在eclipse中运行spark examples(二)
在eclipse中运行spark examples(二)
package org.apache.spark.examples.streaming;
JavaCustomReceiver
编写辅助测试代码如下。
package tw;
import java.io.IOException; import java.io.PrintWriter; import java.net.InetSocketAddress; import java.net.ServerSocket; import java.net.Socket;
public class SocketServer {
public static void main(String[] args) throws IOException, InterruptedException { @SuppressWarnings("resource") ServerSocket ss = new ServerSocket(); ss.bind(new InetSocketAddress("localhost", 9999)); while(true){ Socket socket = ss.accept(); new Thread(new Runnable(){
@Override public void run() { try { PrintWriter pw; pw = new PrintWriter(socket.getOutputStream()); while(true){ pw.println("hello world"); pw.println("hello ls"); pw.println("hello ww"); pw.println("who lili"); pw.println("are zz"); pw.println("you"); pw.println("bye"); pw.println("hello world"); pw.println(); pw.flush(); Thread.sleep(500); } } catch (IOException | InterruptedException e) { e.printStackTrace(); } }}).start(); } }
} |
右键SocketServer.java,Run as /Java application
右键点击JavaCustomReceiver.java,Run as/Java application
再次右键点击JavaCustomReceiver.java,Run as/Run configuration
添加参数localhost 9999
在代码中添加参数spark.master=local
// Create the context with a 1 second batch size SparkConf sparkConf = new SparkConf() .setAppName("JavaCustomReceiver"); sparkConf.set("spark.master","local"); |
右键点击JavaCustomReceiver.java,Run as/Java application
运行结果
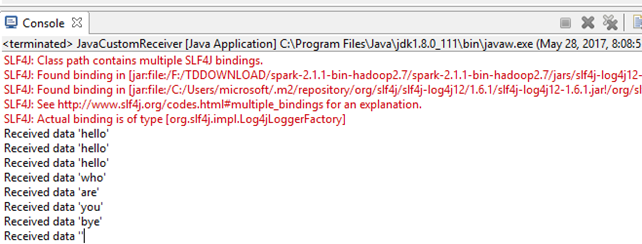
JavaDirectKafkaWordCount
添加kafka和zookeeper的maven依赖,添加kafka的依赖
<!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper --> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.8</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka_2.10 -->
