面向对象编程——第一单元回顾与感想
一、作业结构分析
第一次作业:
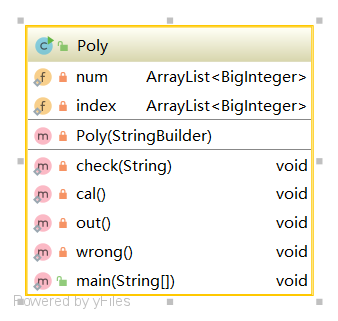
类图(真·一类到底)
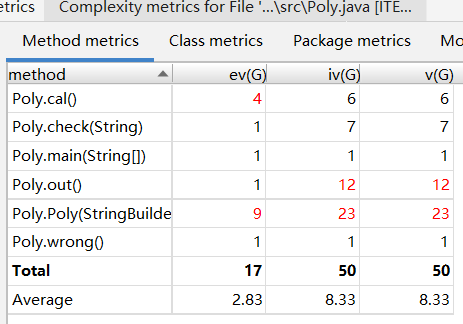


方法复杂度、类复杂度、类间依赖
第二次作业:
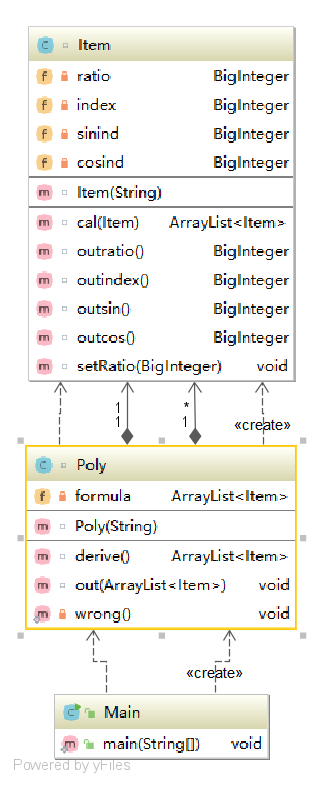
类图
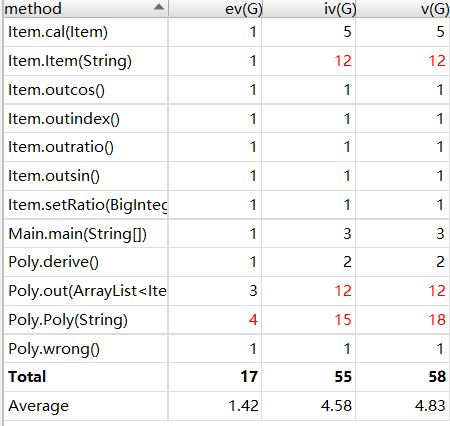
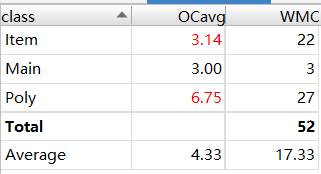
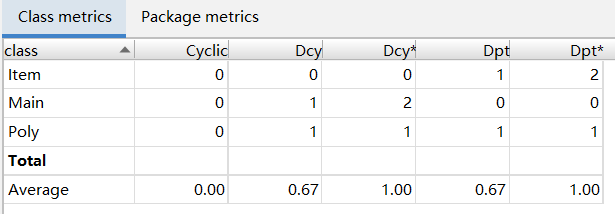
方法复杂度、类复杂度、类间依赖
第三次作业:
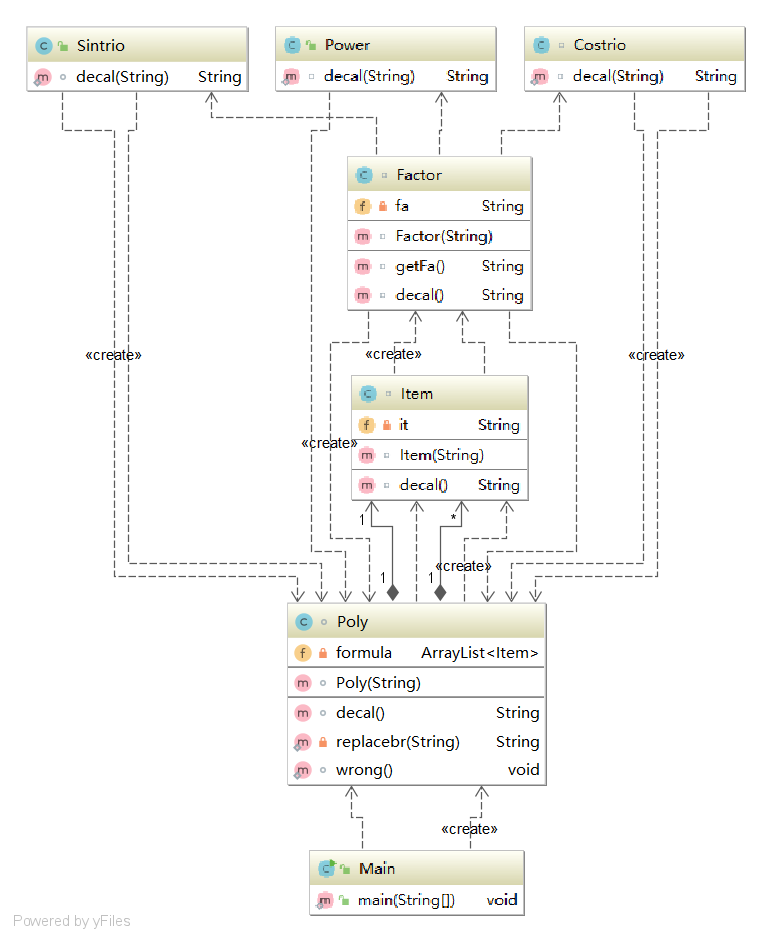
类图
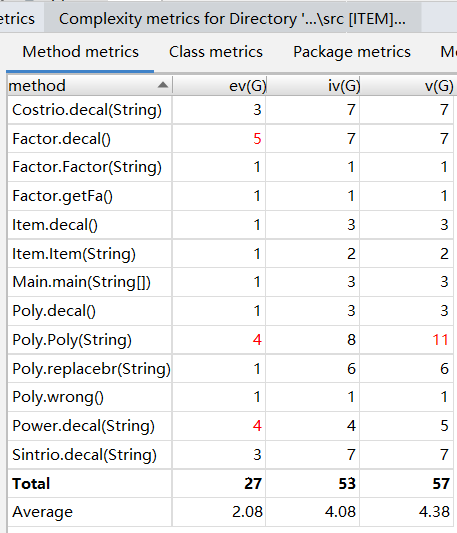
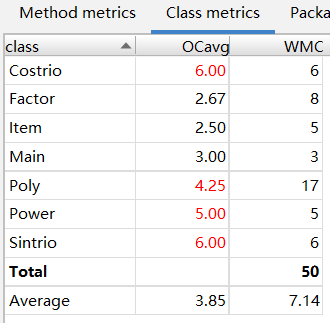

方法复杂度、类复杂度、类间依赖
结果一目了然:方法复杂度、类复杂度逐渐减少;类间依赖程度增加、类的层级化更加明显。
应用工具度量得到的结果和我个人回顾三次作业时的感受是高度一致的:更多的类、单个类的复杂度下降以及类间依赖关系的增长,体现的是更清晰的思路和程序的层次化与模块化。
但我编程时的思维方式更加“面向对象”了吗?我觉得很难说,一方面,我在编程的时候会更加注重分而治之简化问题的理念,注意封装代码,避免结构过于复杂——这一点在第三次作业中得到了很好训练。另一方面,在我主观地、凭经验地把问题分解为不同对象的通信和协同工作之后,具体的流程实现依然是“面向过程”的。
目前我对面向对象的理解是这样的“通过大量封装代码实现复用性和安全性。”复用性,即通过封装可重用代码或逻辑结构(使之成为父类抽象类接口)实现;安全性,即将类间通讯的方式加以限制,在保证程序正常工作的前提下严格控制类中的数据访问权限。我知道目前对于课程的理解依然有点浮于表面,但希望在之后的学习中能够更深入全面地了解OOP思想。
二、作业bug分析
