
之前一直都在使用,但是没有注意过这些规范,
转自记录下 ,转载自:https://mp.weixin.qq.com/s/yCTNH1hMp6iOvHgh9vWg6A
最近一年多开始“搞”ES(ElasticSearch),遇到了很多“坑”,希望和大家也一起分享下,由于接触时间不长,如有问题麻烦联系我及时指出。
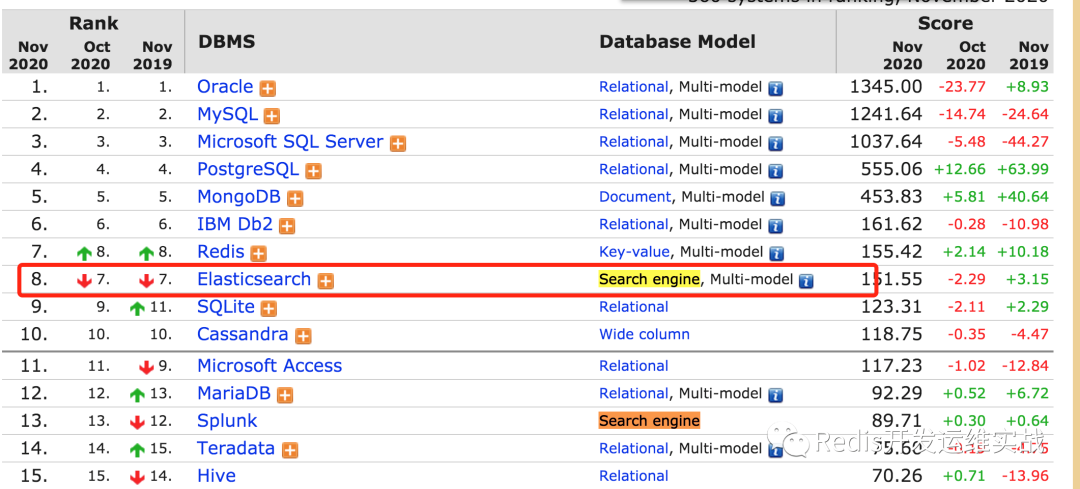
ElasticSearch除了在日志场景(监控、数据分析、debug)等场景大量使用以外,最近一年多在很多核心上的线上业务(譬如电商业务)大量使用,目前接近了5000个节点,目前在db-ranking(2020-11-24日),ElasticSearch在search-engine中常年第一:
对于MySQL、Redis这类存储缓存许多开发同学多有很强的最佳实践,但对于ElasticSearch的使用经验相对模式。我个人经验是ElasticSearch非常便于开发(譬如支持dynamic mapping)但它相对脆弱:一方面是开发同学对于其重视程度不够(譬如没有自己制定mapping)、另一方面它本身的一些设计(例如聚合计算都在JVM完成)导致其相对脆弱。
为此我们提供一份关于ElasticSearch的开发规范帮助ElasticSearch使用者减少一些可能碰到的坑
一、容量规划
1. 分片(shard)容量
- 非日志型(搜索型、线上业务型)的shard容量在10~30GB(建议在10G)
- 日志型的shard容量在30~100GB(建议30G)
- 单个shard的文档个数不能超过21亿左右(Integer.MAX_VALUE - 128)
注:一个shard就是一个lucene分片,ES底层基于lucene实现。
2. 索引(index)数量
- 大索引需要拆分:增强性能,风险分散。
反例:一个10T的索引,例如按date查询、name查询
正例:index_name拆成多个index_name_${date}