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.10.2.1</version> </dependency> |
下载kafka和zookeeper的配置文件
/etc/kafka1/conf/server.properties /etc/zookeeper/conf/zoo.cfg
|
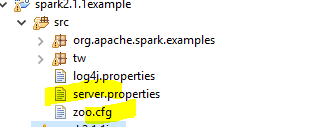
修改server.properties :
listeners=PLAINTEXT://localhost:9092
advertised.listeners=PLAINTEXT://localhost:9092
log.dirs=D:/hadoop/kmq
zookeeper.connect=localhost:2181
运行tw.kfksvr.KfkSvr
package tw.kfksvr;
import java.io.File; import java.io.IOException; import java.util.Properties;
import kafka.server.KafkaConfig; import kafka.server.KafkaServerStartable;
import org.apache.commons.io.FileUtils; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.zookeeper.server.ServerConfig; import org.apache.zookeeper.server.ZooKeeperServerMain; import org.apache.zookeeper.server.quorum.QuorumPeerConfig;
public class KfkSvr {
public static void main(String[] args) throws Exception {
//start local zookeeper System.out.println("starting local zookeeper..."); QuorumPeerConfig quorumConfiguration = new QuorumPeerConfig(); Properties zkProperties = new Properties(); zkProperties.load(ClassLoader.getSystemResourceAsStream("zoo.cfg")); FileUtils.cleanDirectory(new File(zkProperties.getProperty("dataDir"))); ZooKeeperServerMain zooKeeperServer = new ZooKeeperServerMain(); final ServerConfig configuration = new ServerConfig(); quorumConfiguration.parseProperties(zkProperties); configuration.readFrom(quorumConfiguration); new Thread(new Runnable(){ @Override public void run() { try { zooKeeperServer.runFromConfig(configuration); } catch (IOException e) { e.printStackTrace(); } }}).start(); System.out.println("done"); Thread.sleep(1000); //start local kafka broker Properties kafkaProperties = new