


广告行业中那些趣事系列9:一网打尽Youtube深度学习推荐系统

最新最全的文章请关注我的微信公众号:数据拾光者。
摘要:本篇主要分析Youtube深度学习推荐系统,借鉴模型框架以及工程中优秀的解决方案从而应用于实际项目。首先讲了下用户、广告主和抖音这一类视频平台三者之间的关系:就是平台将视频资源作为商品免费卖给用户,同时将用户作为商品有偿卖给广告主,仅此而已。平台想获取更高的收益就必须提升广告的转化效率,而前提是吸引用户增加观看视频的时长,这里就涉及到视频推荐的问题。因为Youtube深度学习推荐系统是基于Embedding做的,所以第二部分讲了下Embedding从出现到大火的经过。最后一网打尽Youtube深度学习推荐系统。该系统主要分成两段式,第一段是生成候选项模型,主要作用是将用户可能感兴趣的视频资源从百万级别初筛到百级别;第二段是精排模型,主要作用是将用户可能感兴趣的视频从百级别精挑到几十级别,然后按照兴趣度得分进行排序形成用户观看列表。希望对推荐系统感兴趣的小伙伴有所帮助。
目录
01 用户、广告主和抖音类平台三者的关系
02 One-hot编码、Word2vec到Item2vec
03 Youtube深度学习推荐系统
1. Youtube推荐系统背景和面临挑战
2. 算法整体架构
3. 生成候选项模型
4. 精排模型
01 用户、广告主和抖音类平台三者的关系
如果对推荐系统和Embedding已经很熟的小伙伴可以直接跳到第三章看Youtube深度学习推荐系统。
通过下面一张图说明鸡贼广告主、吃瓜用户和抖音平台三者之间的关系:
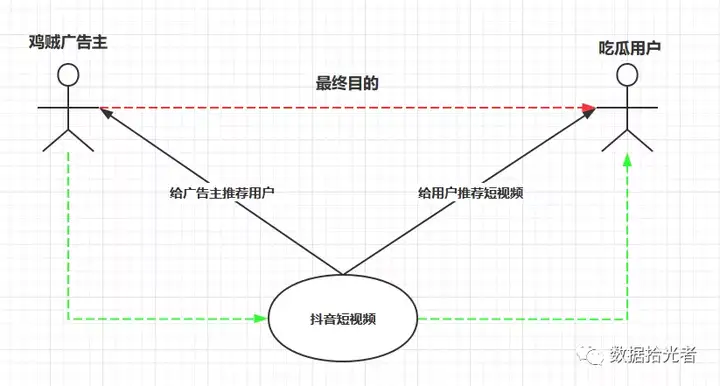
图1 用户、广告主和抖音类平台三者的关系
从商业角度来说,鸡贼广告主最终目的是把广告投放给吃瓜用户,让用户有广告转化,这里的广告转化可能是点击、下载甚至付费。但是通常情况下吃瓜用户一般对广告没啥兴趣,特别有创意的除外。这时候抖音短视频来了,给鸡贼广告主说我这边可以提供一个平台吸引海量用户,让更多的用户有广告转化。就这样,广告主直接给用户投广告的路不好走,只能通过曲线救国的方式,通过抖音平台里有趣的短视频来吸引用户,然后趁你看的开心的时候冷不丁刷到一个广告。因为用户花在抖音上的时间越来越多,曝光广告的机会也多了,总有部分人会点击、下载或者付费广告,就这样间接的达到了为广告主投放广告的目的。
抖音作为盈利性质的公司,最终目的是想多赚广告主的钱。要想多赚广告主的钱,就得吸引更多的用户来平台看短视频并且有广告转化行为。但是现在存在的问题是,用户因为个体差异所以兴趣是多种多样的,有些人喜欢游戏,有些人喜欢做饭,还有些人喜欢鸡汤,所以平台需要给不同的用户推荐不同类型的短视频,不然用户刷两下觉得没意思就走了。