首先,前三次作业的程序逻辑是相似的(好吧这里又面向过程了),即层次构造多项式、项和因子,随后层次调用求导方法,以及可能的优化方法。根据所在位置,bug可分为构造、求导和优化这三类。相应的,一个bug的诞生与其所在环节的设计是密不可分的。
1)第一次作业
主要有两个bug:,分别出现在首项的构造和带负号项的构造上。程序在“首项前有符号时”会重复录入首项(相当于输入了两个第一项),因此在第一项不为常数时出错;此外程序在“最后一项的系数带符号且前置的运算符为减号时”会把最后一项前的减号当加号处理,因此求导时出现负号错误。
Bug的产生主要归咎于第一次糟糕的设计——类似自动机的项匹配方法,导致Poly类的构造方法极为冗长,可读性较差。设计风格也帮了倒忙——整个项目里只有一个长达三百行的类。
我匹配项的思路是:找到两个运算符,将它们之间的字符传递给check方法构造项。这个思路有两个主要的问题:找到一个+/-时如何判断它是不是运算符而不是系数/指数符号?如果找不到下一个运算符呢?强测和互测的两个bug,以及中测的无数个bug,都是因为没能完美地解决这两个问题。具体而言,是因为在“找不到下一个符号”时,当前符号可能是系数,可能是指数,也有可能是运算符。相应的,调用check构造项时的处理细节也有不同,因此,在如此多种的情形中,写错其中的一两种几乎是无法避免的。加之我又没有细致地列出所有情形,又没有做自动化测试,仅凭自己对不同情况的判断和强度不够的手造数据,是很难发现bug的。
2)第二次作业
本次作业仅有的一个bug发生在多项式类Poly.java的第128、129行,虽然只是简单的两行输出优化的代码,却让我在强测中取得了61.33分的好成绩。我将每一项开头的“1*”换为“1”,将“-1*”换为“-”,但由于replaceall时的正则里没有加表示匹配开头的^,导致前一个因子以“1”结尾碰上后一个因子的前导“*”时发生了错误匹配。这和设计结构关系不大,主要是因为自己写时的疏忽,以及弱爆了的手造数据。
3)第三次作业
