
一致性哈希的简单理解
一致性Hash是一种特殊的Hash算法,由于其均衡性、持久性的映射特点,被广泛的应用于负载均衡领域。
非常简单的Hash算法Group = Key % N来实现请求的负载均衡,通过对集群数量 N 取模,得到该 key 应该查找、存储的服务器节点
问题1:当缓存服务器数量发生变化时,会引起缓存的雪崩,可能会引起整体系统压力过大而崩溃(大量缓存同一时间失效)。
问题2:当缓存服务器数量发生变化时,几乎所有缓存的位置都会发生改变,
优化
1.引入哈希环,解决缩容、扩容的成本问题
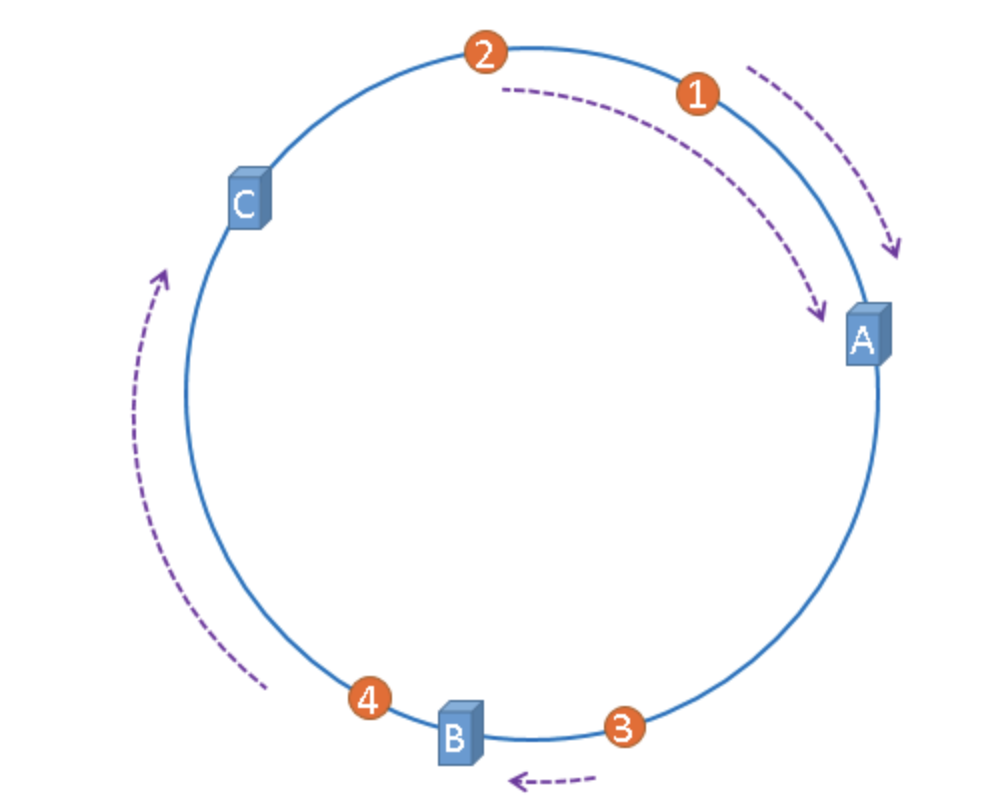
通过构建环状的Hash空间代替线性Hash空间。Group_t = Key % NEW_N,hash环空间很大(NEW_N一般是 0 ~ 2^32),给每个Key计算Hash,然后沿着顺时针的方向找到环上的第一个节点,就是该Key储存对应的集群。
当扩容或缩容时,只会影响两个服务器节点之间的 key,而不会影响全部的 key。将代价降低。
比如删除集群节点 A,只会影响 key1,key2。 而其他的 key 不受影响。
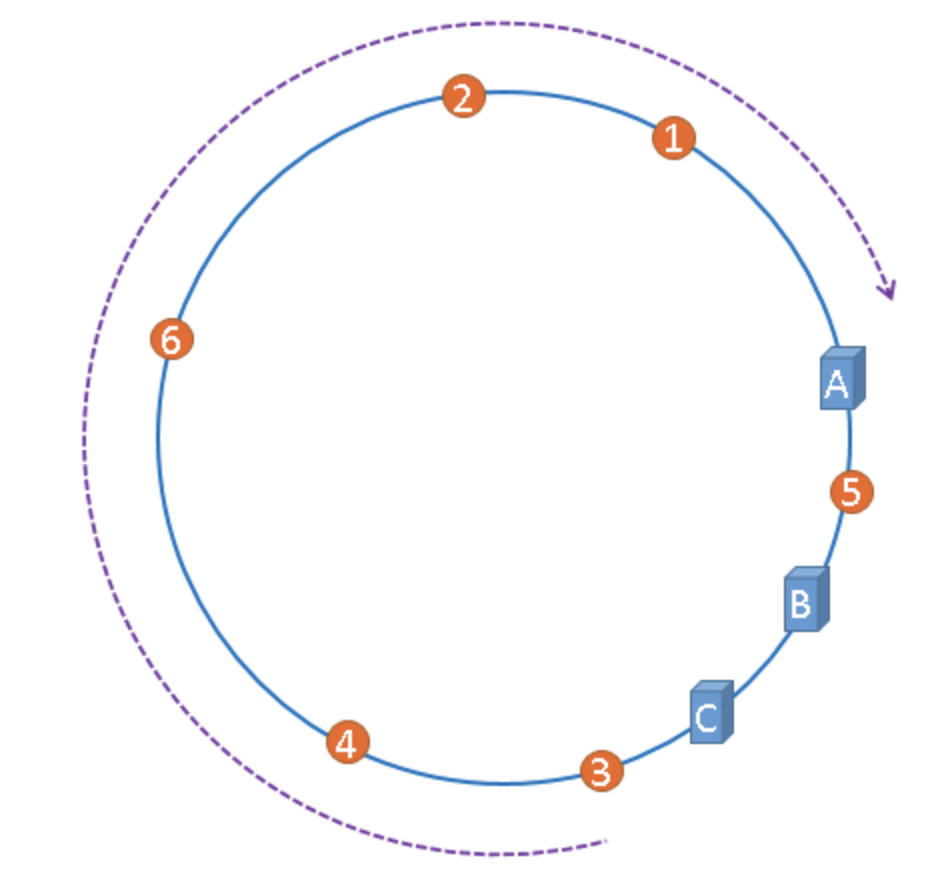
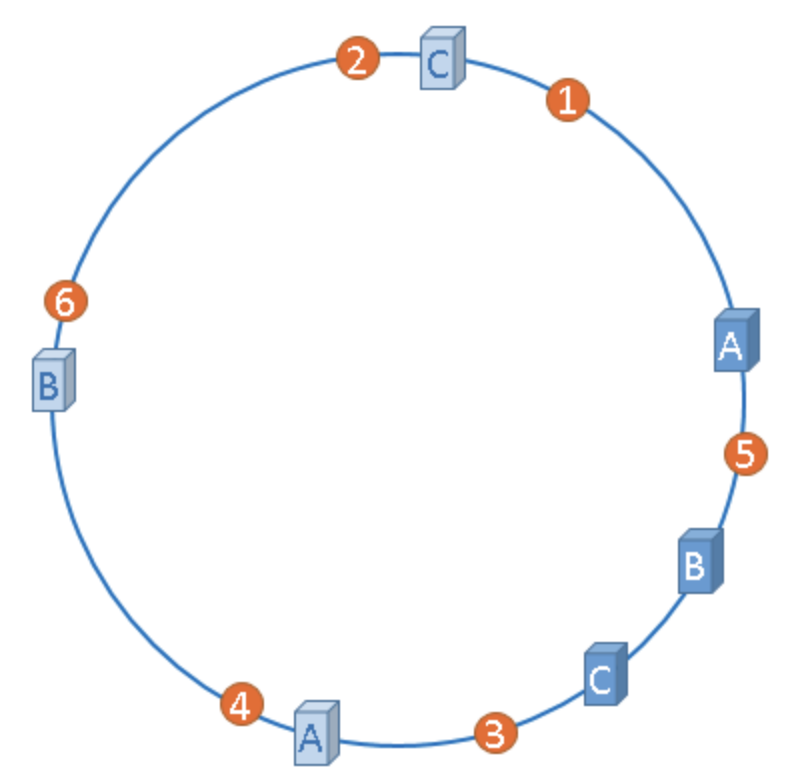
2.引入虚拟节点,解决数据倾斜的问题
“虚拟节点”是”实际节点”(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节点。 将虚拟节点随机的分布在哈希环上。 这样就不会使得过多的 key 命中同一个节点,缓解集群压力。
如何优雅缩扩容
1.高频Key预热(LRU)
维护一份高频访问Key的列表,新的集群在启动时根据这个列表提前拉取对应Key的缓存值进行预热,便可以大大减少因为新增集群而导致的Key失效。