这里不仅要给用户推荐他们感兴趣的视频,而且还得推荐最合适的。这里涉及到曝光资源的稀缺性问题,这个怎么理解。因为用户刷抖音的时间其实是有限的,在用户有限的时间里牢牢吸引住他们的眼球,然后才有可能让用户有更高的广告转化效率。所以这里的关系是,短视频作为商品被抖音提供给用户,只不过这里的商品是免费的。虽然对于用户是免费的,但是总得有人来为互联网公司的发展和运营买单。这种“羊毛出在猪身上”的商业模式最早是雅虎建立的。之前写过一篇文章《读浪潮之巅》涉及到这部分内容,感兴趣的小伙伴可以去看看。
言归正传,这里需要来为互联网公司的发展和运营买单的就是广告主。和用户一样,广告主因为自身产品的差异,所以广告的受众群体也是不同的。比如有个卖减肥药的广告主想把广告推送给对减肥药感兴趣的人群,还有个传奇游戏的广告主想把广告推送给对传奇游戏感兴趣的人群等等。所以这里的关系是,吃瓜用户作为商品被抖音“卖”给广告主,而这里的商品就不再是免费的,是需要广告主花钱来买的。
小结下,用户、广告主和抖音类平台三者之间的关系就是平台将视频资源作为商品免费卖给用户,同时将用户作为商品有偿卖给广告主,仅此而已。平台想获取更高的收益就必须提升广告的转化效率,而前提是吸引用户增加观看视频的时长,这里就涉及到视频推荐的问题。因为Youtube深度学习推荐系统是基于Embedding做的,所以下面引出Embedding。
02 One-hot编码、Word2vec到Item2vec
1. One-hot编码
通常机器学习中我们会使用One-hot编码对离散特征进行编码。小伙伴们要问了,啥是One-hot编码?
举例来说,我们现在一共有四个词:"i","love","legend","game"。计算机本身无法理解这四个词的含义,但是我们现在用一种编码表示。"i"编码为1000,"love"编码成0100,"legend"编码为0010,"game"编码为0001。
对One-hot通俗的理解就是有多少个词,就有多少位。如果有8个词,我们就需要长度为8的“01”串来表示词。每个词都有自己的顺序,那么对每个词One-hot编码的时候在该位置上置1其他都置为0。
现在我们把这四个词对应的编码输入到计算机里,计算机就能明白各个编码代表的含义。这种形式就是One-hot编码。通过One-hot编码我们就能轻松的表示这些文本。
One-hot编码存在一个问题,上面的例子中有四个词,我们就需要长度为4的01串来表示。如果有100W个词,那么我们就需要长度100W的01串来进行编码么?这显然不方便。所以One-hot编码最大的问题就是使得向量非常稀疏。尤其对于数量极其庞大的商品类的向量就会极端稀疏。
当今正处于深度学习大火的人工智能时代,One-hot编码造成的稀疏向量问题非常不利于深度学习以及工程实践。主要原因是深度学习中使用梯度下降算法来训练模型,当特征过于稀疏时每次只更新极少数的权重会导致整个网络收敛过慢。在样本有限的情况下可能导致模型根本不收敛。
2. Embedding出现
之后出现了Embedding技术,尤其在深度学习中Embedding技术大肆风靡,甚至有"万物皆Embedding"之说。有些小伙伴可能要好奇了,到底什么是Embedding?
