


1.1 从访问网页开始
在探讨具体的技术原理之前,我们来搞清楚“网络通信”的定义:它是指媒体信息通过网络从一端传递到另外一端。媒体信息的内容主要是话音、文字、图片和视频图像。至于信息如何通过网络传递,例如:一个字符怎么变成电波信号,电波信号又如何在网络设备中传输和接收的。对于这些我们应用开发人员来说是不需要去深究的。而大家所要关心的是应用层面的东西,例如:通信双方是怎么联系起来的?通信的内容怎么表示才能使双方理解?当某一端出现故障以后,如何让另一端知道?
假设有一对热恋中的青年男女,GG约MM去看电影,下面是拨打电话的过程:
MM:喂
GG:喂(应答一下)
GG:亲爱的,今晚我们去看电影吧?
MM:好啊(应答一下)
。。。。。。
这里通话的两端是人在操作,人是有语言感知能力的,只要双方说的语言能使对方明白意思就行。如果通话的主体是电脑,则需要更严谨的定义,因为电脑并没有语言感知能力,它只能识别事先定义好的规则,这样才能理解对方的意思。例如:电脑在发出第一个“喂”的时候,要约定这个内容是什么类型(例如:通话准备),然后另一端再根据类型应答一下(例如:通话准备完毕)。所以通信的过程就是:请求-应答信息的往返过程。
很多人天天上网,可能从来没去琢磨上网的过程是怎么样的,因为这已成为生活的一部分,是想当然的事情。如果您能从技术角度分析上网的过程,就大致明白网络通信是怎么回事,而了解了通信原理以后,再去做网站、WEB应用开发就能很快上手了。接下来我们分析一般情况下的应用场景:
第1步:用户打开浏览器,并输入网址;
第2步:系统连接web服务器;
第3步:系统返回页面内容;
第4步:浏览器显示页面内容。
从使用者的层面来看,就是这简单的四步;假如用户给你提出了这样的需求,该怎么去进行下一步的技术架构分析呢?
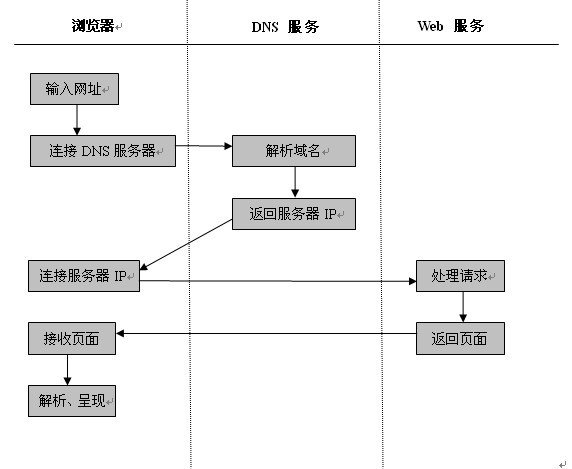
【图1-1 请求网页过程】
与用户使用场景相比,中间多了几步域名解析的过程。如果直接输入的是IP,这几个步骤就会省略。在互联网上,通常是以域名符号作为地址;而网络上的每个节点是以IP地址标识的,所以域名符号与IP地址要有个转换映射过程。这就是“域名解析服务”,简称DNS。DNS是由国际互联网组织提供的一种基础功能服务,域名解析时会按照DNS的树状结构逐级往上找,直到找到匹配的结果为止。接下来我们主要分析一下“浏览器”与“Web服务器”的交互细节:
浏览器需要解析、呈现的内容是什么?把文字、图片、视频等按照HTML语法规则来组织的内容形式,简称HTML页面。浏览器要负责解释网页上的HTML语法,所以它就起到一个语法解释的作用,是一个网页脚本的解释引擎。但Web服务器是怎么把用户需要的HTML页面传递到客户端的呢?在传递的过程中,又是以什么形式表现的呢?这里就出现了一个HTTP协议,它负责对HTML页面内容封包,然后通信双方根据协议进行请求应答。HTTP协议只是整个网络协议族里面的一种应用协议。
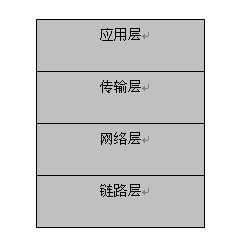
【图1-2 TCP/IP协议栈】
逻辑上,发送的数据流会沿着这个栈自上向下传递,相反的接收数据流也会自下向上传递。在浏览器请求数据的时候,Web服务器首先读取指定位置的HTML文件,然后层层对数据流封包,加上头部或尾部【参见第三章的TCP/IP协议】,直到发送出去。接收方负责层层解包,到了应用层后,只包含HTTP协议头和网页内容的数据流了;然后浏览器根据协议头里面的类型来区分网页的内容、格式等属性【参考 HTTP协议的定义】。
客户端(浏览器)与Web服务器交互的时候,传递的是基于HTTP协议的HTML数据包。每打开一个页面,都是一次新的请求,也就是每次请求都是独立的,不同的请求没有上下文环境【Context】数据。如果某个应用系统需要把关键的数据【例如:用户名,订单号】在每次请求的时候都把它们传递到服务器端,以此进行某些操作的话。这个时候通常有两种做法:
1:存储在客户端(如:COOKIE技术);
2:存储在服务器端(SESSION, APPLICATION技术)。
假如选择在客户端存储,那么每次需要把数据放在HTTP协议的COOKIE属性,然后服务器端负责解析接收该属性值。如果存储在服务器端,就不需要每次传递这些数据,Web服务器要使用时直接从内存或其它存储系统读取。这两种方法区别如下:
| 方法 | 信息量大小 | 保持时间 | 应用范围 | 保存位置 |
| APPLICATION | 任意大小 | 这个应用程序的生命周期 | 所要用户 | 服务器端 |
| SESSION | 小量,简单的数据 | 用户活动时间 + 一段延迟时间(一般为 30分钟) | 单个用户 | 服务器端 |
| COOKIE | 小量,简单的数据 | | 单个用户 | 客户端 |
1.2 客户端—服务器编程模型
每个网络应用都是基于客户端—服务器模型的。根据这个模型,一个应用是由一个服务器进程和一个或多个客户端进程组成。服务器管理某种资源,并且通过操作这种资源来为它的客户端提供某种服务。例如,一个Web服务器管理了一组磁盘文件,它会在接收到客户端的请求后,进行检索和执行。FTP服务器就管理了一组磁盘文件,它会为客户端进行存储和检索。
客户端—服务器模型中的基本模型是事务,这个事务由四步组成:
1、 当一个客户端需要服务时,它向服务器发送一个请求。例如,当Web浏览器打开一个网页时,它就发送一个请求给Web服务器。
2、 服务器收到请求后,解释请求命令,并以适当的方式操作它的资源。例如,当Web服务器接收到浏览器发出的请求后,它读一个磁盘文件。
3、 服务器给客户端发送一个响应,并等待下一个请求。例如,Web服务器将文件内容发送给客户端。
4、 客户端收到响应并处理它。例如,当Web浏览器收到来自服务器的一个页面后,它就在屏幕上显示此页。
这里的客户端和服务器是逻辑上的概念,并不是物理机器,在操作系统里面表现的就是一个应用进程,它们可以同时运行在同一台主机或是不同的主机上。无论客户端和服务器是怎样映射到主机上的,客户端—服务器模型是相同的。
(待续)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述