:要么降帧数,要么降分辨率
这个也很重要,有时候硬件限制也是个麻烦事情。
另外,需要注意点:
由于USB2.0已经接近极限,因此对设备本身要求很高,
包括容易忽视连接线(延长线),这个如果不加屏蔽,不是双绞线的话,也会有问题的
Q3:采集数据需要H264压缩?
一般来说,需要GPU压缩或APU压缩,当然厉害一点设备,也可以采用FFmpeg来压缩(实践证明,这个在x86架构下还行,ARM不行)
是不是,我们经常用到的 “硬解码” “软解码”的概念 差不多
说下H264
据说我们人眼是每秒24帧,如果超过这个数,不会觉得“卡顿”,实际上如果超过12帧,也差不多很流畅了。基于这个理解,那么视频就好比每秒播放多少张图片,张数越高,效果越好,但也带来问题:数据量非常大。
但是,往往视频每帧之间(特别是连续的)变动就很少,比如我们的背景,往往几乎不变。这样如果有一种算法,可以算出哪些是变化,哪些是不变的,传输的时候就传变化的,那就可以大大节省带宽,效果也能达到原先效果
基于这个思路,H264就是干这个的,当然H264是一个标准。目前市场上主流还是H264,当然也有H265,本质上还是相差不大
为了更好理解H264,所以也定义一些知识:
H264压缩技术主要采用
了以下几种方法对视频数据进行压缩。包括:
(1) 帧内预测压缩:解决的是空域数据冗余问题。(就是独立帧,可以理解为单独一张图片,比如JPEG图片)
(2) 帧间预测压缩:(运动估计与补偿),解决的是时域数据冗余问题。(实际上就是增量压缩)
(3) 整数离散余弦变换(DCT):将空间上的相关性变为频域上无关的数据,然后进行量化。
(4) CABAC压缩。
经过压缩后的帧分为:I帧,P帧和B帧:
I帧:关键帧,采用帧内压缩技术。(数据量也是最大的)
P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧间压缩技术。
B帧:双向参考帧,在压缩时,它即参考前面的帧,又参考它后面的帧。采用帧间压缩技术。
由此可以理解:I帧是关键的,也是独立的,可以变成一个完整画面,但数据量也是最大的
B帧 P帧,都是基于I帧,单独B帧 P帧是不可能显示一个完整画面的,但一帧的数据量少,也是H264的精髓所在
那么如何安排I B P呢?
1. 感觉还是跟场景结合起来,H264运用最广的就是视频监控,视频监控有以下一些特点:
不变的数据大,变化数据少
一般需要网络传输,带宽越小越好
分辨率要求比较高
这样,我们I帧不用考虑太频繁,例如每隔50帧安排一个I帧(2s一帧),往往也足够了,也比较合理,再小下去提升也有限
BP可以多一点,其他24帧都是BP帧
2. 如果是行车记录仪或摄像机?
此时特点,变成动态比较多,带宽要求比较低。
此时可能也不需要H264了,直接MPEG压缩不香吗?
如果非得要H264,那么I帧考虑频繁点
另外,还有GOP概念,最终来说还是一组数据,这一组数据就是GOP
两个I帧之间是一个图像序列;一个图像序列中只有一个I帧。

这里也插入下一些实践知识:
如果I帧没有?会什么效果
绿屏
如果I帧长时间不更新?(前面收到过I帧,但过程中有段时间没有收到)
看图像实际变化,如果变化不大的,可能是局部花屏
如果变化比较大,花屏
如果变化很大,可能是绿屏
如果偶尔丢失B P帧?
分辨率足够的话,偶尔丢一下,感觉不出来的
如果长期丢失B P帧?
图像会跳帧(“卡”),I帧在,图像本身没有问题,但看起来很不连续。
虽然理解上算法不复杂,但是要CPU计算,也是很费资源的,
因此,H264也是考量压缩端计算能力,也考量解压端计算能力,好在目前主流CPU都是集成GPU,这部分工作可以交给GPU来完成
也就是说,如果方案采用的CPU本身就很弱,那就很麻烦,H264虽然你知道,但肯定不好实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号