通俗的理解就是,Embedding是用一个低维的空间去表示一个物体,这个物体可以是一个词、一个商品、一个视频或者一个人等等。我们通过另一个空间去表达某个物体,最重要的是可以揭示物体之间的潜在关系,有点透过现象看本质的意思。
以电影举例来说,在人类世界中我们认为《电锯惊魂》和《咒怨》有潜在关系,因为它们都属于恐怖片。但是对于机器来说本来不知道这两个东西有啥关系,但是经过Embedding操作之后,机器学会了它俩潜在的关系,可以说通过两个电影的名字(表面)看到了它们都属于恐怖片(本质)。这就是Embedding的神奇之处。
不仅如此,Embedding还具有数学运算的关系,比如存在四川的Embedding-成都的Embedding=广东的Embedding-广州的Embedding这样的关系。
3. Word2vec引爆Embedding潮流
自然语言处理领域中我们使用Embedding技术来进行词编码,也叫Word Embedding。真正引爆Embedding技术的是2013年Google超火的Word2Vec技术。Word2Vec技术将词映射到向量空间,通过一组向量来表示文本。Word2Vec技术很好的解决了One-hot编码引起的高纬度和稀疏矩阵的问题。
下图是我们通过Word2Vec将文本映射到三维立体空间中:
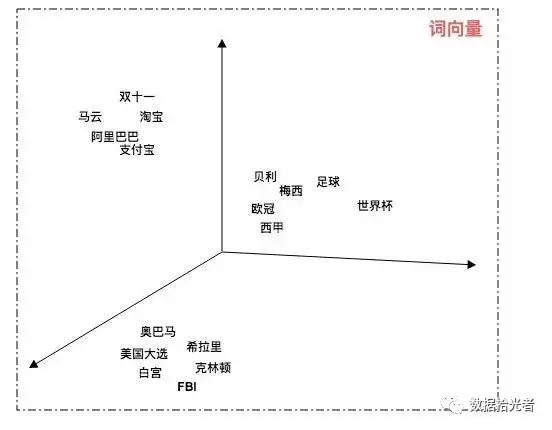 图2 Word2Vec映射到三维空间展示图
图2 Word2Vec映射到三维空间展示图
通过Word2Vec技术我们可以在低纬空间上表示文本。我们还可以通过计算词向量空间中的距离来表示语义的相似度。通过上图我们可以看出足球和世界杯的距离比较近,奥巴马和美国大选比较近,马云和阿里巴巴比较近等等。
Word2vec中有两种模型结构:CBOW和Skip-gram。CBOW就是通过上下文的词来预测当前词,非常好理解的一个方式就是我们小时候英语考试中的完形填空。给你一段话,中间抠去几个词,然后让你按照上下文来预测抠掉的这几个词。而另外一种Skip-gram则刚好相反,是根据当前的词来预测上下文的词,比较抽象,就不举例子了。CBOW和Skip-gram结构如下图所示:
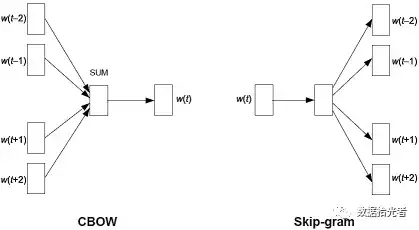 图3 Word2Vec两种结构
图3 Word2Vec两种结构
4. 从Word2vec到Item2vec
自从Word2vec引爆Embedding之后,很快Embedding从自然语言领域向所有机器学习领域辐射,这其中就包括广告、搜索、推荐等等领域。就拿推荐领域中抖音短视频来说,我们根据用户观看的短视频序列来给用户推荐下一个视频。因为用户、视频等数据的稀疏性,我们在构建DNN神经网络之前需要对用户user和视频video进行Embedding操作,然后才喂给模型去训练。关于Item2vec有一篇论文推荐:Item2Vec:Neural Item Embedding for Collaborative Filtering。
