
李宏毅语音课程-RNN-T模型
一、RNN-T, CTC, HMM 的训练和解码过程
training: 1. 找到所有的alignments, 2. 计算所有的alignments的score和 3.根据得分score更新模型参数。 4.根据训练好的模型参数,计算输入特征X的输出token

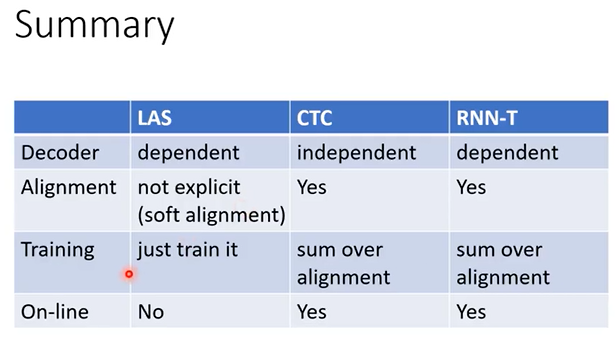
training时:P(Y|X)与每个alignmen的路径有关,每条路径的概率与模型参数θ有关,
二、RNN-T原理和alignment、计算score过程
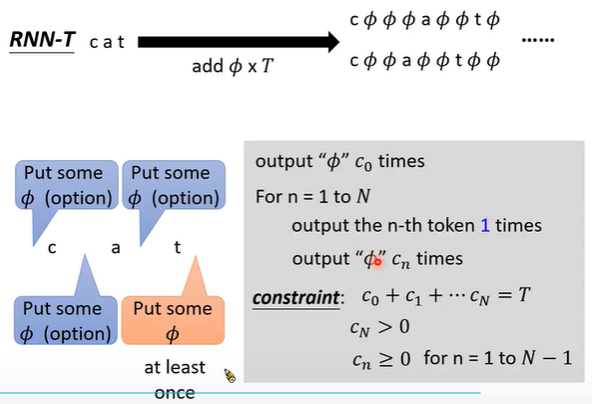
1. rnn-t产生token的过程
rnn-t decoder:给一个输入h,输出多个字符 直到输出空字符Φ。接着输入下一个MCCC特征
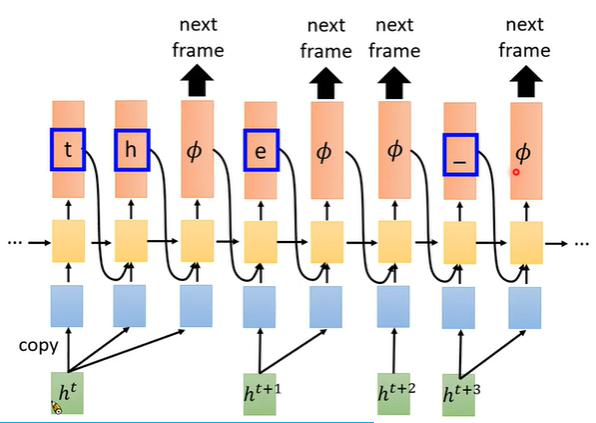
实际会在输出字符的后面会 加一个 RNN(最上面的蓝色块)。把原来的RNN剔除(中间黄色块)。
原因:1. 增加的RNN相当于一个语言模型LM,可以提前从text中训练。2. 方便RNN-T的训练,因蓝色LM-RNN其与空字符Φ无关
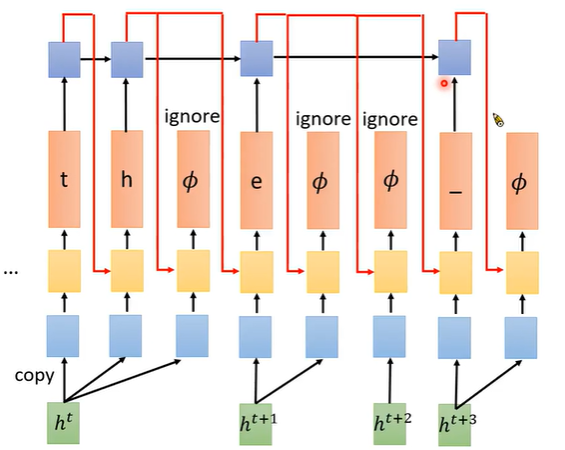
2. 训练时:穷举所有alignment过程:每个字符后可以没有空字符,也可以有多个空字符。对每个输入x,向右走产生空字符Φ,向下产生token。
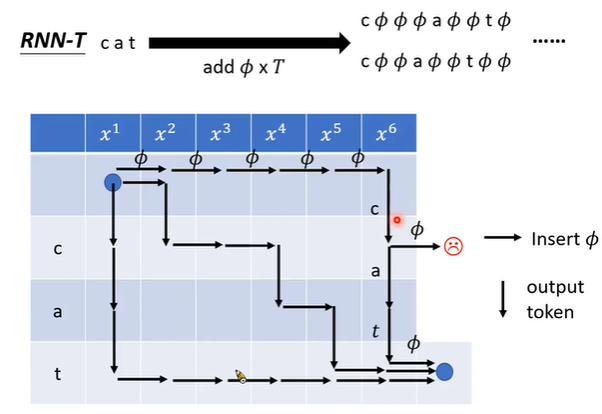
