

搭建ceph集群
本文参考 https://www.cnblogs.com/qiuhom-1874/p/16724473.html
部署工具介绍
1、ceph-deploy:该部署工具是ceph官方的部署工具,它只依赖SSH访问服务器,不需要额外的agent;它可以完全运行在自己的工作站上(比如admin host),不需要服务器,数据库类似的东西;该工具不是一个通用的部署工具,只针对ceph;相比ansible,puppet,功能相对单一;该工具可以推送配置文件,但它不处理客户端配置,以及客户端部署相关依赖等;
2、ceph-ansible:该工具是用ansible写的剧本角色,我们只需要把对应的项目克隆下来,修改必要的参数,就可以正常的拉起一个ceph集群;但这前提是我们需要熟练使用ansible;项目地址 https://github.com/ceph/ceph-ansible;
3、ceph-chef:chef也是类似ansible、puppet这类自动化部署工具,我们需要手动先安装好chef,然后手动写代码实现部署;ceph-chef就是写好部署ceph的一个项目,我们可以下载对应项目在本地修改必要参数,也能正常拉起一个ceph集群;前提是我们要熟练使用chef才行;项目下载地址https://github.com/ceph/ceph-chef;
4、puppet-ceph:很显然该工具就是用puppet写好的部署ceph的模块,也是下载下来修改必要参数,就可以正常拉起一个ceph集群;
不管用什么工具,我们首先都要熟练知道ceph集群架构,它的必要组件,每个组件是怎么工作的,有什么作用,需要怎么配置等等;除此之外我们还需要熟练使用各种自动化部署工具,才能很好的使用上述工具部署ceph集群;
集群拓扑网络
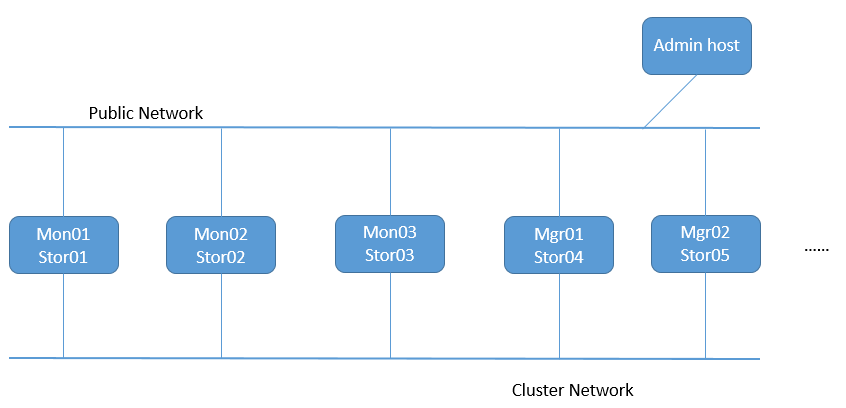
提示:Public Network是指公共网络,专供客户端连接ceph集群使用;一般如果节点不多,集群规模和用户的访问量不大的情况下,只有一个public network也是完全ok;存在cluster network主要原因是,集群内部的事务处理,可能影响到客户端在ceph存储数据;所以cluster network是集群私有网络,专门用于集群内部各组件通信协调使用;我们用于部署ceph的admin host 只需要有一个公共网络连入集群下发配置即可;
Ceph集群系统基础环境设定
| 主机地址 | 角色 |
|---|---|
| public network:192.168.0.70/24 | admin host |
| public network:192.168.0.71/24 cluster network:172.16.30.71/24 | mon01/stor01 |
| public network:192.168.0.72/24 cluster network:172.16.30.72/24 | mon02/stor02 |
| public network:192.168.0.73/24 cluster network:172.16.30.73/24 | mon03/stor03 |
| public network:192.168.0.74/24 cluster network:172.16.30.74/24 | mgr01/stor04 |
| public network:192.168.0.75/24 cluster network:172.16.30.75/24 | mgr02/stor05 |
各主机主机名解析
92.168.0.70 ceph-admin ceph-admin.ilinux.io
