Ubuntu20.04 或者Manjaro下安装Hadoop 2.9.2
ubuntu manjaro 上安装hadoop
首先使用虚拟机安装完ubuntu或者manjaro,下面使用的是ubuntu 20.04系统,Hadoop2.9.2
准备软件
- Hadoop 2.9.2
- openjdk-8-jre
- vim
- openssh-service
hadoop可以去官方下载
下载完成之后,进入linux系统
下面是步骤
更新系统软件
sudo apt update
更新完成之后,安装openjdk以及vim
sudo apt install vim
sudo apt install openjdk-8-jdk
安装完成vim,openjdk-8,openssh-service,以及下载完hadoop之后,下面的安装方法,ubuntu和manjaro都适用。
创建hadooop用户并且更改hadoop用户密码,使用自己的密码就可以。
//创建hadoop用户
sudo adduser hadoop
//更改hadoop用户密码
sudo passwd hadoop
以上的配置完成之后,使用hadoop用户
su - hadoop
切换成hadoop之后,设置ssh免密登录
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 640 ~/.ssh/authorized_keys
然后试试ssh localhost,查看是否能够免密登录
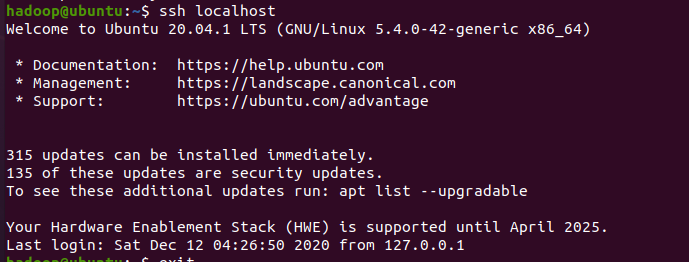
如果遇到22端口被拒绝的情况,很有可能是ssh服务并没有开启。
切换成exit退出当前用户,使用主用户
输入sudo service ssh start进行服务的开启。如果显示没有该服务,那么可以确定系统并没有安装ssh服务,去安装服务。
完成这些之后,把下载的Hadoop安装包复制到hadoop的家目录

然后开始解压到本目录
tar -zxvf hadoop-2.9.2.tar.gz
解压完成之后,修改一下hadoop目录的名称。
mv hadoop-2.9.2 hadoop
修改bash的配置信息
vim .bashrc
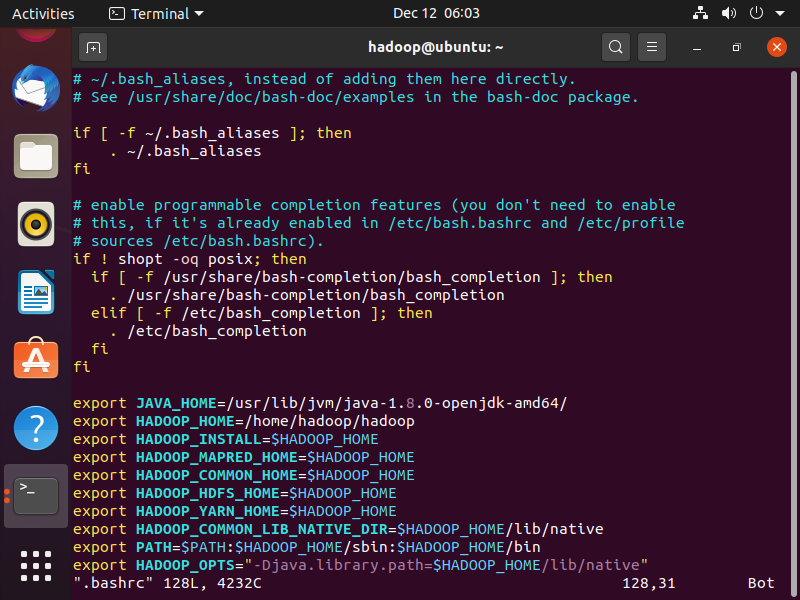
然后把信息复制到最下面的地方
# JAVA_HOME对应你自己的java home路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64/
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
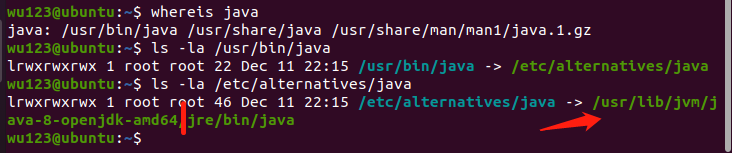
怎样看java home路径?
输入whereis java
找到找到路径之后,使用ls -la一个个进行查找,下面的图片就是查找的过程
找到之后,更改为自己的java home目录即可
完成配置之后,使用source .bashrc更新即可

