机器学习入门KNN近邻算法(一)
1 机器学习处理流程:
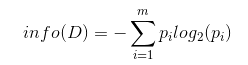
2 机器学习分类:
-
有监督学习
主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测
1 分类
分类计数预测的数据对象是离散的。如短信是否为垃圾短信,用户是否喜欢电子产品
常用方法: K近邻、朴素贝叶斯、决策树、SVM
2 回归
回归技术预测的数据对象是连续值。例如温度变化或时间变化。包括一元回归和多元回归,线性回归和非线性回归
常用方法: 线性回归、逻辑回归、岭回归
-
无监督学习
主要用于知识发现,在历史数据中发现隐藏的模式或内在结构
1 聚类
聚类算法用于在数据中寻找隐藏的模式或分组。K-means
-
半监督学习
在半监督学习方式下,训练数据有部分被标识,部分没有被标识,这种模型首先需要学习数据的内在结构,以便合理的组织数据来进行预测。算法上,包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。
常见方法: 深度学习
3 K-近邻算法原理
-
KNN概述
简单来说,K-近邻算法采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)
优点: 精度高、对异常值不敏感、无数据输入假定
缺点: 时间复杂度高、空间复杂度高
1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。改进方法是对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,改进方法是:先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
适用数据范围 : 数值型和标称型
1 标称型:标称型目标变量的结果只在有限目标集中取值,如真与假(标称型目标变量主要用于分类)
2 数值型:数值型目标变量则可以从无限的数值集合中取值,如0.100,42.001等 (数值型目标变量主要用于回归分析)
-
工作原理
1 样本训练集
2 电影类别KNN分析
3 欧几里得距离(欧式距离)
![]()
4 KNN计算过程流程图
![]()
入门案例 : 电影类型分析
电影名称 动作镜头 接吻镜头 电影类别 0 前任三 2 15 爱情 1 复仇者联盟 36 3 动作 2 杀破狼 24 1 动作 3 战狼 29 2 动作 4 泰坦尼克号 1 18 爱情 5 大话西游 29 3 爱情 6 星愿 2 20 爱情 7 西游记 25 2 动作 8 七月与安生 3 19 爱情import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt %matplotlib inline #从excel读取数据 films = pd.read_excel('films.xlsx',sheet_name=1) train = films[['动作镜头','接吻镜头']] target = films['电影类别'] # 创建机器学习模型 from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() # 对knn模型进行训练 # 构建函数原型、构建损失函数、求损失函数最优解 knn.fit(train,target) ''' KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') ''' #输入两个案例 cat = np.array([[3,16],[20,4]]) # 使用predict函数对数据进行预测 knn.predict(cat) plt.scatter(train.values[:,0],train.values[:,1]) plt.scatter(cat[:,0],cat[:,1],color='red')![predict]()
KNN近邻机器学习案例2
from sklearn.neighbors import KNeighborsClassifier import numpy as np #knn对象 neigh = KNeighborsClassifier(n_neighbors=3) #身高、体重、鞋的尺寸 X = np.array([[181,80,44],[177,70,43],[160,60,38],[154,54,37], [166,65,40],[190,90,47],[175,64,39],[177,70,40], [159,55,37],[171,75,42],[181,85,43]]) display(X) y = ['male','male','female','female','male','male','female','female','female','male','male'] # 第1步:训练数据 neigh.fit(X,y) # 第2步:预测数据 Z = neigh.predict(np.array([[190,70,43],[168,55,37]])) display(Z) #array(['male', 'female'], dtype='<U6') 识别出对应的性格

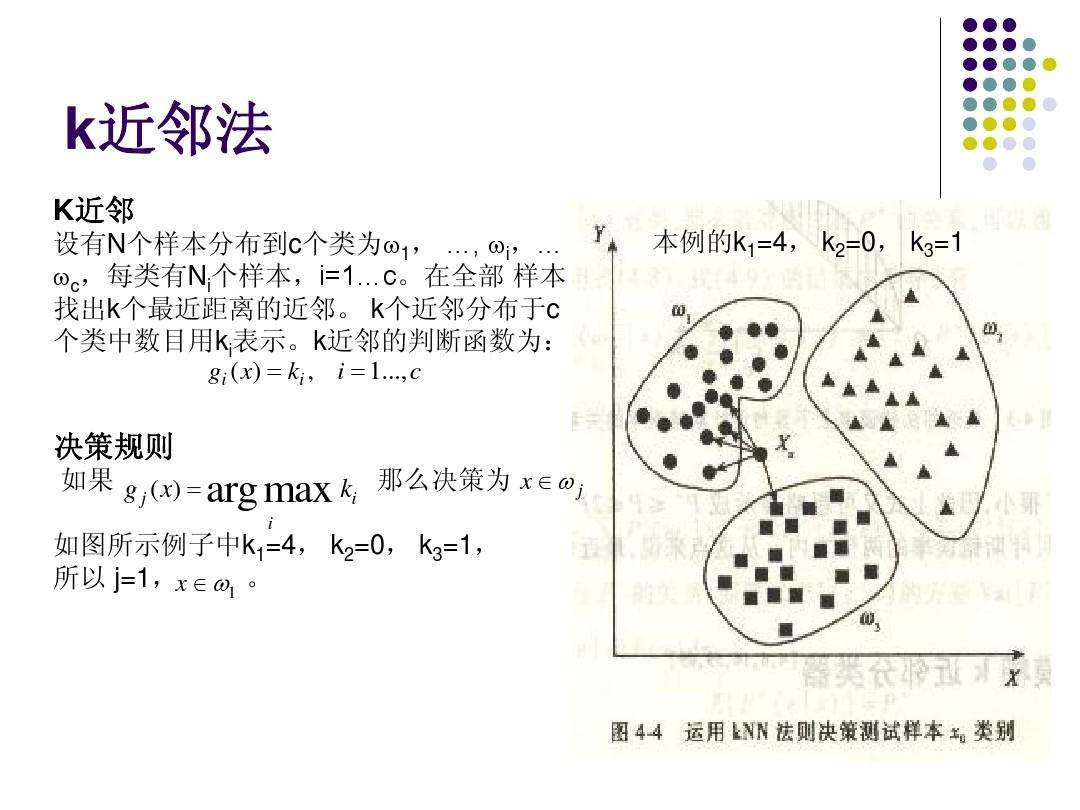

4 KNN用于分类
-
用于分类的numpy方法介绍
np.meshgrid 从坐标向量返回坐标矩阵
import numpy as np nx, ny = 3, 4 x = np.linspace(0, 1, nx) y = np.linspace(0, 1, ny) xv, yv = np.meshgrid(x, y) display(x,y,xv,yv)输出:
array([ 0. , 0.5, 1. ])
array([ 0. , 0.33333333, 0.66666667, 1. ])
array([[ 0. , 0.5, 1. ],[ 0. , 0.5, 1. ], [ 0. , 0.5, 1. ], [ 0. , 0.5, 1. ]])array([[ 0. , 0. , 0. ],
[ 0.33333333, 0.33333333, 0.33333333],
