python开发学习笔记之六(面向对象)
面向对象引入:
现在有一个这样的需求:做汽水。
在之前的学习中,我们怎样处理这种类似的问题呢?思考一下,哦,不就是分步骤做嘛,把复杂的问题简单化,分成一个一个的步骤,就像机器人,流水线一样,先干什么后干什么,然后干什么,最后再干什么。于是这个问题就可以分解成这几个步骤:
制作汽水瓶———制作汽水————把汽水灌入汽水瓶————封口————贴标签————打包装箱
这就是一套完整的汽水制作生产线,这就是典型的面向过程的程序设计思路。
面向过程的优缺点:
优点:复杂问题流程化,进而简单化。将问题分解成步骤,逐个步骤进行处理
缺点:针对性太强,一套方法只适用于一种需求,代码的可重用性太低,只适用于一些一旦写好不进行修改的场景。
而面向对象是站在上帝角度来看待问题,上面做汽水的流水线,就可以看做是一个对象。这个对象可以做汽水瓶,可以做汽水,可以灌装,等等一系列的操作。
对象的概念就是:特征与技能的结合体(人就是个对象,人有名字年龄性别,这是特征;人会吃饭睡觉学习,这是技能。)
面向对象的优缺点:
优点:提高了代码的扩展性,对某个对象进行修改,可以影响到整个代码体系
缺点:编程的复杂度提高,无法准确地预测最终结果。 适用于需求不断变化的场景
类与对象:
类即类别、种类,是面向对象设计最重要的概念,对象是特征与技能的结合体,而类则是一系列对象相似的特征与技能的结合体
现实世界中,先有对象,后有类:


#在现实世界中,站在老男孩学校的角度:先有对象,再有类 对象1:李坦克 特征: 学校=oldboy 姓名=李坦克 性别=男 年龄=18 技能: 学习 吃饭 睡觉 对象2:王大炮 特征: 学校=oldboy 姓名=王大炮 性别=女 年龄=38 技能: 学习 吃饭 睡觉 对象3:牛榴弹 特征: 学校=oldboy 姓名=牛榴弹 性别=男 年龄=78 技能: 学习 吃饭 睡觉 现实中的oldboy学生类 相似的特征: 学校=oldboy 相似的技能: 学习 吃饭 睡觉
在程序中,先定义类,后实例化出对象:
class Student: school = 'oldboy' # 相同的特征 def __init__(self, name, age, sex) # 各自的特征 self.name = name self.age = age self.sex = sex def eat(self): # 相似的技能 print('eating...') def learn(self): print('learning...') def sleep(self) print('sleeping...')
上面的代码就是定义了一个学生类
获得对象就是通过类实例化出来
stu1 = Student('zhangsan','18,'男')
类的使用:
定义Student类:
class Student: school='oldboy' def learn(self): print('is learning') def eat(self): print('is eating') def sleep(self): print('is sleeping')
# 查看类的名称空间
Student.__dict__
查看类中的属性:
Student.__dict__['school'] 就可以获得类的数据属性,python 专用的属性访问方法是 Student.school
设置类中的属性:
增加属性:Student.county = 'China' 修改属性:Student.school = 'OLDBOY'
删除类中的属性:
del Student.school
对象的使用:
先生成三个对象:
stu1 = Student()
stu2 = Student()
stu3 = Student()
这三个学生对象都有相同的学校和相同的技能,但是这三名学生也有各自独有的属性:姓名,年龄,性别,那么怎么个性化定制每个学生的信息呢?
这就用到了类内部的__init__方法,它在实例化出对象时就会执行,给对象创建出各自不同的属性
# 定义类
class Student: school = 'oldboy' def __init__(self, name, age, sex): # 为对象定制各自的数据属性 self.Name = name self.Age = age self.Sex = sex def eat(self): print('is eating...') def learn(self): print('is learning...') def sleep(self): print('is sleeping...')
