

分布式系统的阿喀琉斯之踵:数据一致性
附录: 原文地址
为什么需要分布式系统?
任何事物能够被持续的运用和发展,必然有其价值,分布式系统也是一样。分布式系统的产生我认为主要的目的就是“快”和“海量”。
这个“快”可以分为两个方面:
-
第一个是系统的处理速度快。
-
第二个是开发的速度快(历时短)。
这2点本质都是相同的,把一个动作或者一件事情拆成两部分或者多个部分去同时进行,使得整体的耗时缩短。
比如:原本一件事情要一个人做的话要两分钟。那么我雇佣两个人帮我各自做一部分,那么最理想情况下一分钟就可以完成了。
当然这两个方面中第二项从某种意义上来说是可以克服的,但是第一项是无法克服的。因为没有一个程序或者说一台计算机,它的性能是无穷大的,如果有,那分布式系统也不会像现在这么普遍了(很多时候用钱能解决的问题都不是问题了)
“海量”则是由于不存在无穷大的硬盘,所以我们需要把数据分别存储到不同的硬盘上,才能满足需求。这些硬盘可能在不同主机、不同机房、不同地域,未来可能会在不同的星球吧。
02
分布式系统的副作用
所谓每个事物都是矛盾统一的结合体,都具有两面性。分布式系统再带来了前面提到的好处的同时,也带来了业界普遍认为最大的问题 —— 数据一致性问题。
系统是给人用的,构成使用场景的概念叫业务。
业务是核心,对一个系统来说,业务的发展归根到底是建立在数据之上的。我可以慢、可以宕机、可以搞得很复杂,这些都能忍,但唯独不能忍的就是数据问题,数据错误、数据不一致等等。
分布式就意味着分治与协作,一件事一个人只负责一部分。生活中这样的例子也无处不在.
就拿举办一个Party来说:一部分人去准备吃的,一部分人去准备喝的,一部分人去准备场地布置。
这些事情大家都可以同时进行,但是任一环节掉链子了,或者说不符合Party主题的话,都是失败的。(不知道为什么,脑子里浮现的是一场发布会,大家喊着cheers,一口干了高脚杯里的二锅头。。。![]() )。
)。
再举个电商场景中的程序案例:
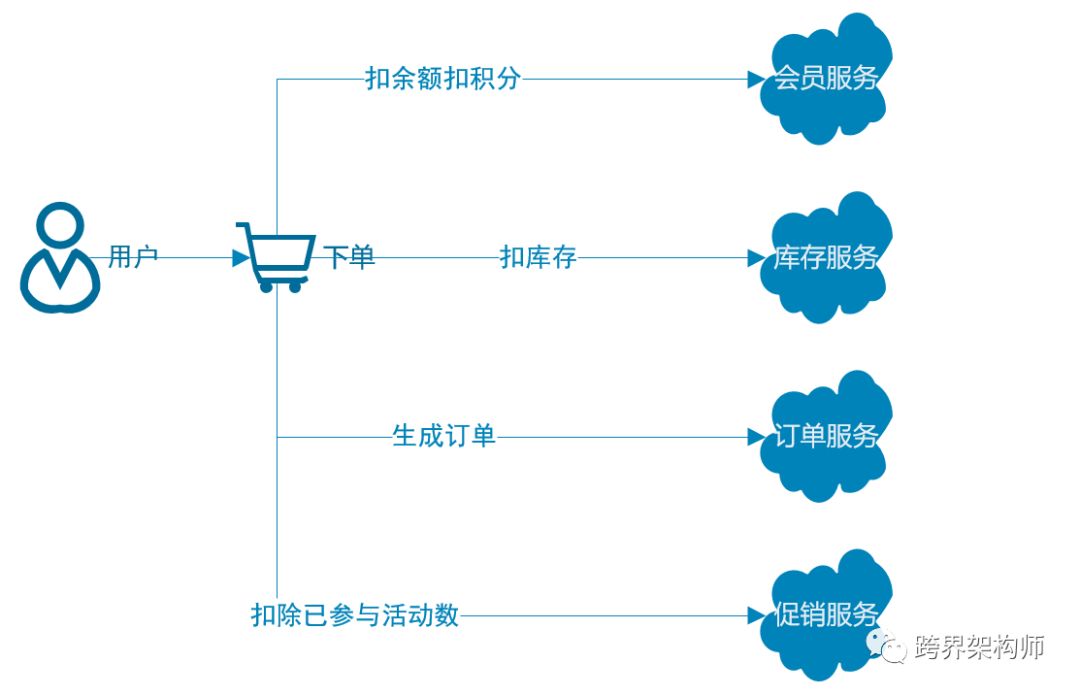
这里的4个操作以目标来看,其实先后顺序并不重要,重要的是要么都成功,要么都失败,其中任意一个程序不一致那么就会出问题。
这个问题本质上和人与人之间的沟通问题是类似的,之前写过一篇文章也专门聊过沟通问题,有兴趣的可以扩展阅读下:《就简单聊聊沟通效率问题》,上面的Party的例子也是这个道理。
与沟通唯一的不同在于,对程序来说,不一定都要得到响应,都没响应也是一致。
当一个事情分成100个部分去做的时候,很可怕,从概率的角度来看,达到一致的概率是2/5050。
这里举的程序例子并不是严谨,因为实际的分布式系统中因为除了“write”操作还有“read”操作,所以一致性问题比这个更复杂,后面会有更详细的说明。
03
产生数据不一致的原因
那么是什么原因导致了数据不一致的产生呢?