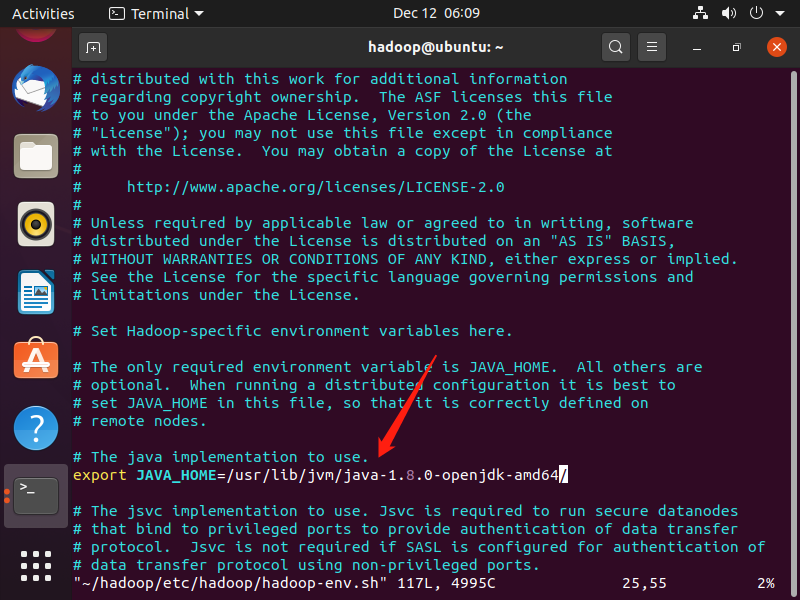
更新hadoop的JAVA_HOME路径vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh

更改java路径为
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64/
更改完之后,创建两个目录
mkdir -p ~/hadoopdata/hdfs/namenode
mkdir -p ~/hadoopdata/hdfs/datanode
然后更改几个文件
core-site.xmlhdfs-site.xmlmapred-site.xml-
这个文件需要复制,
cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml yarn-site.xml
vim使用方法:
- i,a 触发编辑模式
- esc 触发命令行模式
- :wq保存并退出
- :wq!强制保存并退出
- :q!强制退出,不保存
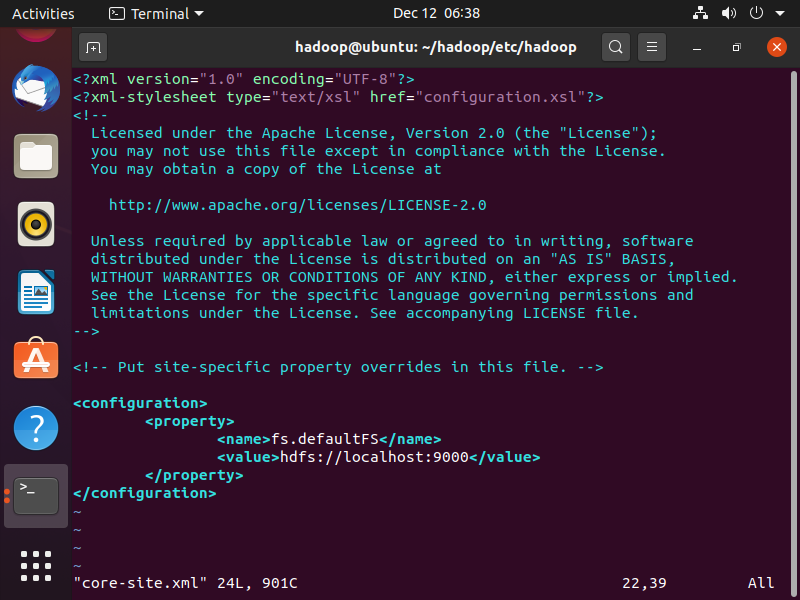
core-site.xml文件
vim $HADOOP_HOME/etc/hadoop/core-site.xml
core-site.xml文件的添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
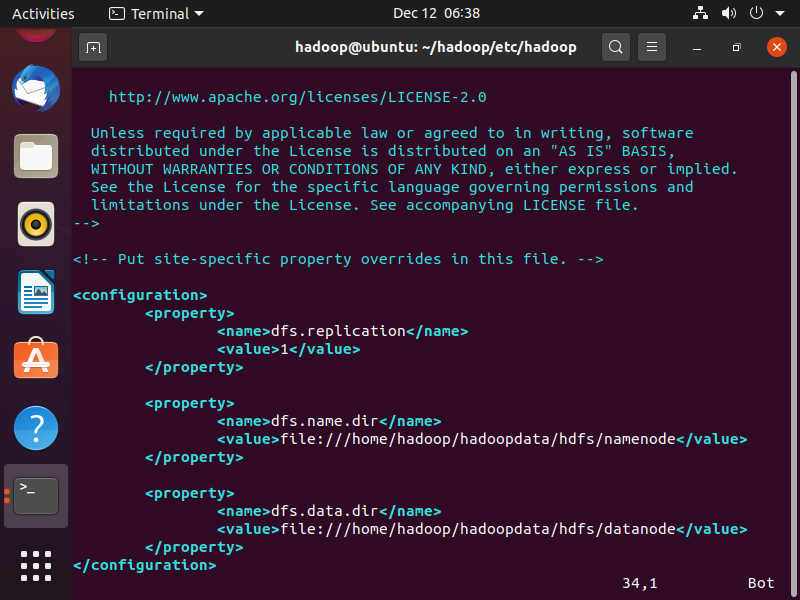
hdfs-site.xml文件
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
hdfs-site.xml文件添加内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
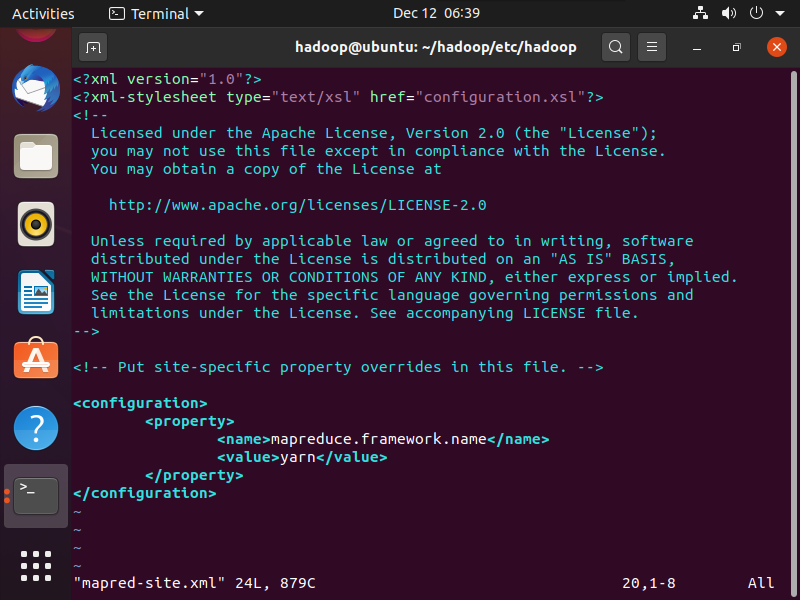
mapred-site.xml文件
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
mapred-site.xml 文件添加内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml文件
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
yarn-site.xml 文件添加内容如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
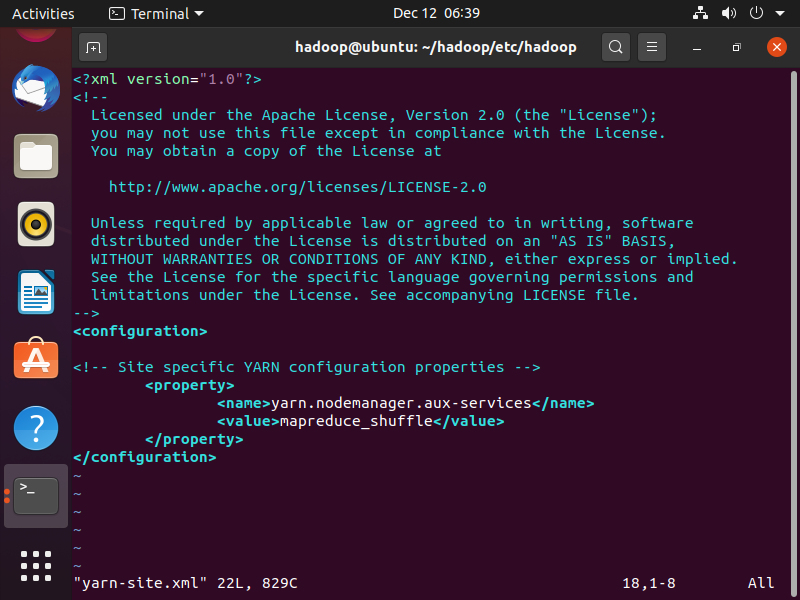
完成之后,格式化节点信息
hdfs namenode -format
如果你的输出是以下信息,那就证明你初始化成功了
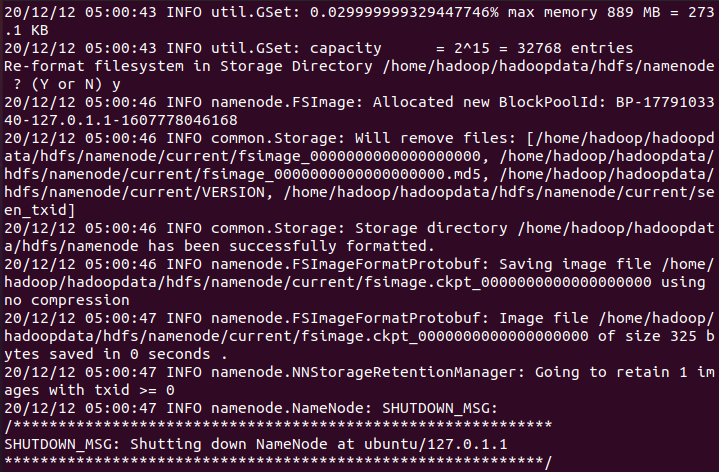
然后启动dfs
start-dfs.sh
启动后的截图:

最后启动yarn
start-yarn.sh
启动成功截图如下

最后,在控制台中输入jps,应该会出现以下进程名称
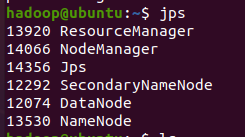
这样,你就成功地进行配置了hadoop
http://localhost:50070可以查看NameNode 和 Datanode 信息
参考这篇文章
有些地方行不通,进行了一定的修改。

