
结对作业NO.2
结对NO.2
1. 引言
1.1 项目地址
1.2 项目简介
按照老师给的项目要求:“编码实现一个部门与学生的智能匹配的程序”。由于数据需要自己生成,所以该项目主要分为两个子程序:数据生成模块与匹配模块。
(1) 数据生成模块
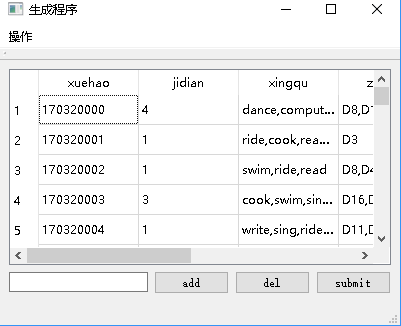
数据生成模块,根据题目的要求,生成学生和部门的所有属性。所有的属性均为随机生成。之后,将生成的数据通过输出流输出json形式的数据到一个文本文件中。同时,为了查看的更加直观,我们将其写入数据库,试用gui界面进行展示。在展示的时候,为了体现题目中可定制的生成数据的要求,我们使展示出来的数据可修改,一旦修改,就会作用到数据库中。为了便于查找某个学生或是部门,我们还设置了快速查找的功能。
(2) 匹配算法模块
根据项目要求和生成数据的特点,我们决定采用绩点优先原则进行学生与部门的匹配。
之后再根据学生志愿,学生兴趣等因素进行抉择。当然,学生空闲时间与部门活动时间不能冲突。
2. 数据生成模块
2.1 算法思想
在想法上,我们首先要确定这是涉及到两个对象,每个对象都是有不同的属性,对不同类的属性:
1.如果需要的只是一个简单的数值,那么,就可以用随机数来限定生成范围生成这个数值。比如学生的绩点以及部门的纳新人数等。
2.如果需要的不是一个数值,而是一个字符串,那么,就先预定义一些标签,在这么多标签中随机取出符合要求的个数的标签,而且在涉及到同种属性(如学生的兴趣与部门的标签)时,使用同一堆标签作为备选,之后在通过生成随机值作为随机索引在这么一堆标签中取出标签,作为某个类的某个属性,以这样的方法产生学生的兴趣、部门的标签等属性。
3.对于生成的文件的显示,可以做成json形式的文件,方便查看。也可以将其输入数据库,写一个GUI界面进行展示,方便修改。(因为我们都认为json的输出简单,解析较麻烦,看到题目又可以实使用数据库,所以就也往数据库中输出了一次。)
2.2 具体实现
- 数据的生成
部门:
1.对部门名称统一格式的命名,统一采取“D”开头的命名,如“D1”,“D2”等
2.对部门的纳新人数,通过产生随机数去确定,军固定在10-15之间
3.标签的产生,是在预先设定好的标签中随机取出5个作为标签(不重复)
4.活动时间的产生,将每天按照上课时间划分为5个时间段,一周7天,那么就是35个时间段,在这35个时间段中生成xx个作为该部门的常规活动时间段
学生
1.学生的属性需要先按序生成学号,按照形式生成,1703200+xx
2.学生的绩点,生成随机数进行确定。
3.学生的兴趣,使用与生成部门时的10个标签,之后生成随机数,在预先定义好的10个标签中随机取不重复的xx个。
4.学生的志愿:我们考虑到的是,按照正常的额想法,学生会根据部门的标签与自己的兴趣的匹配来产生候选的部门的序列,我们就是先生成这种序列,之后在这个序列中取小于5个的部门编号作为学生的志愿。
- 数据的输出
1.是用Qt中的与json相关的类,如QJsonObejct、QJsonArray等对生成的数据写成json格式,之后将整体使用QTextStream输出到文本文件。
2.使用QDatabase将数据输出到数据库,并使用QSqlTable进行数据的展示,以及实现修改、查找等功能。
3. 数据匹配模块
3.1 算法思想
1.将所有学生以及所有部门的信息分别分装成一个list待用;
2.对于匹配,采取志愿加时间、兴趣+时间、时间的匹配。
3.按照优先级,高优先级的匹配成功之后,就不进入低优先级的匹配函数中进行匹配。
3.2 具体实现
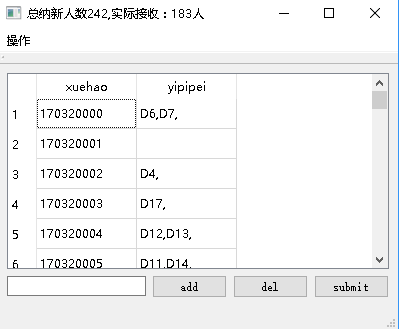
1.在数据库中进行select语句,并order by 绩点 desc,之后将数据返回。
2.返回之后,将所有信息保存到List<学生>或者list<部门>中,备用。
2.对所有学生进行遍历。在遍历到某一确定学生的时候,由于之前产生部门意愿时是从符合学生的兴趣的部门中随机选出,所以,在第一轮只要将该学生的志愿所对应的部门取出,之后进行只要学生的空闲时间包括部门的常规活动时间,那么,就会成为匹配度较高的匹配。并将isSuccess变量置为true。
3.将学生学号加入到部门“已匹配”的属性中,奖部门名称加入到学生“已匹配”的属性中,将部门的纳新中人数减一。
4.如果此时isSuccss仍为初始值false,那么,就进行下一轮的匹配。将学生的兴趣标签取出,在list<部门>中随机选取一个,比对该部门的标签是否包含该学生的某一个兴趣标签,之后再对时间进行匹配。
5.如果成功,重复3.
