
Scrapy爬虫框架入门
一、环境搭建
Scrapy是一个比较好的爬虫框架,本次,我们学习一下,使用Scrapy框架来创建一个爬虫项目,并通过一个简单的例子演示一下。
第一步:安装依赖。首先先保证已经安装了python,pip。然后使用pip进行一下依赖的安装,顺序为:
1、wheel 2、 lxml 3、PyOpenssl 4、 Pywin32 5、scrapy
安装命令为:比如安装sheel:pip install sheel
当然,肯定没有那么容易就能安装成功了啦,由于版本不一致的原因,经常会导致我们安装第三方库的时候,失败,大致报错如下:
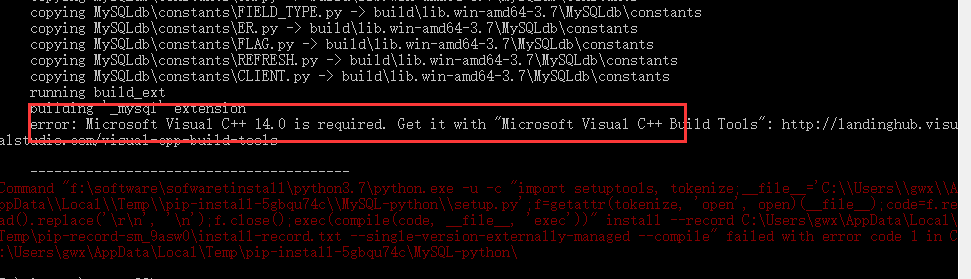
出现这个问题的原因是,我们默认安装的第三方插件和python的版本不一致,因此我们需要自己去下一个正确的版本。
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
搜索到我们需要的插件,然后存放到某个目录下,然后再运行pip install wheel‑0.31.1‑py2.py3‑none‑any.whl就可以了。
二、创建Scrapy项目
创建scrapy项目的命令依次如下:
1、创建一个项目 scrapy statrproject myproject
2、切换到myproject目录下 cd myproject
3、创建爬虫文件 scrapy genspider scrapyname www.baidu.com
4、运行项目 scrapy crawl myproject
创建完之后,项目的目录结构如下:
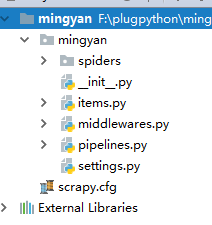
三、实例演示
现在我们需要抓取网站http://lab.scrapyd.cn的数据,只需要在spiders目录下编写我们的爬虫逻辑即可。
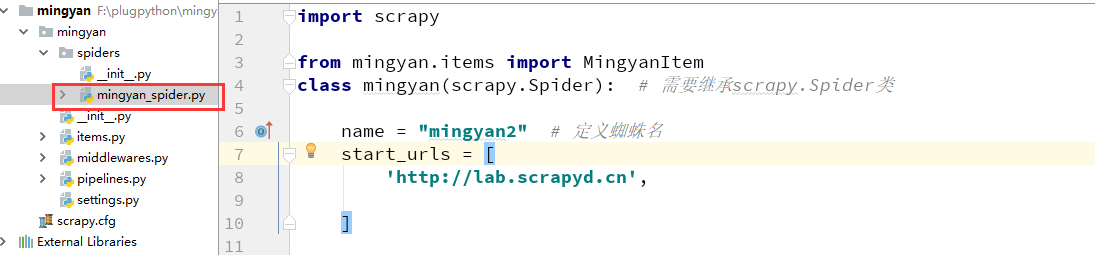
这里面的name和star_urls其实就是我们在创建的时候爬虫文件的时候传递的值。scrapy genspider mingyan2 lab.scrapyd.cn
爬虫的逻辑代码如下:


1 import scrapy 2 3 from mingyan.items import MingyanItem 4 class mingyan(scrapy.Spider): # 需要继承scrapy.Spider类 5 6 name = "mingyan2" # 定义蜘蛛名 7 start_urls = [ 8 'http://lab.scrapyd.cn', 9 10 ] 11 12 def parse(self, response): 13 item = MingyanItem() 14 quotes = response.css('div.quote') 15 for quote in quotes: 16 item['text'] = quote.css('.text::text').extract()[0] 17 item['author'] = quote.css('.author::text').extract()[0] 18 item['tags'] = quote.css('.tag::text').extract() 19 yield item 20 nextpage = response.css('li.next a::attr(href)').extract()[0] 21 if nextpage is not None: 22 yield scrapy.Request(nextpage,callback=self.parse)
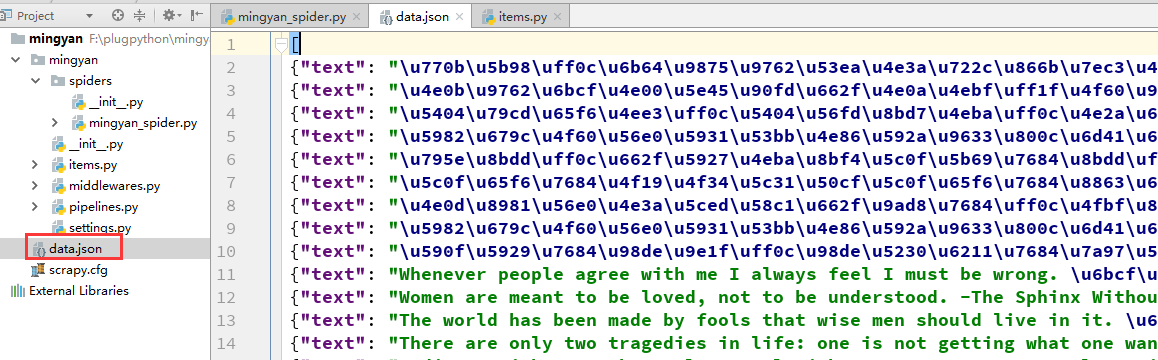
如果我们想让抓取的数据以不同的格式存储时,只需要在命令行运行的时候增加-o参数即可,例如想要抓取的数据以json的格式存储,命令如下:

生成的数据文件为json数组的形式:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号