正例:index_name按hash拆分index_name_{1,2,3,...100..}
提示:索引和shard数并不是越多越好,对于批量读写都会有性能下降,所以要综合考虑性能和容量规划,同时配合压力测试,不存在真正的最优解。
3. 节点、分片、索引
一个节点管理的shard数不要超过200个
4. 示意图
(1) 集群
(2) 节点:
(3) 索引:
(4) 分片(shard)
二、 索引mapping设计
大原则:不用默认配置和动态mapping、数据用途(类型、分词、存储、排序)弄清,下面是一个标准mapping:
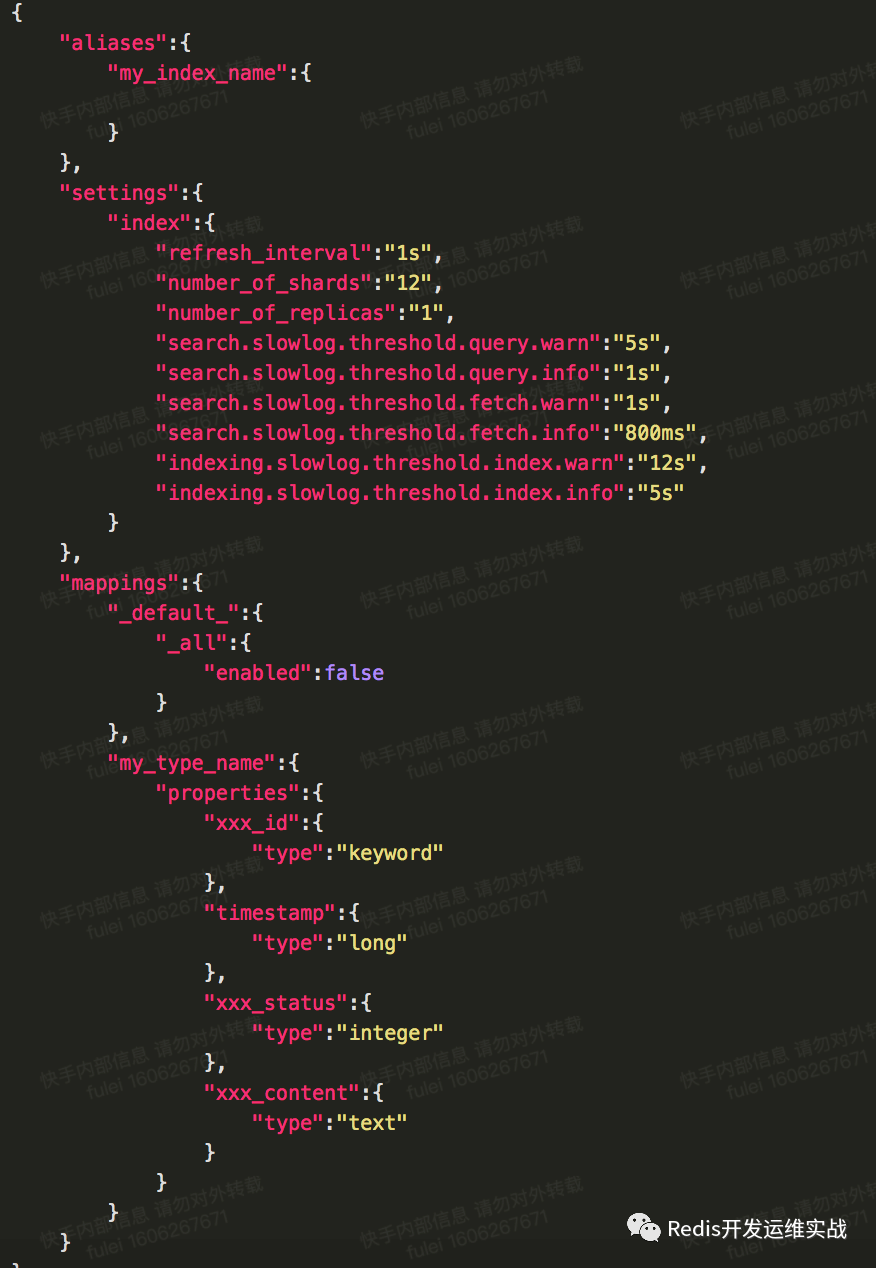
1. shard个数(number_of_shards):
参考一
2. refresh频率(refresh_interval):
ES的定位是准实时搜索引擎,该值默认是1s,表示写入后1秒后可被搜索到,所以这里的值取决于业务对实时性的要求,注意这里并不是越小越好,刷新频率高也意味着对ES的开销也大,通常业务类型在1-5s,日志型在30s-120s,如果集中导入数据可将其设置为-1,ES会自动完成数据刷新(注意完成后更改回来,否则后续会出现搜索不到数据)
3. 使用别名(aliases):不要过度依赖别名功能
正例:
- 索引名:index_name_v1
- 别名:index_name
未来重建index_name_v2索引,对于业务来说只需要换别名。
4. type个数
1个就够了,从ES6开始只支持一个type,这个type比较鸡肋,后面的版本可能会去掉。
如果一定用:针对已经使用多个type的场景,一定要保证不同type下字段尽量保持一致,否则会加大数据稀疏性,存储与查询性能受影响
5. 慢日志(slowlog):
一定要配置,默认不记录慢查询,kcc提供了grafana、kibana查询功能。
6. 副本(number_of_replicas)
1个就够用,副本多写入压力不可忽视。极端情况下:譬如批量导入数据,可以将其调整为0.