2.历史Hash环保留
举例,假设我们原有3个集群,现在要扩展到6个集群,这就意味着原有50%的Key都会失效(被转移到新节点上),如果我们维护扩容前和扩容后的两个Hash环,在扩容后的Hash环上找不到Key的储存时,先转向扩容前的Hash环寻找一波,如果能够找到就返回对应的值并将该缓存写入新的节点上,找不到时再透过缓存
一致性 hash 优化
先说缺陷:
整个分布式缓存需要一个路由服务来做负载均衡,存在单点问题(如果路由服务挂了,整个缓存也就凉了)
Hash环上的节点非常多或者更新频繁时,查找性能会比较低下
优化:
1.使用HashSlot(分治思想)
类似于Hash环,Redis Cluster采用HashSlot来实现Key值的均匀分布和实例的增删管理。
首先默认分配了16384个Slot(这个大小正好可以使用2kb的空间保存),每个Slot相当于一致性Hash环上的一个节点。接入集群的所有实例将均匀地占有这些Slot,而最终当我们Set一个Key时,使用CRC16(Key) % 16384来计算出这个Key属于哪个Slot,并最终映射到对应的实例上去。
2.P2P节点寻找
实现去中心化的访问,也就是说无论访问集群中的哪个节点,你都能够拿到想要的数据。其实这有点类似于路由器的路由表,具体说来就是:
- 每个节点都保存有完整的HashSlot - 节点映射表,也就是说,每个节点都知道自己拥有哪些Slot,以及某个确定的Slot究竟对应着哪个节点。
- 无论向哪个节点发出寻找Key的请求,该节点都会通过CRC(Key) % 16384计算该Key究竟存在于哪个Slot,并将请求转发至该Slot所在的节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号