

CPU突然飙升到300%,Dubbo活动线程数直接飙到1000
转:https://mp.weixin.qq.com/s/-lSiVDfqYrKk_w-xitYBhA
背景:新功能开发测试完成后,准备发布上线,当发布完第三台机器时,监控显示其中一台机器CPU突然飙升到300%,Dubbo活动线程数直接飙到1000+,不得不停止发布,立马回滚出问题的机器,回滚之后恢复正常;继续观察另外两台已经发布的机器,最终,无一幸免,只能全部回滚了。
下面是我的故障排查过程:
监控日志分析
首先查看故障时间点的应用日志,发现大量方法耗时较久,其中filterMission方法尤为显著,耗时长达30S+。说明下,filterMission是当前服务中QPS较高的接口(日均调用量2个亿),所以导致故障的可能性也较高。于是重新review了一遍filterMission的实现,其中并无复杂的计算逻辑,没有大量数据的处理逻辑,也不存在锁的争用,本次需求更是不涉及filterMission的改造,排除filterMission导致故障发生。
从日志中也可以发现,大量请求发生超时,这些都只能说明系统负载过重,并不能定位问题的症结所在。
Code Review
从应用日志找不到原因所在,只能再做一次code review了。首先检查系统中是否存在同步代码逻辑的使用,主要是为了排除发生死锁的可能;检查具有复杂运算逻辑的代码;同时,将本次修改的代码和上一版本进行比对,也没找出什么问题。(事实证明,Review不够仔细)
线程Dump分析
到此,从日志中暂时也分析不出问题,盲目看代码也无法具体定位问题了,现在只能重新发布一台机器,出现问题时让运维将应用程序的线程堆栈dump出来,分析jstack文件。开始分析dump文件前,先巩固下基础吧。
线程状态
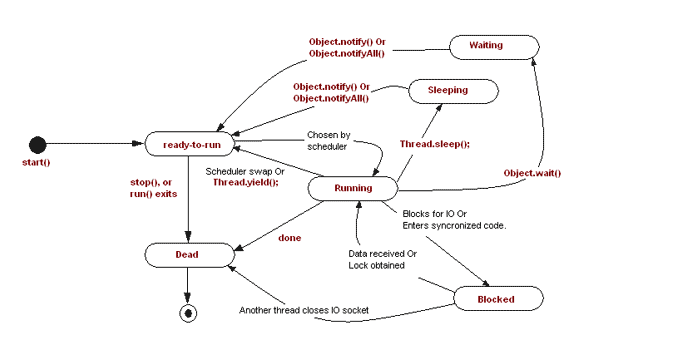
图中各状态说明:
New: 新建状态,当线程对象创建时存在的状态;
Runnable:ready-to-run,可运行状态,调用thread.start()后,线程变成为Runnable状态,还需要获得CPU才能运行;
Running:正在运行,当调用Thread.yield()或执行完时间片,CPU会重新调度;注意:Thread.yield()调用之后,线程会释放CPU,但是CPU重新调度可能让线程重新获得时间片。
Waiting:调用thread.join()、object.wait()和LockSupport.park()线程都会进入该状态,表明线程正处于等待某个资源或条件发生来唤醒自己;thread.join()、object.wait()需要Object的notify()/notifyAll()或发生中断来唤醒,LockSupport.park()需要LockSupport.unpark()来唤醒,这些方法使线程进入Runnable状态,参与CPU调度。
thread.join():作用是等待线程thread终止,只有等thread执行完成后,主线程才会继续向下执行;从join()实现可知,主线程调用thread.join()之后,只有thread.isAlive()返回true,才会调用object.wait()使主线程进入等待状态,也就是说,thread.start()未被调用,或thread已经结束,object.wait()都不会被调用。也就是说,必须先启动线程thread,调用thread.join()才会生效;若主线程在waiting状态被唤醒,会再次判断thread.isAlive(),若为true,继续调用object.wait()使进入waiting状态,直到thread终止,thread.isAlive()返回false。
object.wait():作用是使线程进入等待状态,只有线程持有对象上的锁,才能调用该对象的wait(),线程进入等待状态后会释放其持有的该对象上的锁,但会仍然持有其它对象的锁。若其他线程想要调用notify()、notifyAll()唤醒该线程,也需要持有该对象的锁。
LockSupport.park():挂起当前线程,不参与线程调度,除非调用LockSupport.unpark()重新参与调度。
Timed_Waiting:调用Thread.sleep(long)、LockSupport.parkNanos(long)、thread.join(long)或obj.wait(long)等都会使线程进入该状态,与Waiting的区别在于Timed_Waiting的等待有时间限制;
Thread.sleep():让当前线程停止运行指定的毫秒数,该线程不会释放其持有的锁等资源。
Blocked:指线程正在等待获取锁,当线程进入synchronized保护的代码块或方法时,没有获取到锁,则会进入该状态;或者线程正在等待I/O,也会进入该状态。注意,java中Lock对象不会使线程进入该状态。
Dead:线程执行完毕,或者抛出了未捕获的异常之后,会进入dead状态,表示该线程结束。
上图中某些状态只是为了方便说明,实际并不存在,如running/sleeping,java中明确定义的线程状态值有如下几个:
NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINATED
分析jstack日志
-
大量dubbo线程处于WAITING状态,看日志:
1 2 3 4 5 6 7 8 9 10 11 12 | "DubboServerHandler-172.24.16.78:33180-thread-1220" #1700 daemon prio=5 os_prio=0 tid=0x00007f3394988800 nid=0x4aae waiting on condition [0x00007f32d75c0000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000866090c0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1081) at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) |
由日志可知道,线程“DubboServerHandler-172.24.16.78:33180-thread-1220”处于WAITING状态,主要原因是线程从线程池队列中取任务来执行,但线程池为空,最终调用了LockSupport.park使线程进入等待状态,需要等待队列非空的通知。
设想一下,什么时候会新创建新线程来处理请求?结合jdk线程池实现可知,当新请求到来时,若池中线程数量未达到corePoolSize,线程池就会直接新建线程来处理请求。
根据jstack日志,有195个dubbo线程从ScheduledThreadPoolExecutor中取任务导致处于WAITING状态,按理这些dubbo线程只负责处理客户端请求,不会处理调度任务,为什么会去调度任务线程中取任务呢?这里暂时抛出这个问题吧,我也不知道答案,希望有大神帮忙解答。
-
还有另外一部分WAITING状态的线程,看日志:
1 2 3 4 5 6 7 8 9 10 11 12 | "DubboServerHandler-172.24.16.78:33180-thread-1489" #1636 daemon prio=5 os_prio=0 tid=0x00007f33b0122800 nid=0x48ec waiting on condition [0x00007f32db600000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x0000000089d717a8> (a java.util.concurrent.SynchronousQueue$TransferStack) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:458) at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:362) at java.util.concurrent.SynchronousQueue.take(SynchronousQueue.java:924) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) |
这部分dubbo线程主要是因为从ThreadPoolExecutor取任务来执行时被挂起(309个线程),这些线程正常处理完第一个请求后,就会回到线程池等待新的请求。由于这里使用newFixedThreadPool作为dubbo请求处理池,因此每个新请求默认都会创建新线程来处理,除非达到池的限定值。只有达到线程池最大线程数量,新的请求来临才会被加入任务队列,哪些阻塞在getTask()的线程才会得到复用。
-
此外,还有大量dubbo线程处于BLOCKED状态,看日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | "DubboServerHandler-172.24.16.78:33180-thread-236" #1727 daemon prio=5 os_prio=0 tid=0x00007f336403b000 nid=0x4b8b waiting for monitor entry [0x00007f32d58a4000] java.lang.Thread.State: BLOCKED (on object monitor) at org.apache.logging.log4j.core.appender.rolling.RollingFileManager.checkRollover(RollingFileManager.java:149) - waiting to lock <0x0000000085057998> (a org.apache.logging.log4j.core.appender.rolling.RollingRandomAccessFileManager) at org.apache.logging.log4j.core.appender.RollingRandomAccessFileAppender.append(RollingRandomAccessFileAppender.java:88) at org.apache.logging.log4j.core.config.AppenderControl.tryCallAppender(AppenderControl.java:155) at org.apache.logging.log4j.core.config.AppenderControl.callAppender0(AppenderControl.java:128) at org.apache.logging.log4j.core.config.AppenderControl.callAppenderPreventRecursion(AppenderControl.java:119) at org.apache.logging.log4j.core.config.AppenderControl.callAppender(AppenderControl.java:84) at org.apache.logging.log4j.core.config.LoggerConfig.callAppenders(LoggerConfig.java:390) at org.apache.logging.log4j.core.config.LoggerConfig.processLogEvent(LoggerConfig.java:375) at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:359) at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:349) at org.apache.logging.log4j.core.config.AwaitCompletionReliabilityStrategy.log(AwaitCompletionReliabilityStrategy.java:63) at org.apache.logging.log4j.core.Logger.logMessage(Logger.java:146) at org.apache.logging.log4j.spi.AbstractLogger.logMessage(AbstractLogger.java:1993) at org.apache.logging.log4j.spi.AbstractLogger.logIfEnabled(AbstractLogger.java:1852) at org.apache.logging.slf4j.Log4jLogger.info(Log4jLogger.java:179) at com.alibaba.dubbo.common.logger.slf4j.Slf4jLogger.info(Slf4jLogger.java:42) at com.alibaba.dubbo.common.logger.support.FailsafeLogger.info(FailsafeLogger.java:93) at com.dianwoba.universe.dubbo.filter.ResponseFilter$1.run(ResponseFilter.java:116) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) |
waiting for monitor entry :说明当前线程正处于EntryList队列中,等待获取监视器锁。
说明:Java中synchronized的同步语义主要基于Java对象头和monitor实现,每个monitor同一时间只能由一个线程拥有,其他想要获取该monitor只能等待,其中monitor具有两个队列:WaitSet 和 EntryList。当某个线程在拥有monitor时,调用了Object.wait(),则会释放monitor,进入WaitSet队列等待,此时线程状态为WAITING,WaitSet中的等待的状态是 “in Object.wait()”。当其他线程调用Object的notify()/notifyAll()唤醒该线程后,将会重新竞争monitor;当某个线程尝试进入synchronized代码块或方法时,获取monitor失败则会进入EntryList队列,此时线程状态为BLOCKED,EntryList中等待的状态为“waiting for monitor entry”。
根据jstack日志,有377个dubbo线程在等待锁定资源“0x0000000085057998”,从堆栈可知,这些线程都在竞争RollingRandomAccessFileManager的monitor,让我们看看那个线程拥有了该监视器,看日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | "DubboServerHandler-172.24.16.78:33180-thread-429" #553 daemon prio=5 os_prio=0 tid=0x00007f339c09f800 nid=0x4467 waiting for monitor entry [0x00007f331f53a000] java.lang.Thread.State: BLOCKED (on object monitor) at org.apache.logging.log4j.core.appender.rolling.RollingFileManager.checkRollover(RollingFileManager.java:149) - locked <0x0000000085057998> (a org.apache.logging.log4j.core.appender.rolling.RollingRandomAccessFileManager) at org.apache.logging.log4j.core.appender.RollingRandomAccessFileAppender.append(RollingRandomAccessFileAppender.java:88) at org.apache.logging.log4j.core.config.AppenderControl.tryCallAppender(AppenderControl.java:155) at org.apache.logging.log4j.core.config.AppenderControl.callAppender0(AppenderControl.java:128) at org.apache.logging.log4j.core.config.AppenderControl.callAppenderPreventRecursion(AppenderControl.java:119) at org.apache.logging.log4j.core.config.AppenderControl.callAppender(AppenderControl.java:84) at org.apache.logging.log4j.core.config.LoggerConfig.callAppenders(LoggerConfig.java:390) at org.apache.logging.log4j.core.config.LoggerConfig.processLogEvent(LoggerConfig.java:375) at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:359) at org.apache.logging.log4j.core.config.LoggerConfig.logParent(LoggerConfig.java:381) at org.apache.logging.log4j.core.config.LoggerConfig.processLogEvent(LoggerConfig.java:376) at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:359) at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:349) at org.apache.logging.log4j.core.config.AwaitCompletionReliabilityStrategy.log(AwaitCompletionReliabilityStrategy.java:63) at org.apache.logging.log4j.core.Logger.logMessage(Logger.java:146) at org.apache.logging.log4j.spi.AbstractLogger.logMessage(AbstractLogger.java:1993) at org.apache.logging.log4j.spi.AbstractLogger.logIfEnabled(AbstractLogger.java:1852) at org.apache.logging.slf4j.Log4jLogger.warn(Log4jLogger.java:239) at com.alibaba.dubbo.common.logger.slf4j.Slf4jLogger.warn(Slf4jLogger.java:54) at com.alibaba.dubbo.common.logger.support.FailsafeLogger.warn(FailsafeLogger.java:107) at com.alibaba.dubbo.rpc.filter.TimeoutFilter.invoke(TimeoutFilter.java:48) at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91) at com.alibaba.dubbo.rpc.protocol.dubbo.filter.TraceFilter.invoke(TraceFilter.java:78) at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91) at com.alibaba.dubbo.rpc.filter.ContextFilter.invoke(ContextFilter.java:60) at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91) at com.alibaba.dubbo.rpc.filter.GenericFilter.invoke(GenericFilter.java:112) at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91) at com.alibaba.dubbo.rpc.filter.ClassLoaderFilter.invoke(ClassLoaderFilter.java:38) at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91) at com.alibaba.dubbo.rpc.filter.EchoFilter.invoke(EchoFilter.java:38) at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91) at com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol$1.reply(DubboProtocol.java:108) at com.alibaba.dubbo.remoting.exchange.support.header.HeaderExchangeHandler.handleRequest(HeaderExchangeHandler.java:84) at com.alibaba.dubbo.remoting.exchange.support.header.HeaderExchangeHandler.received(HeaderExchangeHandler.java:170) at com.alibaba.dubbo.remoting.transport.DecodeHandler.received(DecodeHandler.java:52) at com.alibaba.dubbo.remoting.transport.dispatcher.ChannelEventRunnable.run(ChannelEventRunnable.java:82) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) |
看到该线程的堆栈就一脸懵b了,它已经锁定了资源“0x0000000085057998”,但仍然处于BLOCKED状态,是不是有死锁的味道?但是这里不是死锁,最可能的原因是:
-
线程没有获得运行所需的资源;
-
JVM正在进行fullGC
从这部分日志可知,大部分线程阻塞在打印监控日志的过程中,所以很多请求出现超时。主要原因可能是CPU占用率高,持有锁的线程处理过程非常慢,导致越来越多的线程在锁竞争中被阻塞,整体性能下降。
到此,仍然没有找到问题的原因,再一次观察资源占用情况,发现当出现问题时,内存占用持续增长,且无下降痕迹,然后找运维dump了一份GC日志,发现JVM一直在做fullGC,而每次GC之后内存基本没变化,说明程序中发生了内存泄漏。最后定位到发生内存泄漏的地方是一个分页查询接口,SQL语句中漏掉了limit,offset,够初心大意了。
这尼玛一次性将整张表的数据查出来(300万),还要对300万记录循环处理一遍,这内存不爆掉就怪了。正是因为该原因,导致内存长时间没有释放,JVM执行fullGC无法回收内存,导致持续做fullGC,CPU被耗尽,无法处理应用请求。
综上,罪魁祸首是发生了内存泄漏,JVM一直做fullGC,导致CPU突然飙升,Dubbo活动线程数增大,锁竞争严重,请求处理超时。根据以上分析,同时也暴露了另外一个不合理的问题:dubbo线程池数量配置过大,最大值为1500,也就是说最终线程池中会有1500个线程来处理用户请求,当并发量高时,活动线程数增加,CPU频繁进行上下文切换,系统的吞吐率并不会太高。这是一个优化点。
本文记录该过程,一方面是为了记录曾经踩过的坑,同时提高自己的故障分析和处理能力。当需要问题时,一定不要着急,学会分析问题,一步步找到问题所在。尤其是遇到线上问题时,由于无法调试,一定要在应用中做监控,当出现问题时,一定要结合日志来分析,业务中的问题结合业务日志,性能问题结合内存dump日志和线程dump日志等等。
欢迎指出本文有误的地方!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-07-03 java获取当前时间戳的方法
2018-07-03 Java中float/double取值范围与精度
2018-07-03 Java 中int、String的类型转换
2018-07-03 Java中的static关键字解析
2018-07-03 Spring Boot 属性配置&自定义属性配置
2018-07-03 Appendix A. Common application properties
2018-07-03 分布式之延时任务方案解析(转载)