本次作业两个bug都发生在ITEM类的构造方法里:由于使用正则匹配,有时程序会匹配到有前导负号的项,我采用了把负号换为“-1*”的方法。很有效,然而。。。换的时候matcher中参数的变量名写错了。一开始我是直接在传入的参数字符串item中匹配和替换负号,后来我发现想把“-+”和“--”都替换一下,引入了一个字符串item1(传入参数不能直接改),但是这样一来,最后匹配前导负号就应该在item1中进行了。但我修改的时候遗漏了matcher中的参数item,于是乎整个“替换前导负号”这部分功能都没有正常执行,所有带前导负号的项我都处理不了了。
这看似是粗心,其实还是因为命名不规范、随意修改导致的,很多时候我在replaceall的时候都会命名一些string123什么的变量,虽然不会写错,但后续修改极易犯错;此外我每一次修改也没有计划改什么,没有考虑改动可能的影响,从而导致新增bug。今后我会仔细查看修改部分的上下文,保证修改的影响符合预期。
第二个bug则是只考虑了-sin和-cos没有考虑-()的情况,属于拘泥于“表达式因子没有系数”这一想法,忘了第一个系数可以省略(明显是第三次指导书中与第二次重复的的部分懒得看了)。
三、互测体会
因为不了解对拍,我在互测阶段采用的方法是阅读代码、针对性构造样例。例如第一次互测时阅读了房间所有人的代码,仔细研究正则表达式是否有不完善的、项录入后的处理有没有问题等等。
这种策略在第一二次作业还是相对有效的,第一次作业中针对构造的样例有时还能“命中”其他人,最后刀的人还是挺多的,虽然最后分数一算并没有多少。
但是第三次代码量增大、同时取消WF之后这种方法就非常不实用了。这次根本没有时间阅读长代码,即使读了理解了也很难马上指出漏洞(递归的执行过程缺少一定规律,只能检查递归的结束条件和每一步执行有没有问题)。第三次我依然有尝试结合被测程序结构构造样例,但效果平平。
四、可能的改进
以难度最高的第三次作业为例,可以考虑引入简单工厂模式。我目前在factor这一层,根据因子的不同分为三种情况,构建power/sin/cos类,现在如果引入了因子ln(x),那我不仅需要在最底层加入一个ln类,同时factor中的判断语句也要修改。因此,如果改为每次建立底层因子时都调用一个工厂类,由工厂类负责判断生产什么类,可以避免factor的结构过于复杂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号