7. 字段设计
(1) text和keyword的用途必须分清:分词和关键词(确定字段是否需要分词)
(2) 确定字段是否需要独立存储
(3) 字段类型不支持修改,必须谨慎。
(4) 对不需要进行聚合/排序的字段禁用doc_values
(5) 不要在text做模糊搜索:
8. 设置合理的routing key(默认是id)
id不均衡:集群容量和访问不均衡,对于分布式存储是致命的。
9. 关闭_all
ES6.0已经去掉,对容量(索引过大)和性能(性能下降)都有影响。
10. 避免大宽表:
ES默认最大1000,但建议不要超过100.
11. text类型的字段不要使用聚合查询。
text类型fileddata会加大对内存的占用,如果有需求使用,建议使用keyword
12.聚合查询避免使用过多嵌套,
聚合查询的中间结果和最终结果都会在内存中进行,嵌套过多,会导致内存耗尽
比如以下聚合就嵌套了3层,country、city和salary的结果都会保存在内存中,如果唯一值较多,就会导致内存耗尽
{
"aggs":{
"country":{
"terms":{
"filed":"country",
"size":10
},
"aggs":{
"city":{
"terms":{
"filed":"city",
"size":20
},
"aggs":{
"salary":{
"terms":{
"filed":"salary",
"size":20
}
}
}
}
}
}
}
}三、违规操作
1. 原则:不要忽略设计,快就是慢,坏的索引设计后患无穷.
2. 拒绝大聚合 :ES计算都在JVM内存中完成。
3. 拒绝模糊查询:es一大杀手
{
"query":{
"wildcard":{
"title.keyword":"*张三*"
}
}4. 拒绝深度分页