# 实例化对象
stu1 = Student('zhangsan',18,'male')
它实例化的具体步骤是:先产生一个空对象,再通过__init__方法给空对象添加属性
查看对象的属性:
stu1.name
stu1.learn()
设置对象的属性:
增加属性:stu1.class_name = 'python开发' 修改属性:stu1.name = 'lisi'
删除对象的属性:
del stu1.name
注意:在类中的数据属性是所有对象所直接共有的,是同一个id;而类中的函数属性是分别绑定到每个不同的对象,是不同的id.
当通过类调用类内部的方法时需要把对象当做参数传入函数:
Student.learn(stu1)
当实例化出一个对象时,对象会绑定类内的函数为对象自己的绑定方法。实际上,类内的函数属性就是给对象使用的
而通过对象来调用自己的绑定方法时,会自动把对象传入函数当做参数(谁来调用,就把谁当做参数传入函数):
stu1.learn()
查找属性会先从对象自己内部查找属性,如果对象内部没有这个属性,就会从这个对象的类里去查找属性,类似与函数的局部变量与全局变量
补充:
1.站的角度不同,定义的类也不同
2.编程中可能定义现实生活中不存在的类,比如关系类,策略类等等
ps: python中一切皆对象,在python3中统一了类与类型的概念
练习一:
编写学生类,实例化一些学生对象,并加上计数器(属性),统计实例化的对象个数:
class Student: # 生成学生类 school = 'oldboy' count = 0 # 生成计数器 def __init__(self, name, age, sex): self.Name = name self.Age = age self.Sex = sex Student.count += 1 # 每实例化一个对象把类的计数器加一 def eat(self): print('is eating...') def learn(self): print('is learning...') def sleep(self): print('is sleeping...') stu1 = Student('zhangsan', 18, 'male') stu2 = Student('lisi', 28, 'female') stu3 = Student('wangwu', 38, 'male') print(Student.count)
练习二:
模仿LOL,生成游戏角色对象,角色可以互相攻击
class Garen: # 定义盖伦类 def __init__(self, nickname, hp, ap): self.nickname = nickname self.hp = hp self.ap = ap def attack(self, enemy): enemy.hp -= self.ap class Reven: # 定义瑞文类 def __init__(self, nickname, hp, ap): self.nickname = nickname self.hp = hp self.ap = ap def attack(self, enemy): enemy.hp -= self.ap g = Garen('草丛伦', 500, 30) r = Reven('瑞雯雯', 300, 50) print('r', r.hp) g.attack(r) print('r', r.hp)
看一下上面的代码,你会发现两个类内部的代码是一模一样的,那么如果再需要定义其他角色就要重复写同样的代码,怎么解决代码重复性的问题呢?
这就需要了解一个概念:
继承:
继承指的是类与类之间的关系,是一种什么“是”什么的关系,继承的功能之一就是用来解决代码重用问题
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可以成为基类或超类,新建的类称为派生类或子类
class Hero: def __init__(self, nickname, hp, ap): self.nickname = nickname self.hp = hp self.ap = ap def attack(self, enemy): enemy.hp -= self.ap class Garen(Hero): pass class Reven(Hero): pass g = Garen('草丛伦', 500, 30) r = Reven('瑞雯雯', 300, 50) print('r', r.hp) g.attack(r) print('r', r.hp)
上面的代可以写成这种形式,两个角色类可以继承英雄类,从而提高了代码的复用性。
单继承与多继承
在python中可以继承多个父类:
class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass pass class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 pass
查看继承关系:
SubClass1.__bases__
有了继承关系,通过对象去查找属性是就是这样:
对象本身——对象的类————类的父类——...