从本质上来说,Word2vec仅仅是Item2vec应用到自然语言处理领域中的一种。区别在于Word2vec有顺序关系,同样的几个词因为顺序不同可能表达的语义也是大相径庭的。而Item2vec则舍去序列中item的空间关系,没有了时间窗口的概念。就拿用户观看短视频来说,一段时间内用户观看ABCDEFG和EFGDCBA我们认为是一样的,更多的是考虑item之间的条件概率。下面是论文中Item2vec的目标函数:
 图4 Item2vec目标函数
图4 Item2vec目标函数
引入了Item2vec,下面我们正式进入一网打尽Youtube深度学习推荐系统,详细说说我们如何使用Embedding技术来做用户视频推荐的。
03 Youtube深度学习推荐系统
1. Youtube推荐系统背景和面临挑战
国人对Youtube可能不是很熟悉,这里拿抖音短视频来类比。咱们部分人可能每天会花部分时间看短视频娱乐消遣。对于抖音来说,用户观看视频的时间越长,可能产生的商业收益就会越高。这里用可能来说是有原因的。如果我们只是每天看抖音短视频而没有任何广告转化,其实对于抖音来说并不会真正产生商业收益,真正让抖音产生收益的是看一会视频突然冒出来的那一两个广告。只有这些广告经过用户点击、下载甚至付费行为才会给抖音增加商业收益。所以小伙伴们,这里我真诚的建议大家在享受抖音带来免费的快乐的同时,也尽一点自己的绵薄之力,点点广告,下载啥的,这样才能真的绿水长流。这也只有真正做广告这一行业才能明白其中的艰辛。
抖音短视频需要根据不同的用户兴趣来推荐不同类型的短视频,这样才能吸引大家不断的观看。举个反例,如果给一个喜欢做饭的用户不停的推荐游戏,那这个用户看两个就失去兴趣果断不看了。
 图5 Youtube上的视频推荐
图5 Youtube上的视频推荐
推荐系统领域中,尤其是像抖音这样海量用户下面临海量视频的推荐,主要面临以下几个挑战:
- 超大量级的用户和视频规模,真正面临大数据挑战;
- 视频和用户的行为更新速度非常快。视频方面,每秒都会有大量的视频上传,不仅存在流行热点的问题,而且需要平衡新视频和库存视频间的平衡。用户方面,用户兴趣的转变也非常快,可能今天喜欢游戏,明天就喜欢其他的,所以需要实时追踪用户的兴趣;
- 用户反馈存在很多噪音。一方面用户的历史行为是稀疏并且不完整的,另一方面视频数据本身是非结构化的,所以对于模型的鲁棒性要求很高。
2. 算法整体架构
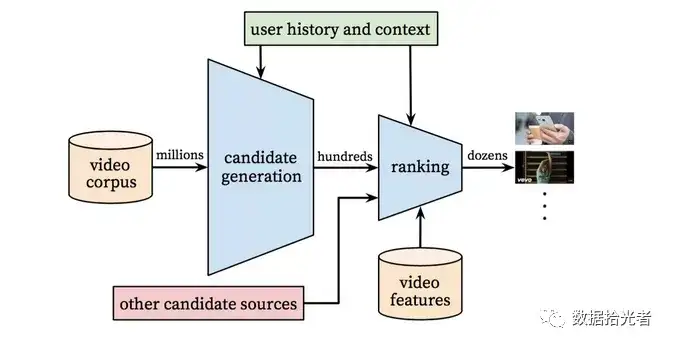 图6 Youtube算法整体架构
图6 Youtube算法整体架构
整体来看,Youtube深度学习推荐系统分成两段式,第一段是Candidate Generation Model,表面上理解就是生成候选项模型。像Youtube这样大体量的公司,拥有的视频资源量也是海量的。对于用户而言在视频资源池中我们可能会有百万数量级的候选视频可供推荐。这一段模型主要作用是从百万数量级的视频中进行初筛操作。经过这一轮的初筛,我们从百万级别的视频中选出了用户可能感兴趣的百数量级的视频;第二段是Ranking,可以理解为精排的操作。经过这一轮精排操作,我们从这百数量级的视频中选出了用户最可能看的几十数量级的视频,并且会进行排序,这个排序就会作为用户接下来观看的视频列表。这就是Youtube深度学习推荐系统的整体框架。下面咱们详细说下这两段模型。
3. 生成候选项模型Candidate Generation Model
