
有赞延迟队列设计
延迟队列,顾名思义它是一种带有延迟功能的消息队列。 那么,是在什么场景下我才需要这样的队列呢?
背景
我们先看看以下业务场景:
- 当订单一直处于未支付状态时,如何及时的关闭订单,并退还库存?
- 如何定期检查处于退款状态的订单是否已经退款成功?
- 新创建店铺,N天内没有上传商品,系统如何知道该信息,并发送激活短信?等等
为了解决以上问题,最简单直接的办法就是定时去扫表。每个业务都要维护一个自己的扫表逻辑。 当业务越来越多时,我们会发现扫表部分的逻辑会非常类似。我们可以考虑将这部分逻辑从具体的业务逻辑里面抽出来,变成一个公共的部分。
那么开源界是否已有现成的方案呢?答案是肯定的。Beanstalkd(http://kr.github.io/beanstalkd/), 它基本上已经满足以上需求。但是,在删除消息的时候不是特别方便,需要更多的成本。而且,它是基于C语言开发的,当时我们团队主流是PHP和Java,没法做二次开发。于是我们借鉴了它的设计思路,用Java重新实现了一个延迟队列。
设计目标
- 消息传输可靠性:消息进入到延迟队列后,保证至少被消费一次。
- Client支持丰富:由于业务上的需求,至少支持PHP和Python。
- 高可用性:至少得支持多实例部署。挂掉一个实例后,还有后备实例继续提供服务。
- 实时性:允许存在一定的时间误差。
- 支持消息删除:业务使用方,可以随时删除指定消息。
整体结构
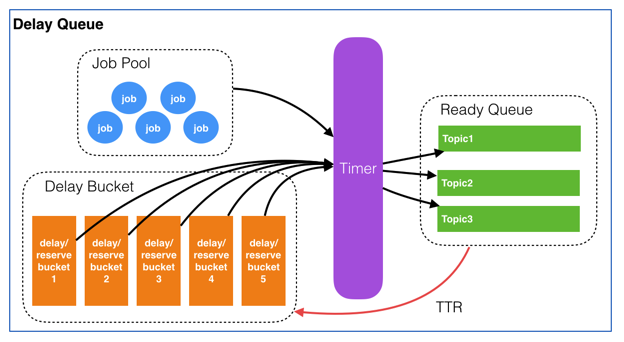
整个延迟队列由4个部分组成:
- Job Pool用来存放所有Job的元信息。
- Delay Bucket是一组以时间为维度的有序队列,用来存放所有需要延迟的/已经被reserve的Job(这里只存放Job Id)。
- Timer负责实时扫描各个Bucket,并将delay时间大于等于当前时间的Job放入到对应的Ready Queue。
- Ready Queue存放处于Ready状态的Job(这里只存放Job Id),以供消费程序消费。
如下图表述: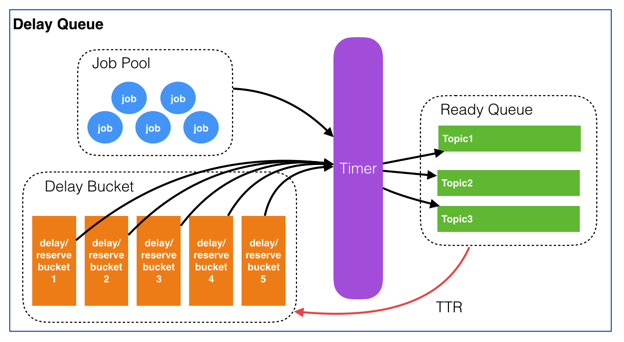
设计要点
基本概念
- Job:需要异步处理的任务,是延迟队列里的基本单元。与具体的Topic关联在一起。
- Topic:一组相同类型Job的集合(队列)。供消费者来订阅。
消息结构
每个Job必须包含一下几个属性:
- Topic:Job类型。可以理解成具体的业务名称。
- Id:Job的唯一标识。用来检索和删除指定的Job信息。
- Delay:Job需要延迟的时间。单位:秒。(服务端会将其转换为绝对时间)
- TTR(time-to-run):Job执行超时时间。单位:秒。
- Body:Job的内容,供消费者做具体的业务处理,以json格式存储。
具体结构如下图表示: TTR的设计目的是为了保证消息传输的可靠性。
TTR的设计目的是为了保证消息传输的可靠性。
消息状态转换
每个Job只会处于某一个状态下:
- ready:可执行状态,等待消费。
- delay:不可执行状态,等待时钟周期。
- reserved:已被消费者读取,但还未得到消费者的响应(delete、finish)。
- deleted:已被消费完成或者已被删除。
下面是四个状态的转换示意图: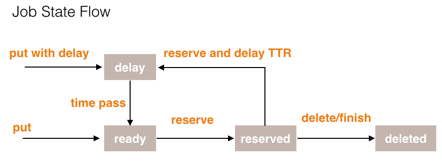
消息存储
在选择存储介质之前,先来确定下具体的数据结构:
- Job Poll存放的Job元信息,只需要K/V形式的结构即可。key为job id,value为job struct。
- Delay Bucket是一个有序队列。
- Ready Queue是一个普通list或者队列都行。
能够同时满足以上需求的,非redis莫属了。
bucket的数据结构就是redis的zset,将其分为多个bucket是为了提高扫描速度,降低消息延迟。
通信协议
为了满足多语言Client的支持,我们选择Http通信方式,通过文本协议(json)来实现与Client端的交互。 目前支持以下协议:
- 添加:{‘command’:’add’, ’topic’:’xxx’, ‘id’: ‘xxx’, ‘delay’: 30, ’TTR’: 60, ‘body’:‘xxx'}
- 获取:{‘command’:’pop’, ’topic’:’xxx'}
- 完成:{‘command’:’finish’, ‘id’:’xxx'}
- 删除:{‘command’:’delete’, ‘id’:’xxx'}
body也是一个json串。
Response结构:{’success’:true/false, ‘error’:’error reason’, ‘id’:’xxx’, ‘value’:’job body'}
强调一下:job id是由业务使用方决定的,一定要保证全局唯一性。这里建议采用topic+业务唯一id的组合。
举例说明一个Job的生命周期
- 用户对某个商品下单,系统创建订单成功,同时往延迟队列里put一个job。job结构为:{‘topic':'orderclose’, ‘id':'ordercloseorderNoXXX’, ‘delay’:1800 ,’TTR':60 , ‘body':’XXXXXXX’}
- 延迟队列收到该job后,先往job pool中存入job信息,然后根据delay计算出绝对执行时间,并以轮询(round-robbin)的方式将job id放入某个bucket。
- timer每时每刻都在轮询各个bucket,当1800秒(30分钟)过后,检查到上面的job的执行时间到了,取得job id从job pool中获取元信息。如果这时该job处于deleted状态,则pass,继续做轮询;如果job处于非deleted状态,首先再次确认元信息中delay是否大于等于当前时间,如果满足则根据topic将job id放入对应的ready queue,然后从bucket中移除;如果不满足则重新计算delay时间,再次放入bucket,并将之前的job id从bucket中移除。
- 消费端轮询对应的topic的ready queue(这里仍然要判断该job的合理性),获取job后做自己的业务逻辑。与此同时,服务端将已经被消费端获取的job按照其设定的TTR,重新计算执行时间,并将其放入bucket。
- 消费端处理完业务后向服务端响应finish,服务端根据job id删除对应的元信息。
现有物理拓扑
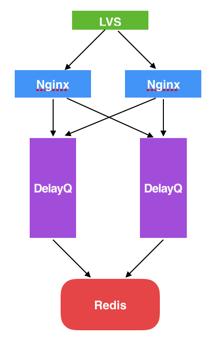 目前采用的是集中存储机制,在多实例部署时Timer程序可能会并发执行,导致job被重复放入ready queue。为了解决这个问题,我们使用了redis的setnx命令实现了简单的分布式锁,以保证每个bucket每次只有一个timer thread来扫描。
目前采用的是集中存储机制,在多实例部署时Timer程序可能会并发执行,导致job被重复放入ready queue。为了解决这个问题,我们使用了redis的setnx命令实现了简单的分布式锁,以保证每个bucket每次只有一个timer thread来扫描。
设计不足的地方
timer是通过独立线程的无限循环来实现,在没有ready job的时候会对CPU造成一定的浪费。
消费端在reserve job的时候,采用的是http短轮询的方式,且每次只能取的一个job。如果ready job较多的时候会加大网络I/O的消耗。
数据存储使用的redis,消息在持久化上受限于redis的特性。
scale-out的时候依赖第三方(nginx)。
未来架构方向
基于wait/notify方式的Timer实现。
提供TCP长连的API,实现push或者long-polling的消息reserve方法。
拥有自己的存储方案(内嵌数据库、自定义数据结构写文件),确保消息的持久化。
实现自己的name-server。
考虑提供周期性任务的直接支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号