一层一层的查找,找到就不往上找了
派生:
子类也可以添加自己新的属性或者在自己这里重新定义这些属性(不会影响到父类),需要注意的是,一旦重新定义了自己的属性且与父类重名,那么调用新增的属性时,就以自己的属性为准。
class Riven(Hero): camp='Noxus' def attack(self,enemy): #在自己这里定义新的attack,不再使用父类的attack,且不会影响父类 print('from riven') def fly(self): #在自己这里定义新的 print('%s is flying' %self.nickname)
继承的实现原理
当定义一个类时,python会为这个类生成一个方法解释顺序mro列表,为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如果继承了多个父类,那么属性的查找方式有两种,分别是:深度优先和广度优先
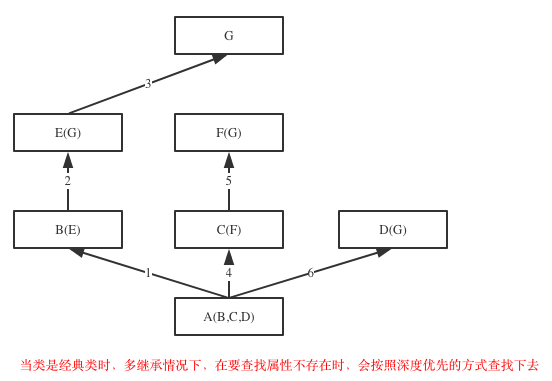

在python3中所有的类都是新式类,新式类就是在不指定继承关系的情况下,默认继承object类。在一系列的继承之后,最顶端的父类必然是object类
接下来思考一个问题,如果想在子类中想复用一下父类的方法,需要怎么办呢?
比如:
class Hero: def __init__(self, nickname, hp, ap): self.nickname = nickname self.hp = hp self.ap = ap def attack(self, enemy): enemy.hp -= self.ap
class Garen(Hero): def attack(self, enemy): #<---在这里重用父类的攻击方法 print('Garen attack!') pass
class Reven(Hero): pass g = Garen('草丛伦', 500, 30) r = Reven('瑞雯雯', 300, 50)
那么你可能会想到下面这种方法:
class Hero: def __init__(self, nickname, hp, ap): self.nickname = nickname self.hp = hp self.ap = ap def attack(self, enemy): enemy.hp -= self.ap class Garen(Hero): def attack(self, enemy): Hero.attack(self, enemy) #<---在这里重用父类的攻击方法 print('Garen attack!') pass class Reven(Hero): pass g = Garen('草丛伦', 500, 30) r = Reven('瑞雯雯', 300, 50)
这种就是指名道姓的调用方法,不依赖于继承关系
第二种就是依赖于继承关系的 super() 方法:
class Hero: def __init__(self, nickname, hp, ap): self.nickname = nickname self.hp = hp self.ap = ap def attack(self, enemy): enemy.hp -= self.ap class Garen(Hero): def attack(self, enemy): super().attack(enemy) #<---在这里重用父类的攻击方法 print('Garen attack!') pass class Reven(Hero): pass g = Garen('草丛伦', 500, 30) r = Reven('瑞雯雯', 300, 50)
组合:
组合指的就是是在一个类里以另一个类中的对象为数据属性,也就是什么“有”什么的关系:
举个上文中的例子:
>>> class Equip: #武器装备类 ... def fire(self): ... print('release Fire skill') ... >>> class Riven: #英雄Riven的类,一个英雄需要有装备,因而需要组合Equip类 ... camp='Noxus' ... def __init__(self,nickname): ... self.nickname=nickname ... self.equip=Equip() #用Equip类产生一个装备,赋值给实例的equip属性 ... >>> r1=Riven('锐雯雯') >>> r1.equip.fire() #可以使用组合的类产生的对象所持有的方法 release Fire skill
组合与继承都是有效地利用已有类的资源的重要方式。但是二者的概念和使用场景皆不同,
1.继承的方式
通过继承建立了派生类与基类之间的关系,它是一种'是'的所属关系,比如白马是马,人是动物。
当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好,比如老师是人,学生是人
2.组合的方式
用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的拥有关系,比如教授有生日,教授教python和linux课程,教授有学生s1、s2、s3...
抽象类与归一化:
抽取子类比较相像的部分,统一规范类中的属性调用方法,这用到了一个叫 abc 的模块
import abc class Animal(metaclass=abc.ABCMeta): @abc.abstractmethod def run(self): pass @abc.abstractmethod def eat(self): pass class People(Animal): pass class Pig(Animal): def run(self): print('pig is runing') def eat(self): print('pig is eating') pig1 = Pig() peo1 = People()
当People类没有用抽象类规范的方法时就会报错。通过抽象类实现了归一化的作用。
多态与多态性:

