

记一次有惊无险的 JVM 优化经历
转载:https://my.oschina.net/u/3627055/blog/2995973
背景
生产环境有二台阿里云服务器,均为同一时期购买的,CPU、内存、硬盘等配置相同。具体配置如下:
|
节点 |
CPU |
内存 |
硬盘 |
其它 |
|
A |
2CPU |
4G |
普通云盘 |
Centos6.4 64位+JDK1.8.0_121 |
|
B |
2CPU |
4G |
普通云盘 |
Centos6.4 64位+JDK1.8.0_121 |
由于这二服务器硬件和软件配置相同,并且运行相同的程序,所以在Nginx轮询策略均weight=1,即平台的某个流量由这二台机器平分。
有一次对系统进行例行检查,使用PinPoint查看下服务器”Heap Usage”的使用情况时,发现在有一个系统Full GC非常频繁,大约五分钟一次Full GC,吓我一跳。
这么频繁的Full GC,导致系统暂停处理业务,对系统的实时可用性大打折扣。
我检查了一下Tomcat(Tomcat8.5.28)配置,发现在tomcat没有作任何关于JVM内存的设置,全部使用默认模式。
由于这二服务器硬件和软件配置相同,并且运行相同的程序,所以在Nginx轮询策略均weight=1,即平台的某个流量由这二台机器平分。
GC数据
在业务峰期间,通过PinPoint观察的A、B节点的”Heap Usage”使用情况,分别进行以下几个时间段数据。
3小时图:
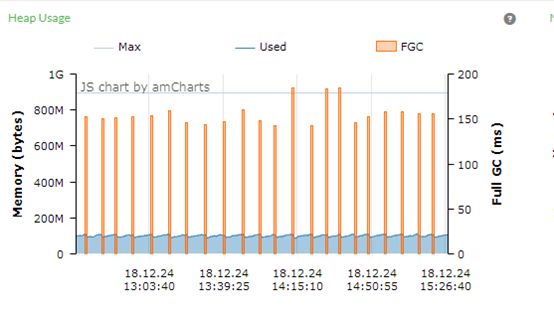
上图B系统在三个小时内,一共发生了22次Full GC,大约每8分钟进行一次Full GC。
每次Full GC的时间大概有150ms左右,即B系统在三个小时内,大约有3300ms暂停系统运行。
从上图来看,堆的空间最大值在890M左右,但在堆空间的大小大约200M就发生Full GC了,从系统资源的利用角度来考虑,这个使用率太低了。

上图A系统在3个小时内,一共发生了0次Full GC,嗯,就是没有任何停顿。
在这3小时,系统一直在处理业务,没有停顿。堆的总空间大约1536m,目前堆的空间大于500M。
6小时图:

上图B系统在6个小时的数据统计和3个小时很像,6个小时内一共发生了N次Full GC,均是堆的空间小于200M就发生Full GC了。
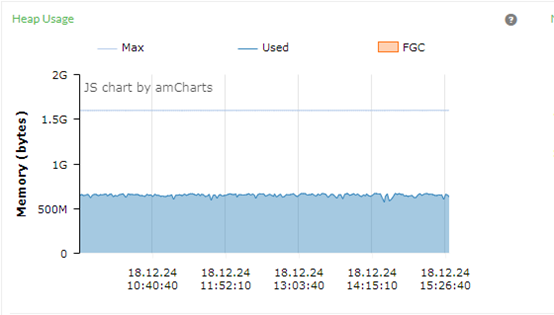
上图A系统在6个小时内,一共发生了0次Full GC,表现优秀。
12小时

