
Raft
Typical Properties of Consensus Algorithms
1. safety: produce correct results under all non-Byzantine conditions
include network delays/partitions, packet loss/duplication/reordering
2. availability/liveness:
if majority of peers are operational and can communicate with each other and with clients assume failures are all fail stopping
3. safety should not depend on timing
do not require timing to ensure consistency
timing: faulty clocks or message delays
4. performance can not be affected by a minority of slow servers
Strengths and Weaknesses of Paxos
Strengths
1. It ensures safety and liveness
2. Its correctness is formally proved
3. It is efficient in the normal case (?)
Weaknesses
1. Difficult to understand
thus difficult to implement / reason about / debug / optimize ...
2. Does not provide a good foundation for building practical implementations
no widely agreed-upon algo. for multi-paxos
single-decree paxos -> multi-paxos is complex
leader-based protocols is simpler and may be faster for making a series of decisions
Brief Introduction to Raft
A consensus protocol with strong leader
Why leader?
simplifies the management of log replication
makes raft easier to understand
Raft log
orders commands
stores tentative commands until committed
stores commands in case leader must re-send to followers
acts as history of commands, can be replayed after server reboot
Leader Election
State of a server:
follower, candidate, leader
State transision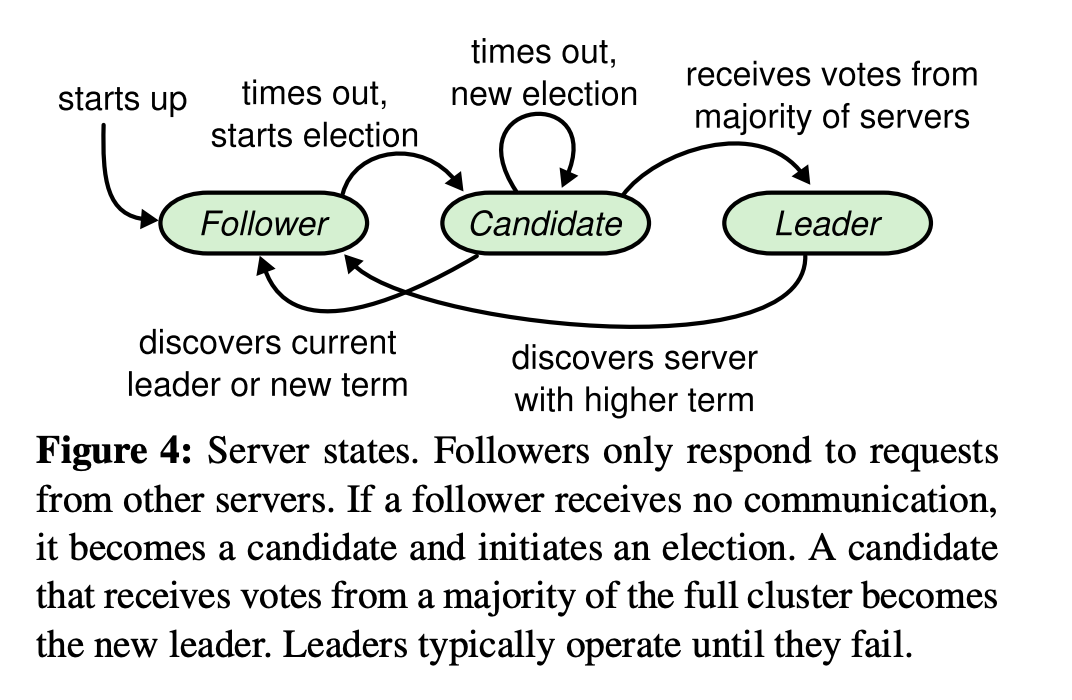
at most one leader can be elected in a given term
Timing requirement for steady leaders
broadcast time << election timeout << MTBF
broadcast time: 10s of ms, may depend upon log persistence performance
election timeout: 100s of ms (or 1s, 3s ...)
MTBF: months
How to choose election timeout
* at least a few (10s of) heartbeat intervals (in case network drops a heartbeat)
to avoid needless elections, which waste time and introduce availability issues
* random part long enough to let one candidate succeed before next starts
* short enough to react quickly to failure, avoid long pauses (availability issues)
Log Replication
Leader Append-only: leader never deletes or overwrites its log entries; it only append new entries
Log Matching: if two logs contain an entry with same index and same term, all log entries up through the given index are identical
Leader Completeness: : if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
Leader Election Resitriction
1. new leader must contain all log entries committed
example 1
index: 1 2 3
S1: 1 2 2 (leader)
S2: 1 2 2
S3: 1 1
S3 is leader of term 1, is partitioned away from S1 and S2
S1 broadcasts log entry with index 3, consider the following 3 cases:
#1: S2 receives the log entry but the reply to S1 is lost, S1 crashes
#2: S2 receives the log entry and replies, S1 commits the log entry and crashes
#3: S2 receives the log entry and replies, S1 and S2 commit the log entry, S1 crashes
After the partition heals, only S2 can be the leader.
If S3 becomes leader, it is possible that commited log entries will be overwritten
violates the Leader Completeness property
example 2
index: 1 2 3
S1: 1
S2: 1 ->
S3: 1 1 (leader)
index: 1 2 3
S1: 1 2
S2: 1 2 2 (leader) ->
S3: 1 1
index: 1 2 3
S1: 1 2 3 (leader)
S2: 1 2 2
S3: 1 1
S1 crashes and restarts, S1 and S2 can become leader of term 4, S3 can not.
