搭建分布式 Redis Cluster 集群与 Redis 入门
发现写过一篇 ASP.NET Core 使用 Redis 的文章,入门比较简单:https://www.cnblogs.com/whuanle/p/11360468.html
Redis 集群搭建
Redis 是啥
Redis(全称 REmote DIctionary Server) 是 NoSQL 型数据存储程序,其使用了内存来存储数据结构,可以作为数据库、缓存、消息代理使用。
Redis 使用键值来映射数据,其数据结构支持 strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes 等类型。
集群(Cluster)
Redis 集群的官方文档:https://redis.io/topics/cluster-tutorial
学这个的时候,建议别老是百度,还是好好啃一下官方文档,一点点学吧。
Redis 支持三种集群模式:
- 主从模式
- Sentinel(哨兵)模式
- Cluster 模式
本章的内容包括搭建、测试和操作 Redis Cluster(集群)。
主从模式,一个 Primary,多个 Secondary ,以及副本节点。
哨兵模式,不会。
Cluster 模式,主要为了提高并发能力和解决性能瓶颈。
Redis Cluster 说明
Redis Cluster 能够保证 Redis 服务一定程度的可用性,当集群中一部分实例发生故障时,其余实例还能正常运行。但是如果发生较大故障,整个 Redis 集群可能会停止运行。
Redis 集群的每个节点都需要使用两个 TCP 端口,一个是常规提供给客户端服务的端口,如 6379;而群集总线需要使用的端口是常规端口加上 10000 ,例如 73479。
Redis Cluster 不支持 NATted 环境,也就是不支持 Docker 重新映射端口,如果要在 Docker 上使用 Redis 集群,则需要使用 Dockers
主机模式,即启动 Redis 时要附加 --net=host 参数。
Redis Cluster 中,提供服务的都是 主节点(redis-master),从属节点(redis-slave) 用于备份主节点的数据,当主节点故障时,从属节点可以替换主节点。
Redis Cluster 节点
Redis 多个 Redis 实例来提供功能,即分片功能,每个 Redis 实例都是主节点。例如 A、B、C 三个节点集组成一个完整的 Redis 系统,redis cluster 自动将数据分片(sharding),在每个节点上放置一部分数据,这三个节点都是主节点。
例如 有 100 条数据,前 40 条在 A中,剩下的在 B、C中。
没有 primary,每个主节点都可以提供服务,这样就降低了服务器的压力,尽量使得流量被多台节点平均。要删除 C ,则将 C 的数据分为两部分,分别推送到 A 和 B 中,这就是数据复制。
但是,如果 C 故障了,那么整个集群则会瘫痪,因为 A、B、C 各自的数据是不同的。这就是 Redis Cluster 的缺点。
更多知识,请打开官方文档了解 https://redis.io/topics/cluster-tutorial
后面使用 & 符号来代表从属节点,如 &C,代表 C 的从属节点。
Redis Cluster 集群模式
Redis Cluster 集群,每个主节点有多个从属节点,从属节点的数据于此主节点一致。
前面提到过如果某一个主节点故障,将会导致整个集群故障。因此,每个主节点都应该有一个从属节点,当 C 故障时,&C (跟 C 具有一致的数据)将代替 C 工作。但是如果 C 和 &C 都故障,则整个系统也是会故障的。
Redis Cluster 的工作依赖于 redis.conf 文件。
下面我们将来一步步手动建立集群,过程会比较慢,如果需要尽快建立集群,可以百度找脚本。
为了真实,笔者使用两台服务器搭建服务,共三个主节点和三个从属节点,组成六个节点群集。
不能保证一致性
当客户端向 C 节点写入数据时,C 会向 &C 写入数据以保证一致性(同步)。但是这个同步过程是异步的,因为用户跟 C 交互,完成交互即返回,不可能要用户等待所有的过程完成,所以 Redis 的设计是,用户到 C 是同步,操作后立即返回;而 C 到 &C 是异步的,完全与用户无关。
如果客户端写入数据到 C 后,C 还没有同步数据到 &C,C 就故障了,那么这部分数据就会丢失。因此这个从属节点,并不能保证数据的一致性。
创建和使用 Redis 集群
笔者有两台服务器,其理论设计如下:
| 服务器 | 节点 | port | cluster port |
|---|---|---|---|
| 服务器1 | A | 7001 | 17001 |
| 服务器1 | B | 7002 | 17002 |
| 服务器1 | C | 7003 | 17003 |
| 服务器2 | &A | 7001 | 17001 |
| 服务器2 | &B | 7002 | 17002 |
| 服务器2 | &C | 7003 | 17003 |
实际上,由于启动集群时,节点是自动分配的,哪个是主节点哪个是从属节点是机器分配,因此这里只是作为一个设计思路处理,实际情况要看输出结果。
部署三个主节点
在服务器 1,创建六个目录:
mkdir /var/redis
cd /var/redis
mkdir 7001 7002 7003 A B C
7001、7002、7003 都是以端口命名的,分别存储 A、B、C 三个节点的配置文件,而 A、B、C 三个文件是为了使用 Docker 启动时,映射物理文件(备份数据)。如果你不是使用 docker 启动,则不需要 A、B、C 三个目录。
三个端口目录分别创建一个 redis.conf 文件,port 的内容请根据端口填写,其内容如下:
port 7001
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
记得改掉 7001。
如果你只有一台服务器,就使用 7001-7006 和 A B C D E F 这这目录。
非 docker
如果不使用 docker 的话, 可以这样启动 redis:
# 命令
redis-server /var/redis/7001/redis.conf
# 二进制文件
./redis-server /var/redis/7001/redis.conf
# 如法炮制
docker 安装
如果服务器的内存比较低,例如 1G,2G,则需要执行下面的命令,消除 Redis 警告。
查看 /proc/sys/net/core/somaxconn 文件,如果值是 128,则需要修改为 1024。
修改内存限制:
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
还有一个内核问题:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
其它问题请参考这里 https://blog.csdn.net/a491857321/article/details/52006376
拉取最新 redis 镜像:
docker pull redis:latest
执行以下三个命令启动三个 redis 实例:
docker run -itd --name redisa --net=host -v /var/redis/A:/data -v /var/redis/7001:/etc/redis redis:latest redis-server /etc/redis/redis.conf --appendonly yes
docker run -itd --name redisb --net=host -v /var/redis/B:/data -v /var/redis/7002:/etc/redis redis:latest redis-server /etc/redis/redis.conf --appendonly yes
docker run -itd --name redisc --net=host -v /var/redis/C:/data -v /var/redis/7003:/etc/redis redis:latest redis-server /etc/redis/redis.conf --appendonly yes
把本小节的内容,在另一台服务器上执行相同的操作。如果你是一台服务器,则也可以在这里修改一下,创建 6 个容器。
命令解析:
--net=host :使用主机网络,这样就不需要使用 -p 来映射端口了;
-v /var/redis/B:/data :数据持久化;
/var/redis/7002:/etc/redis :将物理机目录映射到容器中,里面有个配置文件;
redis-server : 启动容器时执行的命令;
/etc/redis/redis.conf :一个启动参数,告诉 redis-server ,要使用哪个配置启动;
--appendonly yes :总是重启;
创建集群
如果使用 docker 安装,则在第一台服务器执行命令进入容器。
docker exec -it redisa bash
然后创建集群:
redis-cli --cluster create {ip}:7001 {ip}:7002 {ip}:7003 {ip}:7001 {ip}:7002 {ip}:7003 --cluster-replicas 1
注:请自行替换 ip 地址。
执行命令后,会自动分配 redis 实例的地位,输入 yes 同意这种分配:
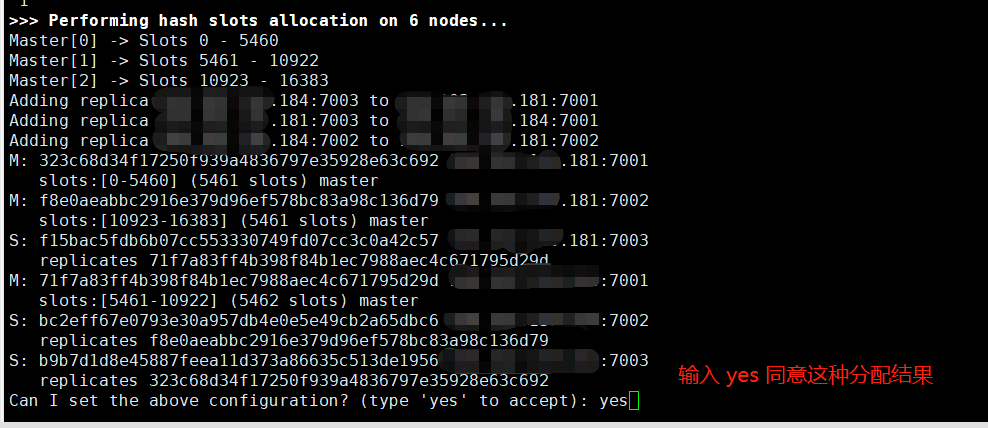
这种自动分配是最优的,避免三台主节点都在同一台服务器中。
集群搭建完毕,我们来开始学习 Redis 中的一些概念,然后使用 C# 创建程序连接 Redis 。
Redis 入门
Redis 中的数据类型
Redis 中,常用的数据类型有以下几种:
- String 字符串
- Hash 散列/哈希
- List 列表
- Set 集合
- Sorted Set 有序集合
所有数据都是 key-value 形式存储,每个数据都有唯一的 key,以上数据类型是 value。
删除一个数据的命令:DEL {key} 。
字符串(string)
字符串没啥好说的,就是 value 为 string。
Redis 命令,要设置或使用字符串类型的数据,则使用SET 或 GET 开头的命令:
# 设置字符串
SET a AAA
SET b 666
# 其中 a 是 key,AAA 是 value,不需要 "" 包围字符串
# ------
# 获取字符串
GET a
# ------
# 获取多个字符串
MGET a b
# 使用空格分隔 key
因为 redis 没有值类型,因此使用不加 "" 也会被识别为字符串。建议加上双引号比较好,提高可读性。
哈希(Hash)
一个 string 类型,是 key-value 结构,而哈希则是 {key-value} 的集合,key 是 string 类型,value 可以是其它类型。
因此,可以称 Hash 为键值对的集合,就是相当于 C# 中的字典类型,主要存储有结构的数据。
Redis 中每个 hash 可以存储 232 - 1 个键值对(40多亿)。
Hash 使用 HMSET 、 HMGET 、HGETALL 等命令来操作哈希表。
有一个这个的数据:
id:1,
name:"痴者工良"
使用哈希存储:
# HMSET {key} {filed1} {value1} {filed2} {value2} ... ...
HMSET user id "1" name "痴者工良"
查询此哈希表的所有键值对:
HGETALL user
查看哈希表的一个字段:
HGET user id
删除其中一个字段:
HDEL user {字段名称}
列表(Lists)
列表中可以添加多中类型的元素,简单的就是字符串,列表即是数据结构中的链表,使用双向列表技术实现,越靠近两侧的元素速度越快。
子元素的添加要从头部或尾部加入,由于列表是栈,因此列表是有序的。因为列表是有序的,因此可以存储重复的数据。
适合做例如消息记录(队列),粉丝关注记录、订单记录等。
列表只能添加字符串。
往一个列表加入数据:
LPUSH {key} {一个元素值}
例如:
LPUSH list a
LPUSH list b
LPUSH list c
列表的命令比较多,自己查询文档就好,这里不再赘述。
集合(Set)
列表(List)是有序的,集合(Set)是无序的。集合不能出现重复的数据。
应用场景如网站的访问IP(去重)记录、花店中花的种类等。
集合是字符串元素的集合,只能存储字符串。
使用 SADD 命令往集合中添加一个元素:
SADD set a
SADD set b
SADD set c
SADD set a b c
有序集合(sorted set)
有序集合跟集合一样,只是有有序集合会根据元素的值从小到大排序。
有序集合也只能添加字符串。
ZADD ss 2 a
ZADD ss 1 b
ZADD ss 4 z
查询:
ZRANGE ss 0 10 WITHSCORES
提醒一下,生产环境记得给 Redis 设置密码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号