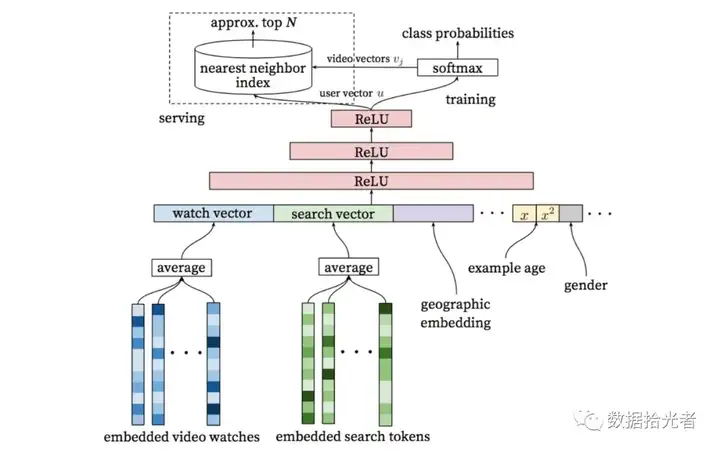 图7 生成候选项模型
图7 生成候选项模型
生成候选项模型如上图所示。咱们从下往上一层层抽丝剥缕。最下面一层是Embedded Video Watches和Embedded Search Tokens,作者通过Word2vec的方法对用户观看视频的历史和搜索词做了Embedding操作。经过这一波操作我们可以得到Wach Vector和Search Vector两个向量,这两个向量作为用户观看视频和搜索的特征输入。除此之外,我们还有地理位置的特征Geographic Embedding,性别相关的特征Gender等等。
这里有个比较特殊的特征叫Example Age。这个特征的作用是刻画用户对新视频的偏好程度。具体的做法是比如用户在20200410号下午20点18分点击了某个视频,那么产生了一条数据样本。后面模型训练的时候这条样本对应的Example Age就等于模型训练时那个时刻减去20200410号下午20点18分这个时刻。
如果模型训练时间距离样本产生的时间超过24小时,则设置为24。而当模型线上预测的时候则将这个特征置为0,这里设置为0的意思也很明显,保证预测的时候是处于模型训练的最后一刻。一个实际的现象是某个好视频刚出来那会是最容易被大家疯转点击和转发的,过了一段时间之后热度就会慢慢降下来趋于稳定,也就是视频存在一定的“时效性”。论文中也印证了加入该特征对模型的影响:
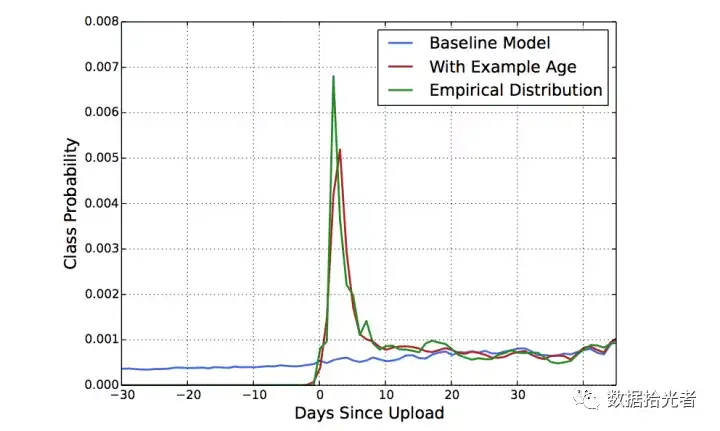 图8 Example Age特征的影响
图8 Example Age特征的影响
通过上图我们可以发现加入Example Age能使模型的预测更加接近经验分布,也更切合实际。
这里延伸到我们现在的业务中会有这样的思考:对于给用户投放广告来说,用户对于广告的新鲜度也是有一定偏好的。同样的广告来回给用户曝光,广告的转化效果应该不怎么样。分别从用户喜欢或者不喜欢某个广告来看,如果喜欢之前应该点过,那么后面应该不会再点。这里一个生活中的经验是就算周星驰的电影大家也不会在短时间内来回看,更别说广告了;如果不喜欢曝光多少次都是没用的。这里对于业务实践可能会有帮助。
言归正传,得到这些不同的特征之后我们会把这些特征拼接起来,这里就完成了特征准备工作。下面就是把这些特征喂给我们的三层Relu神经网络了。
经过三层Relu神经网络后我们得到了User Vector。User Vector一方面会用于模型线上服务,另一方面会通过一个Softmax层,Softmax会输出当前用户可能观看候选的百万级别的视频的概率,这里其实变成了一个多分类问题。
现在用户可能会看这百万级别的视频,每个视频会有一个概率,这些概率值相加为1。这里有个工程上的问题,因为候选的视频有百万级别,那么相当于是个百万数量级的多分类,这样对模型的效果和速度都会有很大的影响。那么Youtube的工程师是怎么做的呢?论文中说进行了负采样(Negative Sampling),并且使用Importance Weighting的方法对采样进行了校准操作。