6.如果两轮下来还是为isSuccess仍为false,那么,就将学生的空闲时间取出,与在list<部门>中随机取出的部门进行匹配。
7.如果成功,重复3.
8.将数据生成。

4. 代码规范
4.1 规范要点
- 由于C++语言的复杂性,再加上我们的项目规模不是很大,我们当即决定不用继承。虽然在匹配算法中使用抽象类可以提高代码的复用性和封装型,但是相比之下运算符的重载更易实现。
- 尽量避免使用new和delete。由于我们对于vs编译器的内存管理并不是很了解,所以这可能导致对象的管理不符合我们自身的预期;但当需要生成对象数量过多时,可以用new生成对象实体,但不要忘了使用后用delete释放资源。
- 把所有的清理工作都放在析构函数中。如果有些资源在析构函数之前就释放了,也要重置这些成员为0或NULL。
- 在设计按绩点优先或活动时间长度优先的算法时可以优先考虑运算符()的重载。
- 由于学生和部门对象多数只用于封装信息,所以可以考虑用struct实现它们。
4.2 相关代码
struct departments
{
std::string id;//部门id
std::string name;//部门名称
int num;//招收人数
std::vector<std::string> tag;//标签
std::vector<std::string> freetime;//空闲时间段
};
//绩点降序比较结构体 ————重载()操作符
struct CmpMark
{
bool operator()( const student &k1, const student &k2)
{
//绩点降序
return k1.getMark() > k2.getMark();
}
bool operator()(const student &k1, const student &k2)
{
//绩点相同时学号优先
return k1.getId() < k2.getId();
}
};
5. 分析评价
5.1 评价标准
对于该项目的评价主要有两个方向:对于同一组输入,输出的未被导师选中的学生数越少越好;不同优先条件下,算法的执行时间越短越好。(在同一优先条件下,我们可以通过观察匹配学生人数来对数据生成模块进行反向优化.)
5.2 算法测试报告
| 优先条件 | 部门总纳新人数 | 匹配学生个数 | 未匹配学生个数 | 实际耗时(秒) | 输出文件路径 | 输出文件路径 |
|-----------------------------------------|-----------------------------------------|------------------|------------------|----------------------|-----------------------------------------------|
| 绩点优先 | 242 | 182 | 118 | 0.39 | https://github.com/willJefferson/clubProject/blob/master/output_condition1.txt |
| 活动时长优先 | 242 | 183 | 117 | 0.335 |https://github.com/willJefferson/clubProject/blob/master/output_condition2.txt
|
6. 结对感受
(1)张松
潘伟靖同学的编程能力很强,编程效率也很高。在完成项目任务时,他能迅速找到问题的主要矛盾;在具体工作中,他会先考虑重要的任务,然后立即去执行;在讨论时善于表达自己的思路和观点,善于引导讨论主题;当然,对我比较包容有木有。总之,和他结对是非常愉快的。
此外,他的风格是迅疾型的,所以需要有人进行扫尾工作,我正好可以做这方面的工作。所以从某方面说,我们可以做到互补。
(2)潘伟靖
在结对中,张松同学总是能提出建设性的意见,对于实现方法大有益处。由于我个人的编程习惯还不太好,想到什么写什么,最后,在与张松同学的结对过程中,进行了一些改正。
在结对过程,两个人一起看着同一个屏幕,真的是与一个人不同。两个人的效率感觉已经是1+1>2了。