ES获取数据时,每次默认最多获取10000条,获取更多需要分页,但存在深度分页问题,一定不要使用from/Size方式,建议使用scroll或者searchAfter方式。scroll会把上一次查询结果缓存一定时间(通过配置scroll=1m实现),所以在使用scroll时一定要保证search结果集不要太大。
5. 基数查询
尽量不要用基数查询去查询去重后的数据量大小(kibana中界面上显示是Unique Count,Distinct Count等),即少用如下的查询:
"aggregations": {
"cardinality": {
"field": "userId"
}
}6.禁止查询 indexName-*
7. 避免使用script、update_by_query、delete_by_query,对线上性能影响较大。
四、常见问题
1. 一个索引的shard数一旦确定不能改变
2. ES不支持事务ACID特性。
3. reindex:
reindex可以实现索引的shard变更,但代价非常大:速度慢、对性能有影响,所以好的设计和规划更重要
五、grafana使用规范
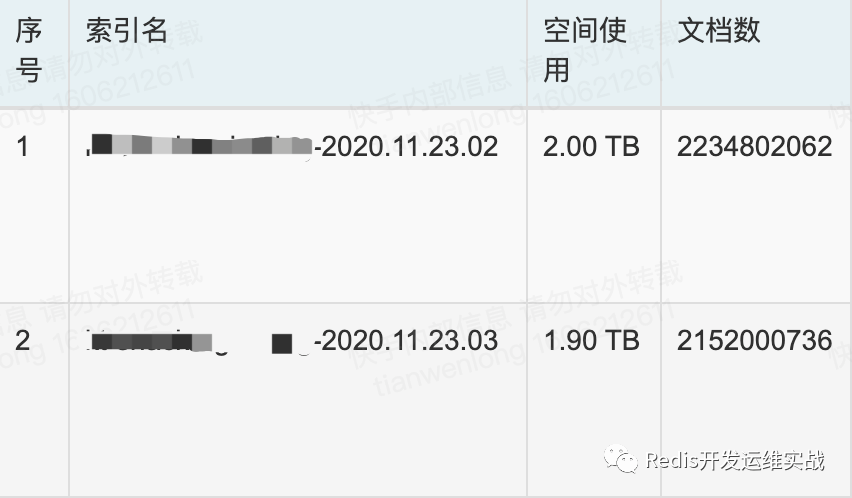
1.查询范围不要太大,建议在3h以内
如下查询7d,数据量巨大,严重影响集群查询性能
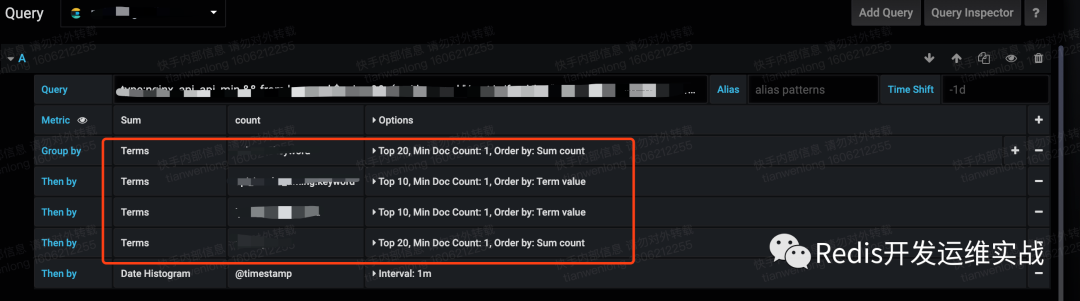
2. 拒绝多层嵌套,不要超过2层
如下图中进行了4层嵌套,每层嵌套的结果都缓存在内存中,导致内存崩溃
3. 拒绝分时查询
分位查询相当于一种分桶聚合方式,分的桶越多,带来的CPU计算量越大

4. 拒绝TOP>100查询
top查询是在聚合的基础上再进行排序,如果top太大,cpu的计算量和耗费的内存都会导致查询瓶颈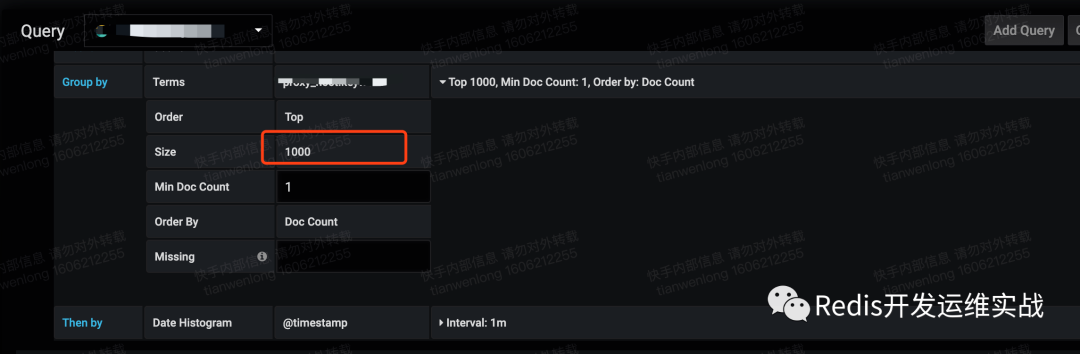

 浙公网安备 33010602011771号
浙公网安备 33010602011771号