这里通过一个例子来说明负采样具体怎么做的。比如我们现在有100W个候选视频,其实就有100W个类了。现在有个样本的标签是class_3,因为模型训练使用的是Softmax函数,所以模型更新参数会尽量使class_3的Softmax值偏向1,其他99W9999的类的Softmax值输出偏向0。当我们采用负采样的时候,如果设置负采样的数目为9999,那么相当于屏蔽了99W的类别,这样模型每次更新会使当前类别对应的Softmax接近1,其他9999个类别的Softmax偏向0,将百万分类“变”成了一万分类。通过上面这些工程上的骚操作使得生成候选项模型即使面对百万数量级的分类下依然能从容的应对模型训练和模型效果。
经过Softmax之后我们得到了视频向量Video Vector。这里又有个工程上的问题,为啥要采用最近邻搜索算法来选择百级别的视频?这里则是从工程和学术的角度做权衡之后的结果。如果直接使用训练时的模型去预测百万级别的候选集,模型的时间开销太大。一个不错的选择是我们通过模型分别得到User Embedding和VideoEmbedding之后,通过最近邻搜索的方法可以大幅度提升效率。工业中一般是将User Embedding和Video Embedding存储到Redis这一类内存数据库中。
这里有的小伙伴好奇这个User Embedding和Video Embedding具体怎么来的,咱们再细致的讲讲。这里通过一个详细的例子来说明:
关于User Embedding,当我们的模型训练完成之后,假如我们用100维度来表示User Embdding,那么我们隐藏层的最后一层输出的维度就是100X1维,隐藏层的输出作为Softmax层的输入,也就是说Softmax层的输入就是100X1维,而这个100X1维就是User Embedding。因为用户的行为是不断更新的,所以用户的User Embedding也是不断更新的,需要实时计算。实际项目中在机器等资源充足的情况下最好能做到User Embedding和Video Embedding高频度的更新,这样就能把用户最新的观看和搜索行为都能进入输入层从而得到反应用户最新的User Embedding。DNN输入是用户当时观看和搜索的视频(相对变化较大的)和用户画像(相对稳定的)特征组合,分别进入三层Relu得到一个100X1维向量,这就是实时的User Embedding;
关于Video Embdding,如果我们候选的视频有200W的话,那么我们Softmax的输出层就是200WX1,因为Softmax是输出每个视频被用户下一次观看的概率值。所以Softmax层的权重矩阵就是W(100X200W),经过转置就成了W(200WX100)。因为有200W个视频,所以是200W行,每个视频是100X1维,也就得到每个视频对应的Video Embedding。
这里得到User Embedding和Video Embedding之后,当我们要计算user_i观看video_j的概率时,就可以通过两个100维向量做内积得到。
这里还涉及到几个工程方面牛逼的操作:
- 每个用户生成固定数量的训练样本。在实际场景中,总会出现一些比较活跃的用户,而这些高度活跃的用户会对loss产生过度的影响。为了消除这部分影响,我们对每个用户使用固定的样本,平等的对待每个用户;
