李宏毅语音课程笔记-LAS模型原理
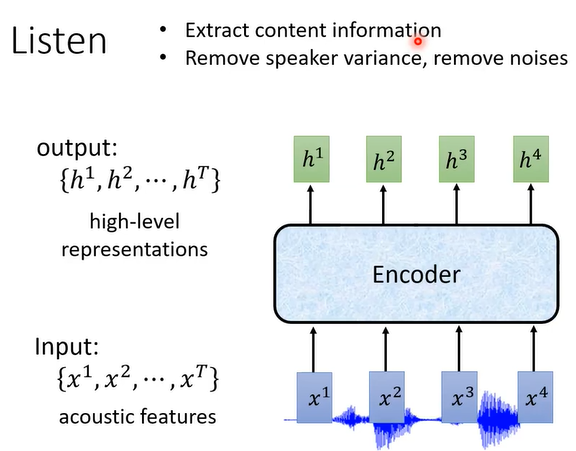
Listen过程:将MFCC特征X输入encoder得到输出 h向量,每个x输出一个h。
encoder可以是:RNN、CNN、self-attention layers等
attention and spell过程
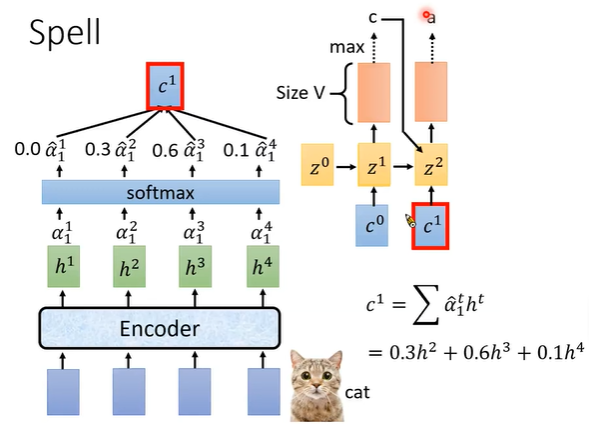
1. 向量z0与向量h进行attention运算产生数字α0
2. 使用softmax对α进行归一化,与h相乘生成context vector向量c0
3. c0输入到Decoder的z1中 ,生成每个字的概率向量V
4. 将z1与向量h进行attention运算产生数字α1 -> c1 ->
重复上述过程
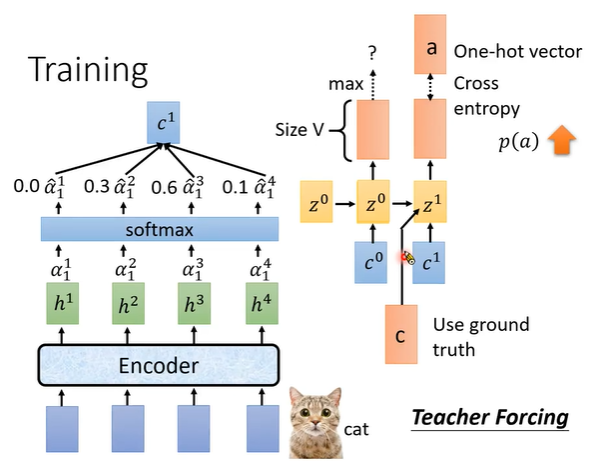
训练decoder时,使用teach forcing方式:先把前一个正确的字符 输入到当前的向量z1中,而不是z0的输出的字符输入到z1中。
cross entrophy作为损失进行反馈跟新RNN的参数
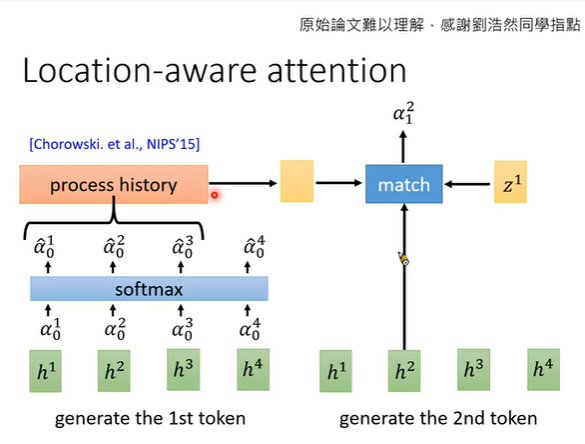
使用z1与h2做attention计算时,加上z0在h2位置前后的attention结果。当前的输出与前后相邻的几帧关系较大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号