上图B系统在12个小时内,一共发生了N次Full GC,左边Full GC比较少,是因为我们的业务主要集中白天,虽然晚上属于非业务高峰期间,还是有Full GC。
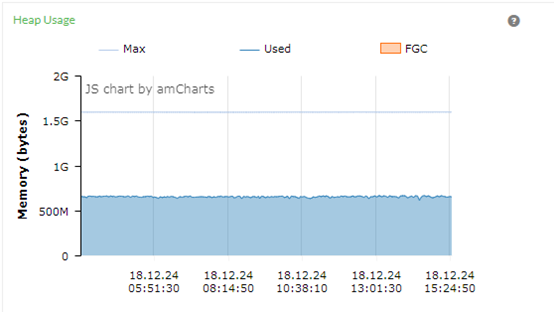
上图A系统在12个小时内,一共发生了0次Full GC,表现优秀。
GC日志
看下gc.log文件,因为我们两台服务器都输出了gc的详细日志,先看下B系统的Full GC日志。
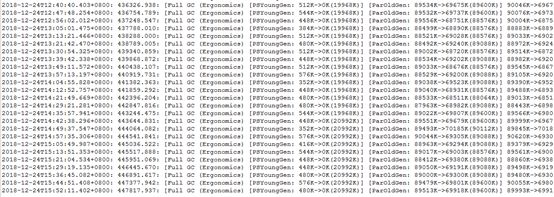
上图全部是” [Full GC (Ergonomics)”日志,是因为已经去掉” GC (Allocation Failure”日志,这样更方便观察和分析日志。
我们选取GC日志文件最后一条Full GC日志。
2018-12-24T15:52:11.402+0800: 447817.937: [Full GC (Ergonomics) [PSYoungGen: 480K->0K(20992K)] [ParOldGen: 89513K->69918K(89600K)] 89993K->69918K(110592K), [Metaspace: 50147K->50147K(1095680K)], 0.1519366 secs] [Times: user=0.21 sys=0.00, real=0.15 secs]
可以计算得到以下信息:
-
堆的大小:110592K=108M
-
老生代大小:89600K=87.5M
-
新生代大小:20992K=20.5M
分析:这次Full GC是因为老年代对象占用的空间的大小已经超过老年代容量 引发的Full GC。
[ParOldGen: 89513K->69918K(89600K)]
究其原因,是因为分配给老年代的空间太小,远远不能满足系统对业务的需要。
这导致老年代的空间常常被占满,老年代的空间满了,导致Full GC。而由于老年代的空间比较小,所以每次Full GC的时间也比较短。
A系统日志,只有2次Full GC,这2次GC均发生在系统启动时:
7.765: [Full GC (Metadata GC Threshold) [PSYoungGen: 18010K->0K(458752K)] [ParOldGen: 15142K->25311K(1048576K)] 33153K->25311K(1507328K), [Metaspace: 34084K->34084K(1081344K)], 0.0843090 secs] [Times: user=0.14 sys=0.00, real=0.08 secs]
可以得到以下信息:
-
堆的大小:1507328K=1472M
-
老生代大小:89600K=1024M
-
新生代大小:20992K=448M
分析:A系统只有系统启动才出现二次Full GC现象,而且是” Metadata GC Threshold”引起的,而不是堆空间引起的Full GC。
虽然经过一个星期的观察,A系统没有Full GC,但一旦发生Full GC时间则会比较长。
其它系统曾经发现过,1024M的老年代,Full GC持续的时间大约是90ms秒。
所以看得出来推也不是越大越好,或者说在UseParallelOldGC收集器中,堆的空间不是越大越好。
分析与优化
总体分析:
-
B系统的Full GC过于频繁,是因为老生代只有约108M空间,根本无法满足系统在高峰时期的内存空间需求
-
由于ParOldGen(老年代)常常被耗尽,所以就发生Full GC事件了
-
A系统的堆初始空间(Xms)和堆的最大值(Xmx)均为1536m,完全可以满足业务高峰期的内存需求
优化策略:
-
B系统先增加堆空间大小,即通过设置Xms、 Xmx值增加堆空间。直接把Xms和Xmx均设置为1024M。
-
堆的启动空间(Xms)直接设置为堆的最大值的原因是:因为直接把Xms设置为最大值(Xmx)可以避免JVM运行时不停的进行申请内存,而是直接在系统启动时就分配好了,从而提高系统的效率。
-
把Xms(堆大小)设置为1024M,是因为采用JDK的建议,该建议通过命令得到:
java -XX:+PrintCommandLineFlags -version
-
综合下来的B系统的JVM参数设置如下:
export JAVA_OPTS="-server –Xms1024m -Xmx1024m -XX:+UseParallelOldGC -verbose:gc -Xloggc:../logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
-
A系统JVM参数设置保持不变,以便观察系统运行情况,即:
export JAVA_OPTS="-server -Xms1536m -Xmx1536m -XX:+UseParallelOldGC -verbose:gc -Xloggc:../logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-
将A、B节点系统的JVM参数采用2套参数,是为了验证A或B的参数更适合实际情况。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人