Properties();; kafkaProperties.load(ClassLoader.getSystemResourceAsStream("server.properties")); FileUtils.cleanDirectory(new File( kafkaProperties.getProperty("log.dirs"))); KafkaConfig kafkaConfig = new KafkaConfig(kafkaProperties); KafkaServerStartable kafka = new KafkaServerStartable(kafkaConfig); System.out.println("starting local kafka broker..."); kafka.startup(); System.out.println("done");
Thread.sleep(1000); System.out.println("starting send kafka message..."); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<String, String>(props); for (int i=0;i<10000;i++) { ProducerRecord<String, String> data = new ProducerRecord<String, String>("page_visits", "name"+i, "zs ls ww lhl"); producer.send(data); Thread.sleep(500); } producer.close(); System.out.println("done"); }
} |
修改JavaDirectKafkaWordCount 的Run configuration(localhost:9092 page_visits)
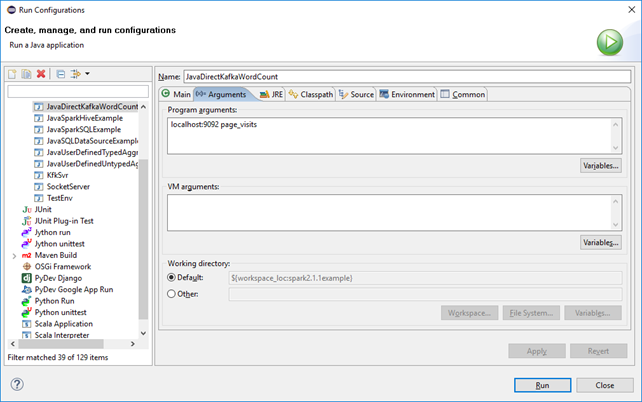
JavaDirectKafkaWordCount.java中添加一行:sparkConf.set("spark.master", "local[3]");
由于此例较陈旧,这里又需要去掉kafka。(下次重新运行Kfksvr又需要加上,且只有Kfksvr依赖它)
<!-- <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.10.2.1</version> </dependency> --> |
运行JavaDirectKafkaWordCount
运行结果
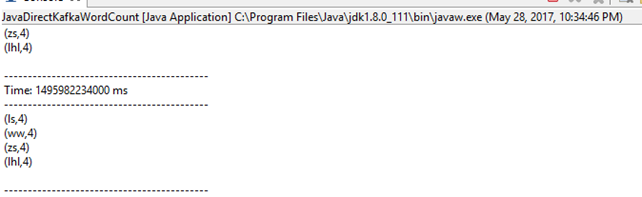
结果解析。streaming时间窗口2秒,而kafka发送周期是500ms,故统计2000/500=4次。
JavaKafkaWordCount
启动KfkSvr
启动JavaKafkaWordCount
说明:这个example过于久远,它间接依赖的class(org.apache.spark.Logging.class等三个。)已经删除了。故,为了成功运行,需要找到这个class,并添加。(exmaples下其他都不需要)
从这里下载spark-1.5.2的bin。。http://spark.apache.org/downloads.html
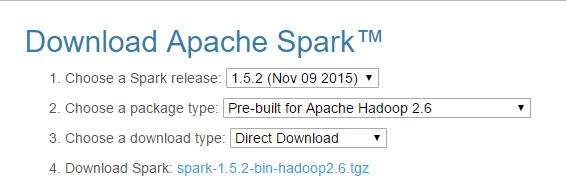
解压出spark-assembly-1.5.2-hadoop2.6.0.jar 。再从这个jar中找到apache.spark. Logging.class。

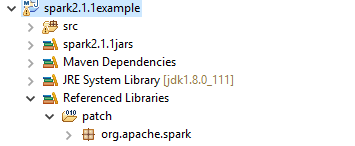
在项目中建出下面的目录结构,并如图拷贝到目录下。
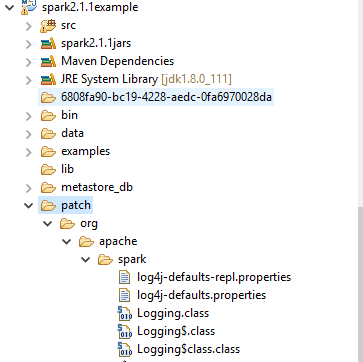
将上面patch目录添加到classpath中