- Youtube完全摒弃了用户观看视频的时序信息,把用户最近一段时间看的视频同等对待。这里其实是容易理解的。当我们推荐的结果过多的受最近观看或者搜索的某个视频,会影响用户多样性的体验。举个例子来说,就算一个用户再喜欢王者荣耀的视频,你不断的推荐这种类型的视频,用户肯定也会审美疲劳的。因为通常来说用户会有多个兴趣,所以我们需要做到在用户的多个兴趣间循环,让用户感兴趣但又不会觉得腻;
- 对视频进行Embedding操作时把大量长尾的视频直接用0向量来代替。这样做也是基于经典工程和算法的一次权衡,把大量长尾的视频截断,主要目的是节约线上服务宝贵的内存资源;
- Youtube工程师选择用户最近一次观看的视频作为测试集,主要原因是防止引入未来信息,从而产生和实际情况不符的数据穿越现象;
- 数据源的多样性。模型不仅用了视频观看历史,而且还用了用户搜索。丰富的数据源可以多维度的刻画用户的兴趣,这也是我们实际工作中给用户打标签非常重要的;
- 关于候选项模型DNN网络结构的设计,性价比最高的方案是1024Relu->512Relu->256Relu。
关于业务方面还需要说明的是模型优化目标的确定。Youtube推荐系统将用户观看时间作为模型优化的目标,这是同时从模型和商业的角度分析得到的结果。模型方面需要反映用户真实的兴趣,选择观看时间比点击率或者播放率可能更有效。有时候用户虽然点了视频,但是可能看了两秒觉得没啥意思,这时如果把点击率当做评价指标,这条样本就是正例,但实际情况是用户可能对这条视频没啥兴趣。但是如果选择观看时间则能进一步反应用户兴趣,能在没兴趣的前提下坚持把视频看完是少之又少的。所以这里给咱们机器学习工程师的参考意义是开发模型的时候要深入到业务中,毕竟模型最终是服务于业务的。明确模型要优化的目标是成功的一半。
到这里,咱们完成了生成候选项模型的讲解,下面进入第二段精排模型。
4. 精排模型Ranking
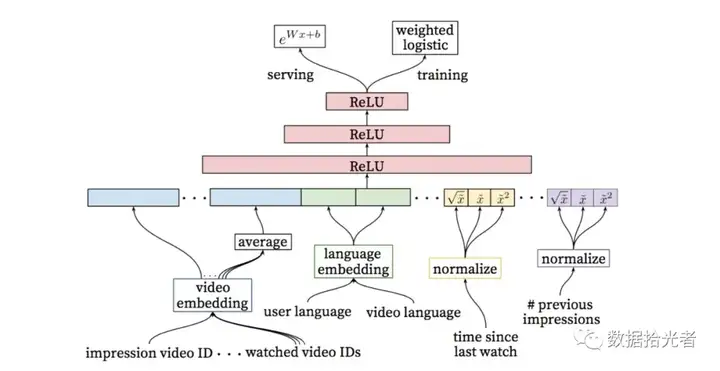 图9 精排模型
图9 精排模型
精排阶段的模型如上图所示,可以发现精排模型和生成候选项模型非常类似。区别在于特征工程和最上层部分。论文中其实也有说明,精排阶段的DNN模型目的是加入更多的视频描述特征、用户特征以及用户和视频之间关系的特征,从而真正达到对候选视频精排的目的。我们同样是从下往上层层剖析。首先就是最下层的特征工程,从左到右依次说明:
- Video Embedding:这里主要包括Impression Video ID和Watched Video IDS。其中Impression Video ID是当前要计算的视频的Embedding,Watched Video IDS是用户最后观看的N个视频Embedding的Average;
- Language Embedding:这里主要包括User Language和Video Language。其中User Language是用户语言的Embedding,Video Language是视频语言的Embedding;
- Time Since Last Watch:这是用户最近一次看同类型Channel视频的时间间隔;
- #Previous Impressions:这是记录当前视频给当前用户的曝光次数。