[ 0.66666667, 0.66666667, 0.66666667],
[ 1. , 1. , 1. ]])>np.ravel 返回一个连续的平坦矩阵 ```python x = np.array([[1, 2, 3], [4, 5, 6]]) display(x,x.ravel()) #输出: array([[1, 2, 3], [4, 5, 6]]) array([1, 2, 3, 4, 5, 6])np.c_ 将切片对象按第二轴转换为串联
np.c_[np.array([1,2,3]), np.array([4,5,6])]
输出:
array([[1, 4],
[2, 5],
[3, 6]])
- **具体操作**
```python
# 导入库:KNeighborsClassifier
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 导入sklearn自带数据集
from sklearn import datasets
# 得到训练样本
iris = datasets.load_iris()
X = iris.data[:,:2]
y = iris.target
#定义三种颜色代表三种蓝蝴蝶
cmap_species = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#c对应颜色池映射到target值
plt.scatter(X[:,0],X[:,1],c = y,cmap = cmap_species)
plt.show()

绘制图形之后进行KNN
#定义KNN分类器
clf = KNeighborsClassifier(n_neighbors=10)
# 第1步:训练分类器
clf.fit(X,y)
# 图片的显示范围,画布的边界范围
x_min, x_max = X[:,0].min()-1, X[:,0].max()+1
y_min, y_max = X[:,1].min()-1, X[:,1].max()+1
# 图片的背景显示坐标
xx,yy = np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02))
# 第2步:预测 ravel()数据扁平化
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()])
z = Z.reshape(xx.shape)
cmap_background = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
# 显示背景的颜色
plt.pcolormesh(xx,yy,z,cmap=cmap_background)
# 显示点的颜色
plt.scatter(X[:,0],X[:,1],c = y,cmap=cmap_species)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title('3-class classification')
plt.show()

5 KNN用于回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
%matplotlib inline
x = np.linspace(0,2*np.pi,40)
y = np.sin(x)
plt.scatter(x,y)
plt.xlabel('feature')
plt.ylabel('target')
# 随机数种子,用于固定随机数
np.random.seed(2)
noise = np.random.random(size=20) - 0.5
y[::2] += noise
plt.scatter(x,y)
# 生成knn回归模型
# n_neighbors 就是距离预测样本最近的点的个数
knn = KNeighborsRegressor(n_neighbors=19)
knn.fit(x.reshape(-1,1),y)
# 获取预测样本集
# 预测数据的形状应该和训练数据的形状一致(不要求数量一致,要求特征一致)
X_test = np.linspace(0,2*np.pi,100).reshape(-1,1)
y_ = knn.predict(X_test)
plt.plot(X_test,y_,color='orange',label='predict')
plt.scatter(x,y,color='blue',label='true-data')
plt.legend()

# 创建多个算法模型,采用不同的参数,查看回归的结果
knn1 = KNeighborsRegressor(n_neighbors=1)
knn2 = KNeighborsRegressor(n_neighbors=7)
knn3 = KNeighborsRegressor(n_neighbors=21)
knn1.fit(x.reshape(-1,1),y)
knn2.fit(x.reshape(-1,1),y)
knn3.fit(x.reshape(-1,1),y)
y1_ = knn1.predict(X_test)
y2_ = knn2.predict(X_test)
y3_ = knn3.predict(X_test)
# 拟合度过高,称为过拟合,对数据分析的过于在意局部特征
plt.plot(X_test,y1_,color='orange',label='n_neighbors=1')
# 拟合度刚好,称为最佳拟合,这是机器学习的终极目标,调参就是为了达到这个目的
plt.plot(X_test,y2_,color='cyan',label='n_neighbors=7')
# 拟合度太差,称为欠拟合,对数据特征分析不透彻,数据有效特征太少,样本数量太少
plt.plot(X_test,y3_,color='red',label='n_neighbors=21')
plt.scatter(x,y,color='blue',label='true-data')
plt.legend()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号