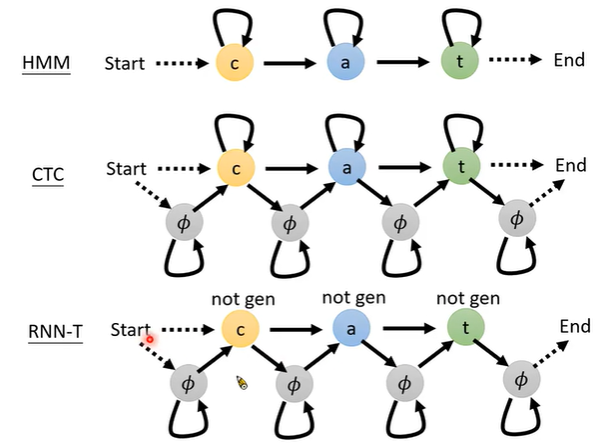
HMM、CTC、RNN-T穷举所有alignment的区别。HMM不产生空字符Φ。CTC可连续产生token和空字符Φ。 RNN-T可连续产生空字符Φ,但同一个token不能连续产生,但每次输入可以产生多个不同token。
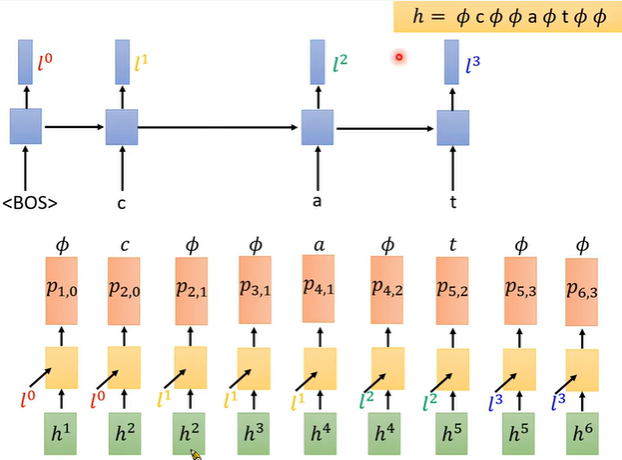
3. 计算单个alignment的概率方式
RNN-T计算概率的过程:上面的蓝色部分是语言模型LM-RNN, 其概率与空字符Φ无关,只受token的影响 。
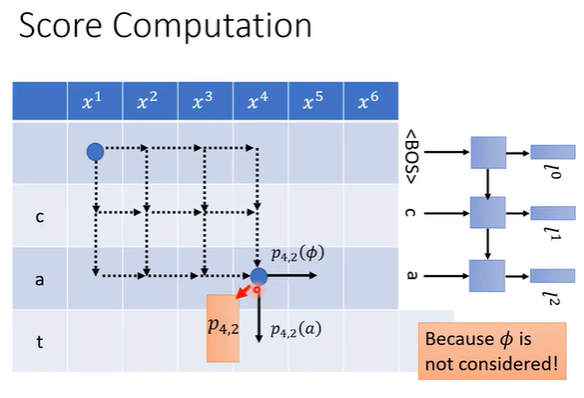
当前帧的概率p41受上一个token的l1和当前帧的h4影响。p41是一个向量,包含每一个音素phone的概率。
4. 计算所有alignment的概率和,用于训练,(有别于预测时 求取具有最大概率的路径)
P42:当前帧产生的所有字符的概率,4代表已经输入4个音频特征MFCC,2代表产生了2个token。P42的概率与如何走到P42位置的路径无关。无关的原因是蓝色的语言模型LM-RNN与空字符Φ无关,只和输出的token相关。
如下图右图中,P42只受h4和l2的影响,与在哪个位置插入空字符Φ无关。其中 h4只与输入的MFCC有关,l2只与已经产生的token的有关。
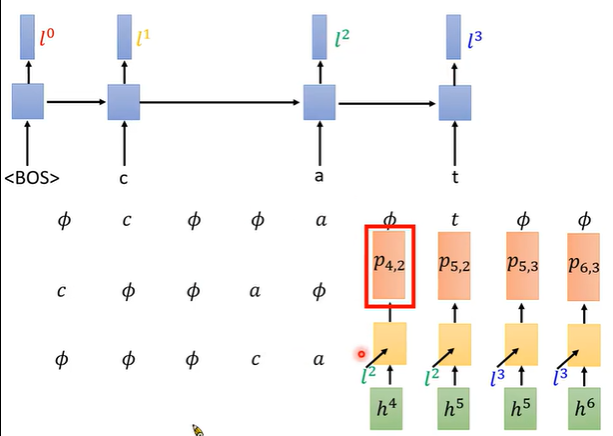
α42:代表走到当前位置所有的路径的概率和(score和)。可以由α32和α41得到,动态规划的思想。