其中Time Since Last Watch和#Previous Impression这两个特征很好的关注了用户和视频之间关系。Time Since Last Watch主要用来关注用户观看同类型视频时间的间隔。这个是从用户兴趣的角度来进行的一种Attention行为。假如用户才看过“王者荣耀”类型的视频,那么该用户对这一类视频是有兴趣的,所以在后面的观看列表中添加这一类视频用户应该也会喜欢看。这里涉及到推荐系统需要给用户打标签的部分。这个特征最终的目的就是用户观看了某类视频,对这类视频就有兴趣。之前分享过一篇通过用户操作手机行为给用户打标签的文章广告系列第一篇统一兴趣建模流程,有兴趣的小伙伴可以翻来看看。
#Previous Impression特征则是让模型注意避免将一个视频重复曝光给用户,从而造成无效曝光。感觉这个特征和上面的Time
Since Last
Watch是相互作用的关系。上面的特征是让给用户打标,了解用户对某一类视频感兴趣。这个特征则告诉模型要适度。不能发现用户对某个视频感兴趣就疯狂的推荐。这两个特征和前面讲的我们要让用户看视频时既有兴趣,又不会觉得腻。还是比较难的。
值得注意的是上面两个特征都进行了归一化操作。不仅如此,还将归一化后的特征进行开方和平方处理后当做了不同的特征喂给模型。这是简单有效的工程经验,通过开方和平方的操作引入了特征的非线性。从论文反馈的效果来看,这一操作提升了模型离线的评估指标。
下面还是同样的操作,将这些特征进行拼接之后喂给模型。后面跟了三层Relu神经网络。然后使用了带权重的逻辑回归函数Weighted Logistic Regression作为输出层。这里使用带权重的逻辑函数主要原因是模型使用了视频预期观看时间作为优化目标,可以把观看时间作为正样本的权重,在提供线上服务的时候通过e(Wx+b)做预测得到期望观看时间的近似。
到这里,咱们完成了精排模型的讲解。
总结
本篇主要分析Youtube深度学习推荐系统,借鉴模型框架以及工程中优秀的解决方案从而应用于实际项目。首先讲了下用户、广告主和抖音这一类视频平台三者之间的关系:就是平台将视频资源作为商品免费卖给用户,同时将用户作为商品有偿卖给广告主,仅此而已。平台想获取更高的收益就必须提升广告的转化效率,而前提是吸引用户增加观看视频的时长,这里就涉及到视频推荐的问题。因为Youtube深度学习推荐系统是基于Embedding做的,所以第二部分讲了下Embedding从出现到大火的经过。最后一网打尽Youtube深度学习推荐系统。该系统主要分成两段式,第一段是生成候选项模型,主要作用是将用户可能感兴趣的视频资源从百万级别初筛到百级别;第二段是精排模型,主要作用是将用户可能感兴趣的视频从百级别精挑到几十级别,然后按照兴趣度得分进行排序形成用户观看列表。第三部分也是本篇的重点内容。
参考资料
1. 《Item2Vec: Neural Item Embedding forCollaborative Filtering》
2. 《Deep Neural Networks for YouTubeRecommendations》
注意:本篇黑色加粗的部分是对实际项目中有借鉴意义的实操经验,小伙伴们可以重点关注下。
最新最全的文章请关注我的微信公众号:数据拾光者。