192.168.0.71 ceph-mon01 ceph-mon01.ilinux.io ceph-stor01 ceph-stor01.ilinux.io
192.168.0.72 ceph-mon02 ceph-mon02.ilinux.io ceph-stor02 ceph-stor02.ilinux.io
192.168.0.73 ceph-mon03 ceph-mon03.ilinux.io ceph-stor03 ceph-stor03.ilinux.io
192.168.0.74 ceph-mgr01 ceph-mgr01.ilinux.io ceph-stor04 ceph-stor04.ilinux.io
192.168.0.75 ceph-mgr02 ceph-mgr02.ilinux.io ceph-stor05 ceph-stor05.ilinux.io
172.16.30.71 ceph-mon01 ceph-mon01.ilinux.io ceph-stor01 ceph-stor01.ilinux.io
172.16.30.72 ceph-mon02 ceph-mon02.ilinux.io ceph-stor02 ceph-stor02.ilinux.io
172.16.30.73 ceph-mon03 ceph-mon03.ilinux.io ceph-stor03 ceph-stor03.ilinux.io
172.16.30.74 ceph-mgr01 ceph-mgr01.ilinux.io ceph-stor04 ceph-stor04.ilinux.io
172.16.30.75 ceph-mgr02 ceph-mgr02.ilinux.io ceph-stor05 ceph-stor05.ilinux.io
各主机配置ntp服务设定各节点时间精准同步
[root@ceph-admin ~]# sed -i 's@^\(server \).*@\1ntp1.aliyun.com iburst@' /etc/chrony.conf
[root@ceph-admin ~]# systemctl restart chronyd
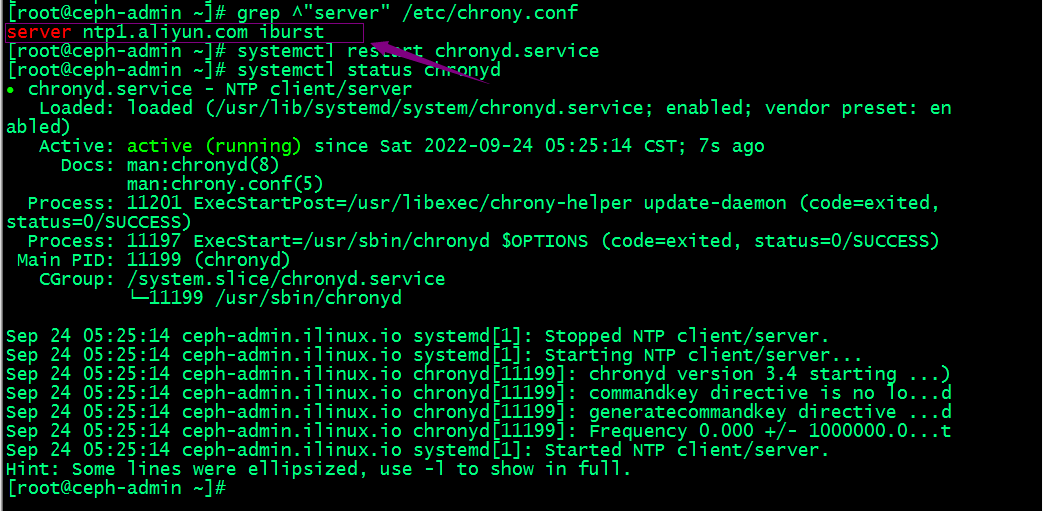
提示:上述服务器都需要在chrony.conf中配置同步时间的服务器,这里推荐使用阿里云,然后重启chronyd服务即可;
各节点关闭iptables 或firewalld服务
[root@ceph-admin ~]# systemctl stop firewalld
[root@ceph-admin ~]# systemctl disable firewalld
[root@ceph-admin ~]# sed -i 's@^\(SELINUX=\).*@\1Disabled@' /etc/sysconfig/selinu
[root@ceph-admin ~]# setenforce 0
提示:上述sed命令表示查找/etc/sysconfig/selinux配置文件中,以SELINUX开头的行当所有内容,并将其替换为SELINUX=Disabled;ok,准备好集群基础环境以后,接下来我们开始部署ceph;
准备yum仓库配置文件(https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm)
[root@ceph-admin ~]# rpm -ivh ceph-release-1-1.el7.noarch.rpm
[root@ceph-admin ~]# yum install -y epel-release
到此ceph的yum仓库配置文件就准备好了
在集群各节点创建部署ceph的特定用户帐号
[root@ceph-admin ~]# useradd cephadm && echo "admin" |passwd --stdin cephadm