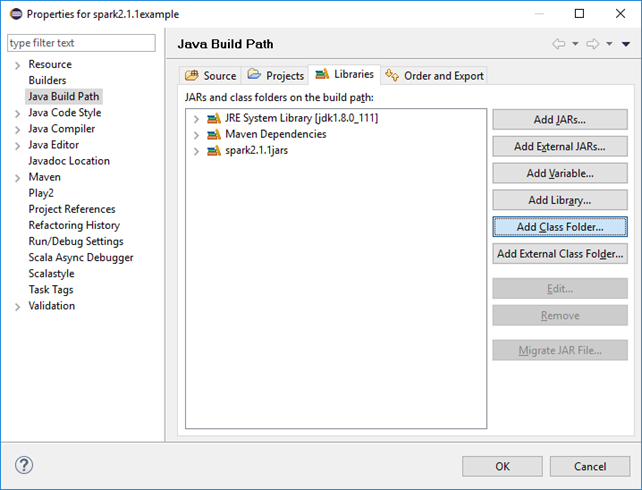
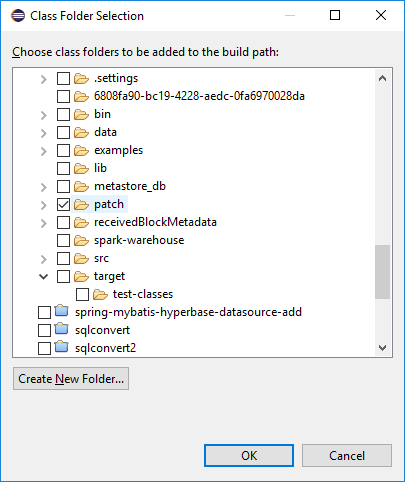

配置运行参数

在JavaKafkaWorkdCount.java中添加一行:sparkConf.set("spark.master", "local[3]");
说明:如果只设置spark.master=local,会有提示:WARN StreamingContext: spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data.
运行结果:

JavaStructuredKafkaWordCount
package org.apache.spark.examples.sql.streaming;
需要用到spark-sql-kafka,所以需要添加如下依赖。
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql-kafka-0-10_2.10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.10</artifactId> <version>2.1.1</version> </dependency> |
运行KfkSvr(略)
运行JavaStructuredKafkaWordCount,修改代码
SparkSession spark = SparkSession .builder() .config("spark.master", "local[3]") .appName("JavaStructuredKafkaWordCount") .getOrCreate(); // Create DataSet representing the stream of input lines from kafka |
修改启动参数:localhost:9092 subscribe page_visits
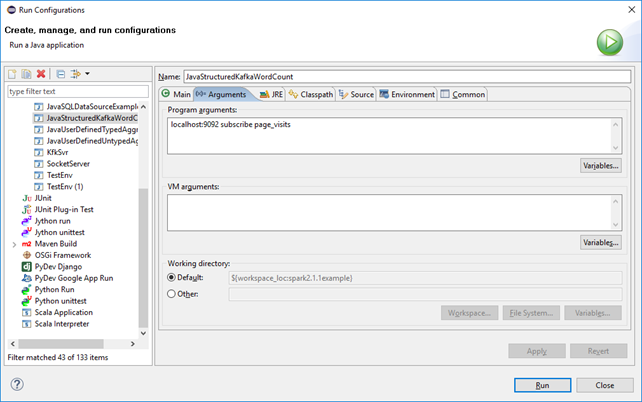
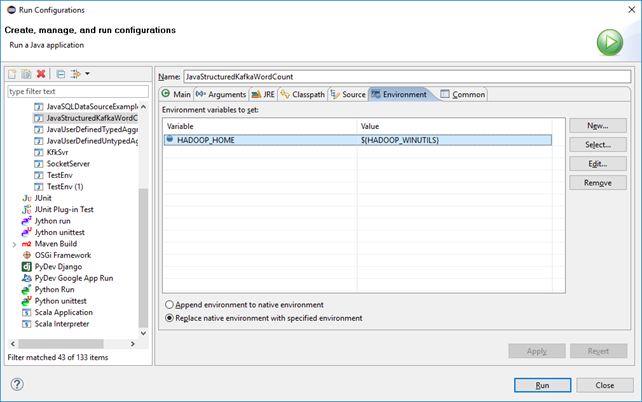
运行结果:
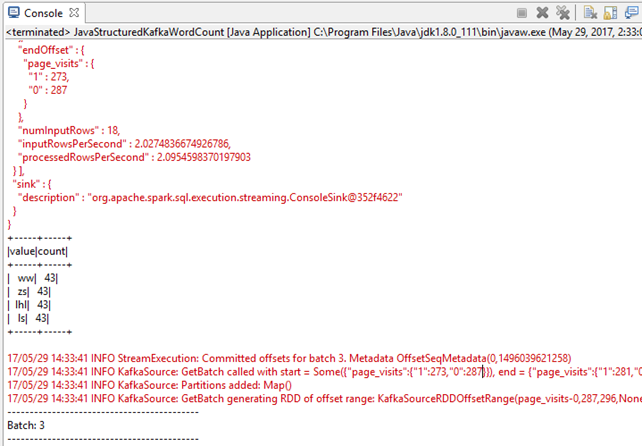
说明,日志较多。修改log级别ERROR后:

JavaStructuredNetworkWordCount
package org.apache.spark.examples.sql.streaming;
运行tw.SocketServer
配置JavaStructuredNetworkWordCount的启动参数


配置JavaStructuredNetworkWordCount的代码:
SparkSession spark = SparkSession .builder() .config("spark.master", "local[2]") .appName("JavaStructuredNetworkWordCount") .getOrCreate(); |

JavaStructuredNetworkWordCountWindowed
启动socketServer
修改JavaStructuredNetworkWordCountWindowed启动参数,添加main函数参数和环境变量

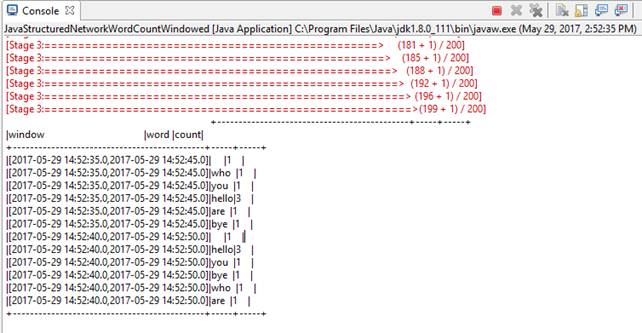
启动JavaStructuredNetworkWordCountWindowed
JavaNetworkWordCount
package org.apache.spark.examples.streaming;
- Program arguments: localhost 9999 D:/tmp/checkpoint/ D:/tmp/out
- replace native envrionments with specified envrionment.
