JavaScript正则表达式(Regular Expression):RegExp对象
第一部分:新建正则表达式
JavaScript中正则表达式是参照Perl 5(一门历史很悠久的语言,现在tiobe编程语言排行依然在10名左右)建立的。
新建正则表达式的方法有两种:
1.使用字面量(斜杠/开始和结束) 注:字面量:表示固定值的符号。可以简单理解为表示值最简单、最基本的写法。
1 var reg1=/test/; 2 console.log(reg1,typeof reg1);
运行结果:

2.使用RegExp构造函数。
1 var reg2=new RegExp('test'); 2 console.log(reg2,typeof reg2);
运行结果:

注意:虽然两者运行结果一致。但是它们还是存在着差别:第一种方法是在编译时(代码载入时)新建正则表达式;而第二种是在运行时(代码执行时)新建正则表达式。
一般均采用字面量的写法,推荐!
第二部分:RegExp对象的属性和方法
2.1属性
2.1.1:修饰符,返回布尔值
- ignoreCase:忽略大小写;i;属性只读
- global:全局匹配;g;属性只读
- multiline:多行匹配;m;属性只读
1 var reg3=/test/ig; 2 console.log(reg3.ignoreCase,reg3.global,reg3.multiline);
运行结果:
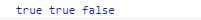
2.1.2 :不是修饰符
- lastIndex:返回下一次搜索的位置;属性可读写;设置了g修饰符才有意义
- source:返回正则表达式的字符串形式(不包括反斜杠);属性只读
1 var reg3=/test/ig; 2 console.log(reg3.lastIndex,reg3.source);
运行结果:

2.2方法
2.2.1 test():当前模式是否能匹配参数字符串
如下:'test_test_'参数字符串包含模式test,所以返回true。
1 var res1=/test/.test('test_test_'); 2 console.log(res1);//true
正则表达式带有g修饰符:每次进行匹配的位置是上一次匹配成功的位置+1;如果匹配不成功,那么又会从头开始进行匹配
1 var res1=/test/.test('test_test_'); 2 console.log(res1);//true 3 4 var reg4=/a/g; 5 var s='abcabcabc'; 6 7 console.log(reg4.lastIndex);//0 8 console.log(reg4.test(s));//true 9 10 console.log(reg4.lastIndex);//1:上次匹配成功的位置+1 11 console.log(reg4.test(s));//true 12 13 console.log(reg4.lastIndex);//4 14 console.log(reg4.test(s));//true 15 16 console.log(reg4.lastIndex);//7 17 console.log(reg4.test(s));//false 18 19 //又开始从头进行匹配 20 console.log(reg4.lastIndex);//0 21 console.log(reg4.test(s));//true
运行结果:

因此,带有g修饰符的正则对象,我们可以通过lastIndex属性进行指定开始匹配的位置
1 var reg5=/a/g; 2 var s1='aaaaab'; 3 reg5.lastIndex=5; 4 console.log(reg5.test(s1));//false
如果正则模式是一个空字符串,则匹配所有字符串
1 console.log(new RegExp('').test('abc'));//true
2.2.2:exec():匹配成功,返回数组;匹配失败,返回null
1 var reg6=/ab/; 2 var s2='abcabcd'; 3 console.log(reg6.exec('cdef'));//匹配不成功,null 4 console.log(reg6.exec(s2));
运行结果:

所以可以明显看出:exec()返回的数组中还包含着index和input属性。
- index:模式匹配成功的第一个位置(0开始计数);
- input:参数字符串
如果正则表达式中包含圆括号(即"组匹配"),返回的数组会包含多个成员;第一个成员是整个匹配成功的结果,第二个成员是圆括号里面匹配成功的结果。以此类推
1 var reg7=/_(ab)/; 2 var s3='_abc_abcd'; 3 console.log(reg7.exec(s3));
运行结果:
第一个成员是整个匹配的结果;第二个参数是圆括号匹配的结果。
非捕获组:(?:):表示不返回该组匹配的内容;也就是说匹配的结果不计入括号
1 var m1='abc'.match(/(.)b(.)/); 2 var m2='abc'.match(/(?:.)b(?:.)/); 3 console.log(m1); 4 console.log(m2);
运行结果:

如果正则表达式加上g修饰符,则可以多次使用exec方法:
1 console.log('---'); 2 var reg8=/_(a+)_/g; 3 var s4='_a_bc_aa_de_a_f'; 4 var res1=reg8.exec(s4); 5 console.log(res1,res1.index,reg8.lastIndex);// 0 3 6 var res2=reg8.exec(s4); 7 console.log(res2,res2.index,reg8.lastIndex);// 5 9 8 var res3=reg8.exec(s4); 9 console.log(res3,res3.index,reg8.lastIndex);// 11 14 10 var res4=reg8.exec(s4); 11 console.log(res4,reg8.lastIndex);//此处不能读取index,因为为null,读取则报错 12 var res5=reg8.exec(s4); 13 console.log(res5,res5.index,reg8.lastIndex);// 0 3
运行结果:

第三部分:字符串对象方法
- match():返回一个数组;成员是所有匹配的子字符串
- search():返回一个整数;表示匹配开始的位置
- replace():按照给定的正则表达式进行替换;返回替换后的字符串
- split():按照给定规则对字符串进行分割;返回一个数组,包含分割后各个成员
3.1:String.prototype.match():字符串的match()方法与正则对象的exec()方法十分相似:匹配成功返回数组;匹配失败返回null;
区别:当正则表达式带有g修饰符,match()会返回所有结果;而exec()返回一个结果。
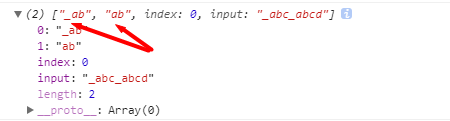
1 var reg9=/te/; 2 var s5='teatebtec'; 3 console.log(s5.match(reg9)); 4 console.log(reg9.exec(s5)); 5 var reg10=/te/g; 6 console.log(s5.match(reg10)); 7 console.log(reg10.exec(s5));
运行结果:
注意:设置lastIndex属性对match()方法无效。
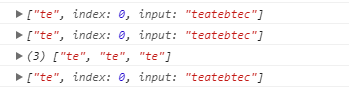
1 reg10.lastIndex=2; 2 console.log(s5.match(reg10),reg10.lastIndex);
运行结果:

可以看出此时reg10.lastIndex依然为0。表明每次match()匹配都是从第一个字符开始的。
3.2 String.prototype.search():返回第一次匹配成功在整个字符串的位置;否则返回-1
同样的,设置lastIndex属性对search()无效;并且search()会忽略g修饰符
1 var reg11=/te/; 2 var s6='te_teabc'; 3 console.log(s6.search(reg11));//0 4 reg11.lastIndex=2;//设置lastIndex属性无效 5 console.log(s6.search(reg11),reg11.lastIndex);//0 2 6 var reg12=/te/g;//设置g修饰符无效 7 console.log(s6.search(reg12));//0
运行结果:

3.3 String.prototype.replace():返回替换后的字符串;有两个参数,第一个是搜索模式(正则),第二个是替换的内容
1 console.log('abaac'.replace('a','F'));//Fbaac 2 console.log('abaac'.replace(/a/,'F'));//Fbaac 3 console.log('abaac'.replace(/a/g,'F'));//FbFFc
运行结果:

3.4 String.prototype.split():按照正则规则切割字符串;返回数组包含切割后的部分
1 console.log('a, b,c'.split(','));//["a", " b", "c"] 2 console.log('a, b,c'.split(/, */));//["a","b","c"]
4.匹配规则
4.1:字面量字符(literal characters):比如:/a/,/cat/
4.2:元字符(meta characters):有特殊含义;不代表字面意思
4.2.1:点字符(.):匹配除回车(\r)、换行(\n)、行分隔符(\u2028)和段分隔符(\u2029)以外的所有字符。
4.2.2:位置字符
- ^:表示字符串的开始位置
- $:表示字符串的结束位置
4.2.3:选择字符:竖线符号(|):表示或的关系;比如apple|boy:匹配apple或者boy
4.2.4:转义符:因为有些字符在匹配规则中有着特殊的含义,所以要想匹配它们,得进行转义(在前面加上反斜杠\);比如匹配^,写成\^
需要转义的12个字符:^;.;[;$;(;);|;*;+;?;{和\\
注意:如果使用RegExp生成正则对象,转义需要两个反斜杠,因为字符串内部转义需要一次\
1 //匹配'+abc'字符串 2 var reg13=new RegExp('\\+abc');//正确写法 3 var reg14=new RegExp('\+abc');//错误写法
4.2.5:特殊字符

4.2.6:字符类:放置在[]中
1. ^:放置在[]中首位;如:[^abc]表示除a,b,c之外的字符都能进行匹配;如果[]中没有其它字符,表示匹配一切字符(包括换行符);而.是不包括换行符的。
2. -:如:[a-z]:匹配a-z这26个字符
4.2.7:预定义模式:

4.2.8:重复类
精确匹配次数:{n}:重复n次;{n,}:至少n次;{n,m}:n到m次
4.2.9:量词符

4.2.10:贪婪模式:(?,*,+)默认情况下,最大可能的匹配;改为非贪婪模式,在量词后面加个?
如:/a+?/:一旦匹配成功,就不会继续匹配下去


 浙公网安备 33010602011771号
浙公网安备 33010602011771号