提示:部署工具ceph-deploy 必须以普通用户登录到Ceph集群的各目标节点,且此用户需要拥有无密码使用sudo命令的权限,以便在安装软件及生成配置文件的过程中无需中断配置过程。不过,较新版的ceph-deploy也支持用 ”--username“ 选项提供可无密码使用sudo命令的用户名(包括 root ,但不建议这样做)。另外,使用”ceph-deploy --username {username} “命令时,指定的用户需要能够通过SSH协议自动认证并连接到各Ceph节点,以免ceph-deploy命令在配置中途需要用户输入密码。
确保集群节点上新创建的cephadm用户能够无密码运行sudo权限
[root@ceph-admin ~]# echo "cephadm ALL = (root) NOPASSWD:ALL" |sudo tee /etc/sudoers.d/cephadm
[root@ceph-admin ~]# chmod 0440 /etc/sudoers.d/cephadm

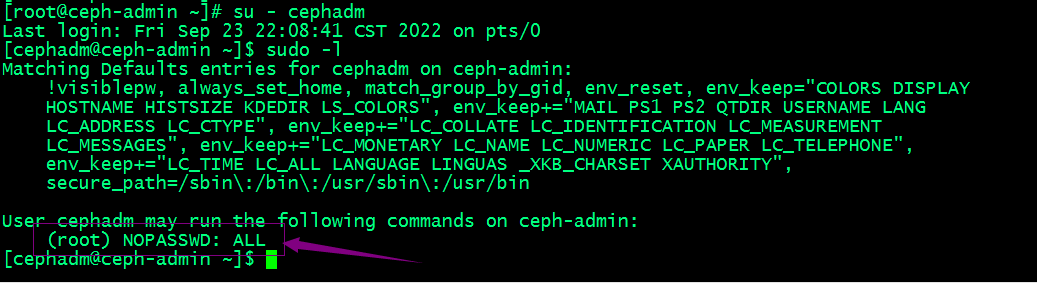
切换至cephadm用户,查看sudo权限
配置cephadm基于密钥的ssh认证
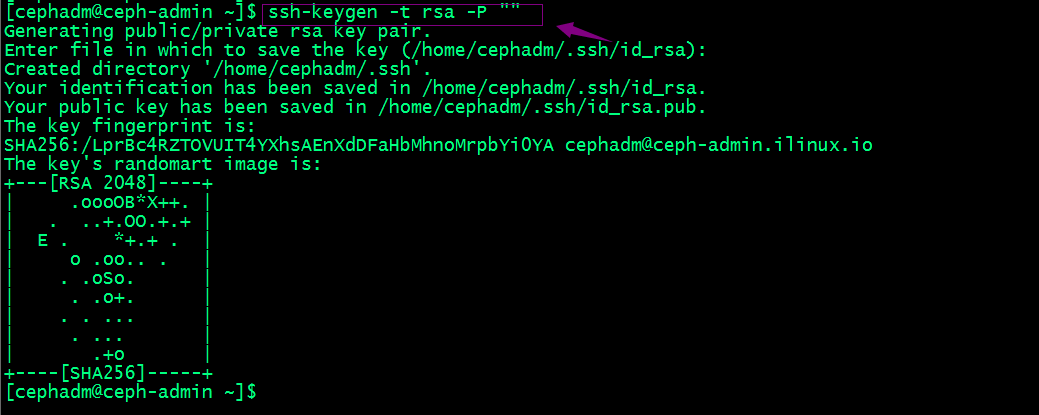
提示:先切换用户到cephadm下然后生成密钥;
拷贝公钥给自己
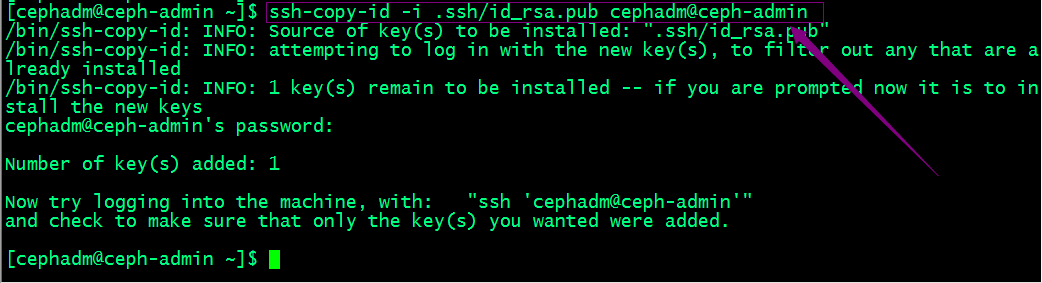
复制被地.ssh目录给其他主机,放置在cephadm用户家目录下
[cephadm@ceph-admin ~]$ scp -rp .ssh cephadm@ceph-mon01:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh cephadm@ceph-mon02:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh cephadm@ceph-mon03:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh cephadm@ceph-mgr01:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh cephadm@ceph-mgr02:/home/cephadm/
验证:以cephadm用户远程集群节点,看看是否是免密登录

提示:能够正常远程执行命令说明我们的免密登录就没有问题;
在admin host上安装ceph-deploy
[cephadm@ceph-admin ~]$ sudo yum update
[cephadm@ceph-admin ~]$ sudo yum install ceph-deploy python-setuptools python2-subprocess32
验证ceph-deploy是否成功安装
[cephadm@ceph-admin ~]$ ceph-deploy --version
2.0.1
[cephadm@ceph-admin ~]$
提示:能够正常看到ceph-deploy的版本,说明ceph-deploy安装成功;
部署RADOS存储集群
1、在admin host以cephadm用户创建集群相关配置文件目录
[cephadm@ceph-admin ~]$ mkdir ceph-cluster
[cephadm@ceph-admin ~]$ cd ceph-cluster
[cephadm@ceph-admin ceph-cluster]$ pwd