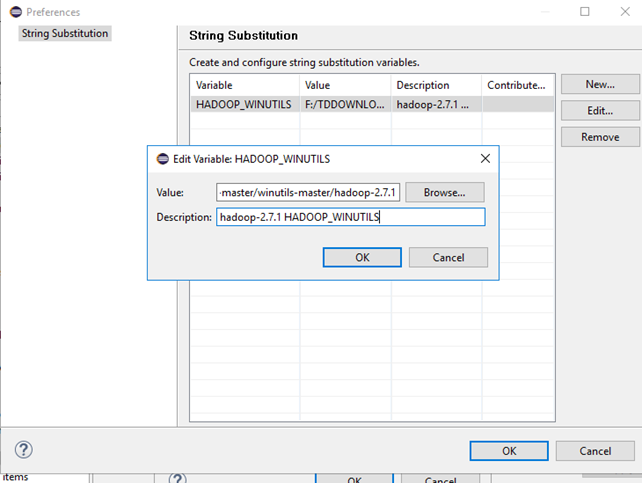
Envrionments: HADOOP_HOME=F:/TDDOWNLOAD/winutils-master/winutils-master/hadoop-2.7.1
修改JavaNetworkWordCount.java
SparkConf sparkConf = new SparkConf().setAppName("JavaNetworkWordCount")
.set("spark.master", "local[3]");
启动tw.SocketServer。
启动JavaNetworkWordCount
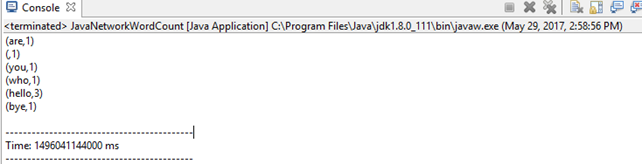
运行结果:
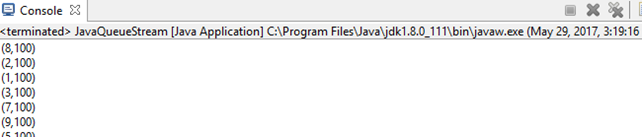
JavaQueueStream
SparkConf sparkConf = new SparkConf().setAppName("JavaQueueStream").set("spark.master", "local[2]");
结果如图:
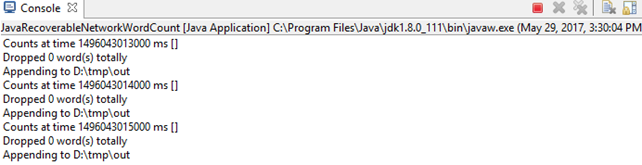
JavaRecoverableNetworkWordCount
SparkConf sparkConf = new SparkConf().setAppName("JavaRecoverableNetworkWordCount").set("spark.master", "local[3]"); |
1,Program arguments:localhost 9999
2,replace native envrionments with specified envrionment.
Envrionments: HADOOP_HOME=F:/TDDOWNLOAD/winutils-master/winutils-master/hadoop-2.7.1
修改JavaNetworkWordCount.java
SparkConf sparkConf = new SparkConf().setAppName("JavaNetworkWordCount")
.set("spark.master", "local[3]");
启动tw.SocketServer。
启动JavaRecoverableNetworkWordCount
运行结果:
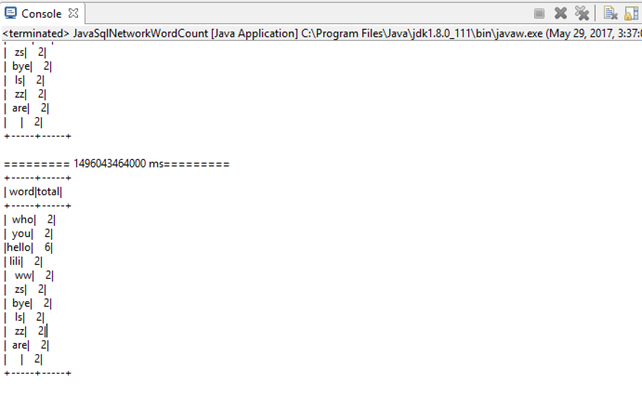
JavaSqlNetworkWordCount
package org.apache.spark.examples.streaming;
- Program arguments: localhost 9999
- replace native envrionments with specified envrionment.
Envrionments: HADOOP_HOME=F:/TDDOWNLOAD/winutils-master/winutils-master/hadoop-2.7.1
修改JavaSqlNetworkWordCount.java
SparkConf sparkConf = new SparkConf().setAppName("JavaNetworkWordCount")
.set("spark.master", "local[3]");
启动tw.SocketServer。
启动JavaSqlNetworkWordCount
JavaStatefulNetworkWordCount
package org.apache.spark.examples.streaming;
- Program arguments: localhost 9999
- replace native envrionments with specified envrionment.
Envrionments: HADOOP_HOME=F:/TDDOWNLOAD/winutils-master/winutils-master/hadoop-2.7.1
修改JavaStatefulNetworkWordCount.java
SparkConf sparkConf = new SparkConf().setAppName("JavaStatefulNetworkWordCount ")
.set("spark.master", "local[3]");
修改SocketServer
while(true){
pw.println("hello world");
pw.println();
pw.flush();
Thread.sleep(500);
}
启动tw.SocketServer。
启动JavaStatefulNetworkWordCount
运行结果:
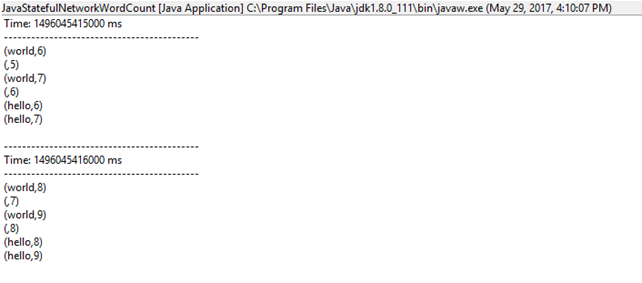
JavaFlumeEventCount
准备辅助类
package tw.flume;
import java.util.HashMap; import java.util.Map;
import org.apache.flume.agent.embedded.EmbeddedAgent; import org.apache.flume.event.SimpleEvent;
import com.google.common.collect.ImmutableMap;
public class FlumeSvr {
public static void main(String[] args) throws Exception { final Map<String,String> properties=new HashMap<String,String>(); properties.put("channel.type","memory"); properties.put("channel.capacity","100000"); properties.put("channel.transactionCapacity","1000"); properties.put("sinks","sink1"); properties.put("sink1.type","avro"); properties.put("sink1.hostname","localhost"); properties.put("sink1.port","44444"); properties.put("processor.type","default"); EmbeddedAgent agent = null; agent = new EmbeddedAgent("myagent"); agent.configure(properties); agent.start(); for(int i=0;;i++){ SimpleEvent evt = new SimpleEvent() ; evt.setBody("this is body".getBytes()); evt.setHeaders(ImmutableMap.of("index", i+"")); agent.put(evt); Thread.sleep(100); } }
} |
添加maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume_2.10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-flume_2.10</artifactId> <version>2.1.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-embedded-agent --> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-embedded-agent</artifactId> <version>1.6.0</version> </dependency> |
准备JavaFlumeEventCount
package org.apache.spark.examples.streaming;
- Program arguments: localhost 44444
修改JavaFlumeEventCount.java
SparkConf sparkConf = new SparkConf().setAppName("JavaFlumeEventCount") .set("spark.master", "local[3]");
