
02Spark架构与运行流程
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark生态圈也称为BDAS(伯克利数据分析栈),是伯克利APMLab实验室打造的,力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成来展现大数据应用的一个平台。伯克利AMPLab运用大数据、云计算、通信等各种资源以及各种灵活的技术方案,对海量不透明的数据进行甄别并转化为有用的信息,以供人们更好的理解世界。该生态圈已经涉及到机器学习、数据挖掘、数据库、信息检索、自然语言处理和语音识别等多个领域。
Spark生态圈以Spark Core为核心,从HDFS、Amazon S3和HBase等持久层读取数据,以MESS、YARN和自身携带的Standalone为资源管理器调度Job完成Spark应用程序的计算。 这些应用程序可以来自于不同的组件,如Spark Shell/Spark Submit的批处理、Spark Streaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib/MLbase的机器学习、GraphX的图处理和SparkR的数学计算等等。
2.用图文描述你所理解的Spark运行架构,运行流程。
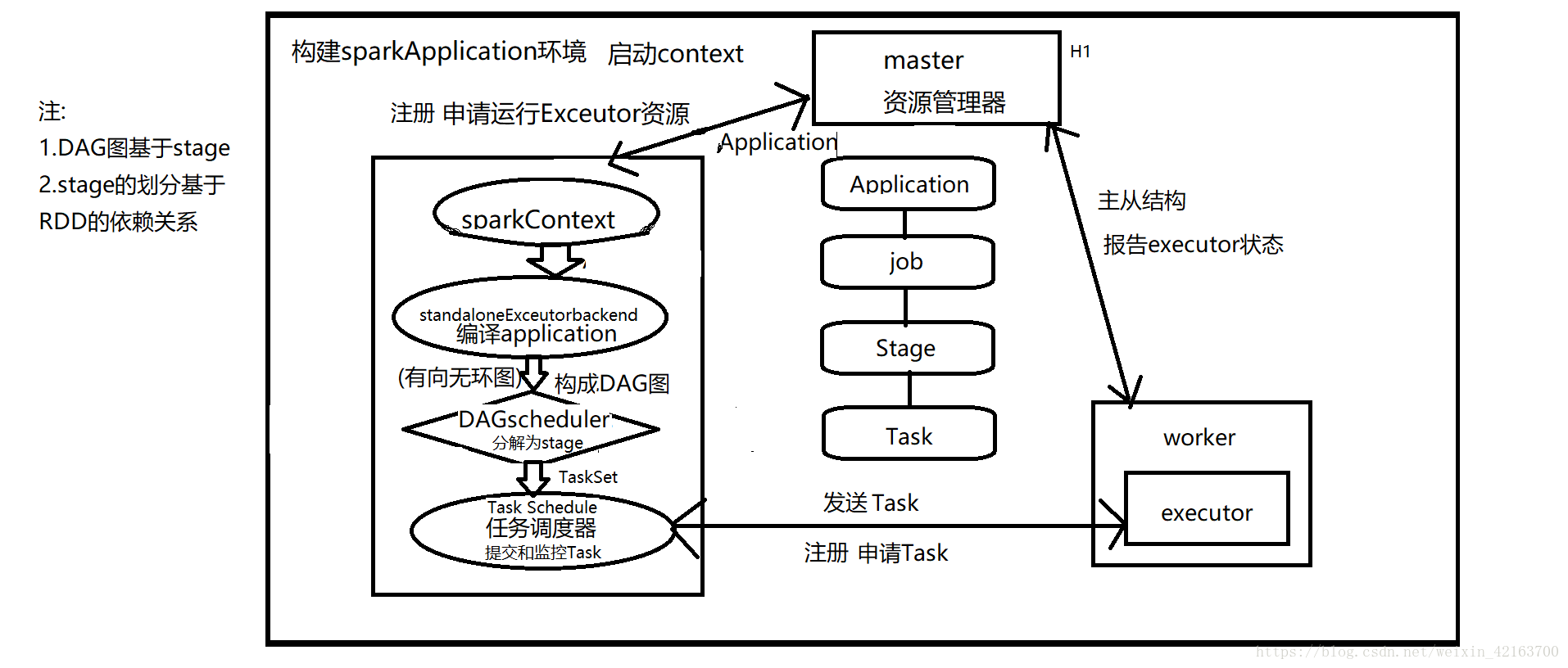
a.构建Spark Application的运行环境,启动SparkContext
b.SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,
c.Executor向SparkContext申请Task
d.SparkContext将应用程序分发给Executor
e.SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
f.Task在Executor上运行,运行完释放所有资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号