一是程序设计问题,或者说代码写错了。这点很好理解,也很容易想到解决方案,多做测试,验证是否符合预期咯。
常见的单元测试、接口测试、自动化测试、集成测试等等都是为了更具性价比的将BUG降低到无限接近于0,也造就了“测试工程师”这个岗位更大的作用。
但是,假设真的没有BUG,但还是会产生数据不一致,因为软件是运行在硬件之上的,所以还有硬件的因素存在。
并且对我们这里的大部分人来说,硬件相比软件,我们的掌控力更弱。这其中,最为严重的属网络问题,网络相比其它的来说是一个更大、更复杂的组织,未知性会随着局域网、广域网这样范围越大越严重。
想象一下,每一台主机仅仅是一张大网中的一个渺小的连接点,它所承载的链接越多越容易出现问题。
可能有的小伙伴会有疑问,其它像硬盘、电源断电什么的,也有出现问题的可能性,为什么网络问题最为严重呢?
其实硬盘、电源好比是你身体的一部分,如手和脚。而网络是人与人之间沟通的渠道,比如手机通话.虽然你没有主动挂断电话,但是整个通话过程是有很多可能性导致中断的,对方的主观意愿也好、信号不好也罢,甚至被第三者给拦截了。
相信大家也能认可,打电话出现异常的概率相比自己的手脚不听使唤是高很多的吧。
现实中网络的特点,常遇到的问题如:延迟、丢包、乱序等问题。
为了解决这些问题,从互联网第一次出现的1969年(当年美军在ARPA制定的协定下用网络连接了4所大学)到现在,几十年间出了很多的理论和解决方案,这些会在后续的文章中给大家一一做梳理。本文先和大家具体剖析下什么是一致性。
04
详解一致性
首先什么叫达成一致了?说起来很简单:
在任意时间、任意位置看到的同一个事物是完全一致的。
比如一场足球赛。我们不管在现场还是在电视机前,看到足球从球员A传给球员B,这个信息都是一样的。
但是严格意义上来说,这个并称不上真正的一致,因为电视机接收到这个信息需要经过卫星信号、网络等的传输,我们看到的时候相比现场的人肯定要晚。
哪怕在现场的人,根据他所处的位置理论上看到的信息也存在延迟差,只是因为光速非常快,使得在相差几百米之内,这个延迟小到完全感受不到而已。
能得出的结论是:在考虑时间维度的情况下,不存在真正意义上的一致。
况且我们在分布式系统中,也没有必要去达到真正的意义上的一致。
因为越趋近于一致,系统相当于又归一成一个单体了,在某一个时刻,只能做一件事,完全丧失了分布式系统的两个目的之一“快”的优势。也因此衍生出多种一致性的变种,分别适用于不同的场景。为了便于理解,我们从严格程度的低到高来说。
大多数情况下,为了尽可能的“快”,系统中使用的大部分方案都是所谓的最终一致性,也就容忍一定条件下的不一致,优先保证局部一致,然后再通过一系列复杂的状态同步达到全局的一致。
最终一致性很多可实现的分支,列出几种常见的,抛砖引玉一下:
-
因果一致性:仅要求有因果关系的操作顺序得到保证。比如朋友圈的回复功能。问“饭吃了吗?”肯定得在回答“吃了”之前。
-
读你所写一致性:文字看着别扭,但很好解释。比如你在朋友圈下面回复一句话,其它好友可以不用马上看到你的回复,但是你自己必须得马上看到,要不然回复到哪去了?
-
会话一致性:与人的一次聊天可以理解为一次会话。聊天虽然也有一定的因果关系,但是大部分场景下更多的是逻辑上的先后关系。
比如你阐述一个事情,分为3条信息:首先...,然后...,最后...。如果这里的一致性得不到保证那么可能会变成:最后...,首先...,然后...。
比局部一致更严格一些的就是全局的顺序一致性[附录1,1979年提出],保证所有进程看到的全局执行顺序一致,并且每个进程自身的执行顺序和实际发生顺序一致。
像上面提到的足球赛,比如实际发生的事情是
-
梅西把球传给了C罗
-
C罗又把球回传给了梅西,那么每个人看到顺序都应该是这样。
哪怕现场观众已经看到②了,电视机前的我们还没看到①,但是没关系,这个事情发生的顺序,对全世界来说都是一样的。
再严格一些,就是在全局的顺序一致性基础上再增加一个相对时间的一致性要求,业界称之为线性一致性[附录2,1990年提出]。
还是用上面梅西和C罗相互传球的例子来做个比喻,相当于梅西传出球给C罗之后,整个球场“暂停”了,要等所有在观看这场球赛的人都接收到这个传球信息之后,C罗才能做下一个回传。
这里需要一个上帝(全局时钟)来“暂停”。这是我们实际可以做到的极限了,满足这类要求的系统中,名气最大的就属Google的Spanner了。
对不同级别的一致性汇总概述如下:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-06-27 特色博客
2018-06-27 Linux上的free命令简介
2018-06-27 在 Java 8 中获取日期
2018-06-27 Mac 终端Terminal光标移动快捷键
2018-06-27 使用 AWK 來做垂直数字相加