1,运行JavaFlumeEventCount
2,运行tw.flume. FlumeSvr
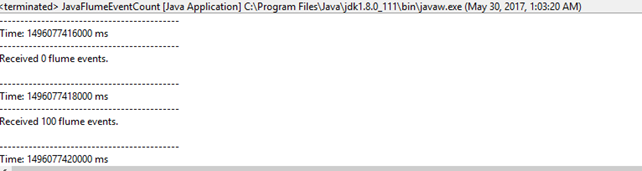
结果如下图。每隔10秒出现一次Recived 100
JavaHdfsLR
package org.apache.spark.examples;
Program arguments: examples/src/main/resources/JavaHdfsLR.txt 100
修改JavaHdfsLR.java
SparkSession spark = SparkSession
.builder()
.appName("JavaHdfsLR").config("spark.master","local[3]")
编写数据生成代码
package tw;
import java.io.FileWriter; import java.io.IOException; import java.util.Random;
public class DataGen {
public static void main(String[] args) throws IOException { JavaHdfsLR();
}
private static void JavaHdfsLR() throws IOException { FileWriter out = new FileWriter("examples/src/main/resources/JavaHdfsLR.txt"); Random r =new Random(); for(int line=0;line<1000;line++){ StringBuffer sb =new StringBuffer(); for(int i=0;i<11;i++){ sb.append(r.nextDouble()); sb.append(" "); } out.write(sb.toString()); out.write('\n'); sb.setLength(0); } out.close(); }
} |
运行DataGen.java
运行JavaHdfsLR.java
结果类似(数据源随机产生,故不同)如下:
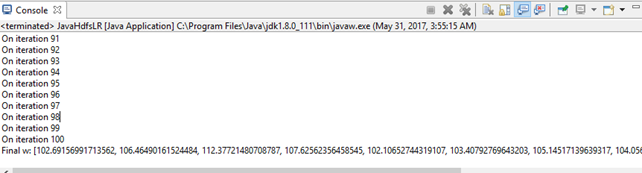
JavaLogQuery

JavaPageRank
package org.apache.spark.examples;
Program arguments: examples/src/main/resources/JavaPageRank.txt 100
修改JavaHdfsLR.java
SparkSession spark = SparkSession
.builder()
.appName("JavaPageRank").config("spark.master","local[3]")
修改tw.DataGen的代码
public static void main(String[] args) throws IOException { // JavaHdfsLR(); JavaPageRank(); }
private static void JavaPageRank() throws IOException { FileWriter out = new FileWriter("examples/src/main/resources/JavaPageRank.txt"); Random r =new Random(); char[] links = {'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'}; for(int line=0;line<1000;line++){ int i = r.nextInt(24); out.write(links[i]); out.write(' '); i = r.nextInt(24); out.write(links[i]); out.write('\n'); } out.close(); } |
运行tw.DataGen
运行JavaPageRank
结果如下:
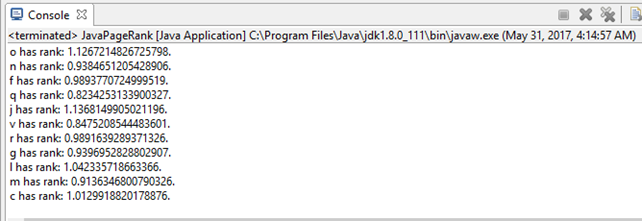
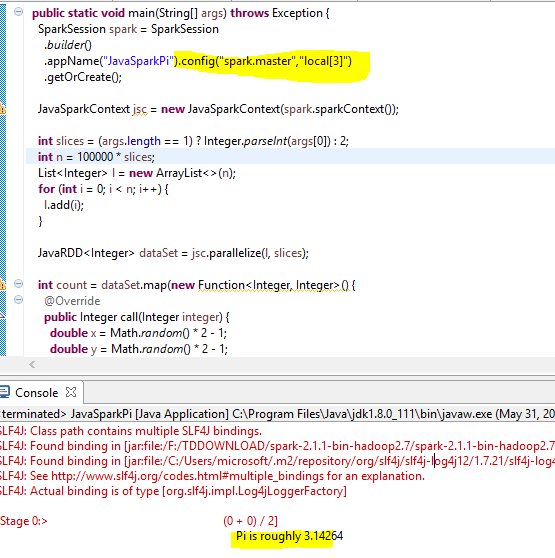
JavaSparkPi
JavaSparkPi
JavaStatusTrackerDemo

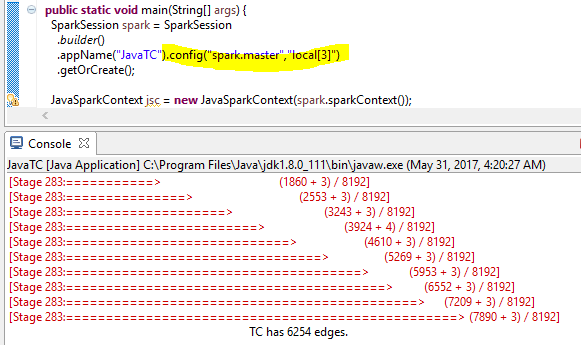
JavaTC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号