2. new leader's log must be at least as up-to-date as majority of servers
up-to-date
compare last entries. log has last entry with higher term is more up-to-date
if term of last entries are same. log which is longer is more up-to-date
Q: why not elect the server with the longest log as new leader?
A:
example:
S1: 5 6 7
S2: 5 8
S3: 5 8
first, could this scenario happen? how?
S1 leader in term 6; crash+reboot; leader in term 7; crash and stay down
both times it crashed after only appending to its own log
Q: after S1 crashes in term 7, why won't S2/S3 choose 6 as next term?
A: at least one of them votes for S1, and becomes follower in term 7
next term will be 8, since at least one of S2/S3 learned of 7 while voting
S2 leader in term 8, only S2+S3 alive, then crash
all peers reboot
who should be next leader?
S1 has longest log, but entry 8 could have committed !!!
so new leader can only be one of S2 or S3
i.e. the rule cannot be simply "longest log"
Raft Persistence
why log?
if a server was in leader's majority for committing an entry,
must remember entry despite reboot, so any future leader is
guaranteed to see the committed log entry
why votedFor?
to prevent a client from voting for one candidate, then reboot,
then vote for a different candidate in the same (or older!) term
could lead to two leaders for the same term
why currentTerm?
to ensure terms only increase, so each term has at most one leader
to detect RPCs from stale leaders and candidates
Q: What if we do not persist currentTerm and initialize currTerm of a server to term of its last log entry when it starts, give an example to show what could go wrong ?
A: Assume there is a raft group of three servers S1, S2 and S3. S1's last log entry has term 10. S1 receives a VoteRequest for term 11 from S2, and answers "yes". Then S1 crashes, and restarts. S1 initializes currentTerm from the term in its last log entry, which is 10. Now S1 receives a VoteRequest from S3 for term 11. S1 will vote for S3 for term 11 even though it previously voted for S2. There are two leaders S2 and S3 in term 11, which would lead to different peers committing different commands at the same index.
Q: What happens after all servers crash and restart at about the same time ?
A: An example:
S1, S2, S3
1. S1, S2, S3 all start as follower in currentTerm of their own, say 3, 2, 1. they voteFor S1, S1, S3 respectively
2. election timer elapses. one of them become candidate, say S2 becomes candidate of 2 + 1 = 3
3. S2 request votes from S1 and S3, S1 rejects to vote because it has voted for itself in term 3, S3 grants the vote and becomes follower of term 3
4. S2 becomes leader of term 3 and starts to broadcast heartbeats to S1 and S3
We can induce the states of S1, S2, S3 before the crash
S1 is candidate of term 3 and leader of term 2
S2 is follower of term 2
S3 is leader of term 1 and then is partitioned away from S1 and S2
A special case needs to take care (Figure 8 in the Raft paper)
index: 1 2 3
S1: 1 2
S2: 1 ->
S3: 1 3 (leader of term 3)
index: 1 2 3
S1: 1 2 4 (leader of term 4)
S2: 1 2
S3: 1 3
Although log entry at 2 is successflly replicated from S1 to S2, we can not simply commit the index. what if we do so, and S1 crashes, S3 will be leader of term 5, and will commit an entry with term 3 at index 2.
Commtting different entries at same index violates safty guarantee of Raft !!!
A leader should not commit log entries from older terms and it should only commits log entries of its own term. After S1 commits log entry at index 3 with term 4, log entry at index 2 is commited indirectly because of the Log Matching property.
Protocol for Cluster Membership Changes
[TBD]
TiKV Case Study
Solutions proposed in TiKV blog for fast linearizable reads over Raft (inspired by approaches mentioned in the Raft paper)
ReadIndex Read
when a read request comes in, the leader performs the following steps to serve the read:
1. ReadIndex = commitIndex
2. Ensure the leader is still leader by broadcasting heartbeats to peers
3. Wait apply of the log entry at ReadIndex
4. Handle the read request and reply to the client
Lease Read
Lease:
Assume that start is the time when the leader starts to broadcast AppendEntries to followers
after the leader get positive responses from majority, the leader holds a valid
lease which lasts till start + minimum_election_timeout / clock_drift_bound.
When the leader holds a vaild lease, it can perform read requests without writing anythong into the log
clock skew has no effect on the correctness of this approach
but clock that may jump back and forth does
See https://pingcap.com/blog/lease-read/ for more details
More on Replicated State Machine Protocols
Paxos / Viewstamped Replcation / SMART / ZAB / Raft ...
Single-decree paxos v.s. multi-decree paxos
[TBD]
Master-based Paxos has similiar advantages as Raft
1. The master is up-to-date and can serve reads of the current consensus state w/o network communication
2. Writes can be reduced to a single round of communication by piggybacking prepares to accept messages
3. The master can batch writes to improve throughput
Downside of master-based/leader-based prototol
1. Reading/writing must be done near the master to avoid accumulating latency from sequential requests.
2. Any potential master must have adequate resources for the system’s full workload slave replicas waste resources until the moment they become master.
3. Master failover can require a complicated state machine, and a series of timers must elapse before service is restored. It is difficult to avoid user-visible outages.
What will go wrong if Zookeeper uses Raft instead of ZAB as its consensus protocol ?
Zookeeper client submits requests in FIFO order and these requests must be committed in the same order. It can submit next request before preious request gets acknowledged.
[TBD]
References
The Raft Paper: https://raft.github.io/raft.pdf
A guide for implementing Raft: https://thesquareplanet.com/blog/students-guide-to-raft/
TiKV Blog: https://pingcap.com/blog/lease-read/
The Megastore Paper: http://cidrdb.org/cidr2011/Papers/CIDR11_Paper32.pdf

