Android中的XML解析
在安卓中主要有三种XML文档解析方式:DOM(Document Object Model), SAX(Simple API for XML), PULL
他们的主要特点如下表:
| 特点 | 主要类 | |
| DOM | 1 由于是把整个XML文档以文档树的形式加载到内存中,所以内存消耗多,不适合手机这种内存稀缺的设备 2 使用简单 3 由于是把整个文档加载入内存,因此内存消耗较大 |
Document:该接口定义分析并创建DOM文档的一系列方法,它是文档树的根,是操作DOM的基础。 Element:该接口继承Node接口,提供了获取、修改XML元素名字和属性的方法。 Node:该接口提供处理并获取节点和子节点值的方法。 NodeList:提供获得节点个数和当前节点的方法。这样就可以迭代地访问各个节点。 DOMParser:该类是Apache的Xerces中的DOM解析器类,可直接解析XML文件。 |
| SAX | 1 采用基于事件的回调方式,从文档开始读到文档结束,边解析边获取文档信息,内存消耗少 | SAXParserFactory:创建SAXParser; SAXParser:获取XMLReader XMLReader:从输入流中获取xml数据 DefaultHandler:处理解析事件,核心类,重写此类实现对xml数据的有效获取 |
| PULL | 安卓平台首选。与SAX方式差不多,都是基于事件驱动,但是用户可以对解析过程更好的控制,可以理解为解析过程是用户驱动(XmlPullParser.next())的。 | XmlPullParserFactory:创建XmlPullParser; XmlPullParser:从输入流中获取xml数据 |
由于在安卓中推荐使用PULL解析,下面说明使用PULL解析XML的主要内容。
- 获取XmlPullParser:
1 XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); 2 factory.setNamespaceAware(true); 3 XmlPullParser parser = factory.newPullParser();
- 设置XmlPullParser解析器的输入:
//XmlPullParser设置输入有两个方法: //XmlPullParser.setInput(Reader reader); //XmlPullParser.setInput(InputStream inputStream, String inputEncoding);
- 解析XML文档数据。其主要工作就是调用XmlPullParser.next()获取数据,然后在调用XmlPullParser.getEventType()得到当前解析状态再做相应处理。
//XmlPullParser.getEventType()返回的状态类型 //START_DOCUMENT:Parser初始化的状态 //START_TAG:一个XML节点的开始,即‘<’符号 //END_TAG:一个XML节点的结束,即‘</’符号 //TEXT:Text内容 //END_DOCUMENT:XML文档读取结束
注意:在编写XML的时候,若有缩进/换行等排版,则会把换行/缩进/空格等符号当做TEXT读取,返回TEXT状态。
测试实验:
在eclipse中编写如下xml文件:
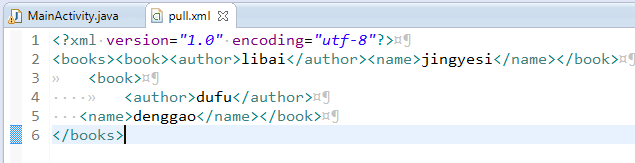
然后编写如下解析代码:只包含主要部分:
private void pullParseXml(){ XmlPullParserFactory factory = null; String name = ""; String author = ""; String tagName; try { factory = XmlPullParserFactory.newInstance(); factory.setNamespaceAware(true); XmlPullParser xpp = factory.newPullParser(); InputStream inputStream = getAssets().open("pull.xml"); xpp.setInput(inputStream, null); int eventType = xpp.getEventType(); while(eventType != XmlPullParser.END_DOCUMENT){ if(eventType == XmlPullParser.START_DOCUMENT){ log("START_DOCUMENT"); mBooks = new ArrayList<Book>(); }else if(eventType == XmlPullParser.START_TAG){ log("START_TAG:" + xpp.getName()); tagName = xpp.getName(); if("book".equals(tagName)){ name = ""; author = ""; } else if("author".equals(tagName)){ author = xpp.nextText(); log("author:" + author); } else if("name".equals(tagName)){ name = xpp.nextText(); log("name:" + name); } } else if(eventType == XmlPullParser.END_TAG){ log("END_TAG"); tagName = xpp.getName(); if("book".equals(tagName)){ mBooks.add(new Book(author, name)); } } else if(eventType == XmlPullParser.TEXT){ String textString = xpp.getText(); log("TEXT:" + textString); } eventType = xpp.next(); } mTv.setText(mBooks.get(0).getInfo()); } catch (Exception e) { // TODO: handle exception } } private void log(String s){ Log.d("TEST", s); if(s.startsWith("TEXT:")){ Log.d("TEST", "length:" + s.length()); for(int i = 5; i < s.length(); ++i){ Log.d("TEST", "end char value:" + Integer.valueOf(s.charAt(i))); } } }
然后得到的log如下:
02-28 05:26:55.395: D/TEST(2469): START_DOCUMENT
02-28 05:26:55.395: D/TEST(2469): START_TAG:books
02-28 05:26:55.395: D/TEST(2469): START_TAG:book
02-28 05:26:55.395: D/TEST(2469): START_TAG:author
02-28 05:26:55.395: D/TEST(2469): author:libai
02-28 05:26:55.395: D/TEST(2469): START_TAG:name
02-28 05:26:55.395: D/TEST(2469): name:jingyesi
02-28 05:26:55.395: D/TEST(2469): END_TAG
02-28 05:26:55.395: D/TEST(2469): TEXT:
02-28 05:26:55.395: D/TEST(2469):
02-28 05:26:55.403: D/TEST(2469): length:7
02-28 05:26:55.403: D/TEST(2469): end char value:10
02-28 05:26:55.403: D/TEST(2469): end char value:9
02-28 05:26:55.403: D/TEST(2469): START_TAG:book
02-28 05:26:55.403: D/TEST(2469): TEXT:
02-28 05:26:55.403: D/TEST(2469):
02-28 05:26:55.403: D/TEST(2469): length:11
02-28 05:26:55.403: D/TEST(2469): end char value:10
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): end char value:9
02-28 05:26:55.403: D/TEST(2469): START_TAG:author
02-28 05:26:55.403: D/TEST(2469): author:dufu
02-28 05:26:55.403: D/TEST(2469): TEXT:
02-28 05:26:55.403: D/TEST(2469):
02-28 05:26:55.403: D/TEST(2469): length:9
02-28 05:26:55.403: D/TEST(2469): end char value:10
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): end char value:32
02-28 05:26:55.403: D/TEST(2469): START_TAG:name
02-28 05:26:55.403: D/TEST(2469): name:denggao
02-28 05:26:55.403: D/TEST(2469): END_TAG
02-28 05:26:55.403: D/TEST(2469): TEXT:
02-28 05:26:55.403: D/TEST(2469): length:6
02-28 05:26:55.403: D/TEST(2469): end char value:10
02-28 05:26:55.403: D/TEST(2469): END_TAG
在ASCII码中,9,10,32分别表示的就是制表符,换行以及空格。从log中我们可以清晰的看到,XmlPullParser把为了排版而加入的换行,缩进,空格字符都当做TEXT解析了,并且触发了TEXT事件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号