/home/cephadm/ceph-cluster
[cephadm@ceph-admin ceph-cluster]$
2、初始化第一个mon节点
提示:ceph-deploy new的命令格式 我们只需要对应节点的主机名即可;但是前提是对应主机名做了正确的解析;
[cephadm@ceph-admin ceph-cluster]$ sudo ceph-deploy new ceph-mon01
提示:我们可以在命令行使用--public-network 选项来指定集群公共网络和使用--cluster-network选项来指定对应集群网络;当然也可以生成好配置文件,然后在配置文件里修改也行;
3、修改配置文件指定集群的公共网络和集群网络
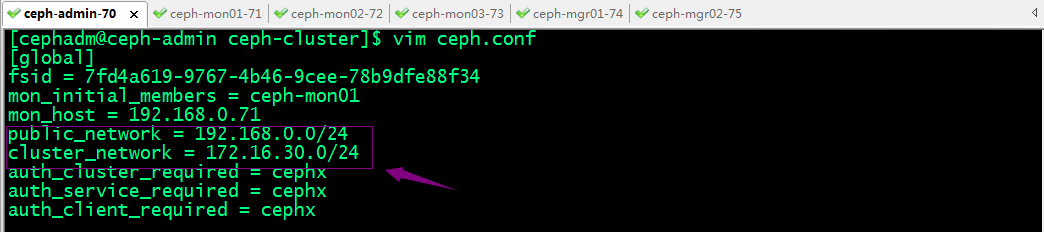
提示:编辑生成的ceph.conf配置文件,在【global】配置段中设置ceph集群面向客户端通信的网络ip地址所在公网网络地址和面向集群各节点通信的网络ip地址所在集群网络地址,如上所示;
4、安装ceph集群
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy install ceph-mon01 ceph-mon02 ceph-mon03 ceph-mgr01 ceph-mgr02
提示:ceph-deploy命令能够以远程的方式连入Ceph集群各节点完成程序包安装等操作,所以我们只需要告诉ceph-deploy 那些主机需要安装即可;
集群各主机如果需要独立安装ceph程序包,方法如下(后面安装会自动安装,此处不用执行)
yum install ceph ceph-radosgw
再次在admin host上用ceph-deploy安装ceph集群
提示:如果在最后能够看到ceph的版本,说明我们指定的节点都已经安装好对应ceph集群所需的程序包了;
5、配置初始MON节点,并收集所有密钥
查看ceph-deploy mon帮助
提示:add 是添加mon节点,create是创建一个mon节点,但不初始化,如果要初始化需要在对应节点的配置文件中定义配置mon成员;create-initial是创建并初始化mon成员;destroy是销毁一个mon移除mon节点;
初始化mon节点
[cephadm@ceph-admin ceph-cluster]$ sudo ceph-deploy mon create-initial
提示:从上面的输出信息可以看到该命令是从当前配置文件读取mon节点信息,然后初始化;我们在上面的new 命令里只有给了mon01,所以这里只初始化了mon01;并在当前目录生成了引导mds、mgr、osd、rgw和客户端连接ceph集群的管理员密钥;
6、拷贝配置文件和admin密钥到集群各节点
提示:ceph-deploy admin命令主要作用是向指定的集群主机推送配置文件和客户端管理员密钥;以免得每次执行”ceph“命令行时不得不明确指定MON节点地址和ceph.client.admin.keyring;
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy admin ceph-mon01 ceph-mon02 ceph-mon03 ceph-stor04 ceph-stor05
提示:推送配置和管理员密钥我们只需要后面跟上对应集群主机即可,注意主机名要做对应的解析;这里还需要多说一句,配置文件是集群每个节点都需要推送的,但是管理密钥通常只需要推送给需要在对应主机上执行管理命令的主机上使用;所以ceph-deploy config命令就是用于专门推送配置文件,不推送管理密钥;
提示:ceph-deploy config 有两个子命令,一个是push,表示把本机配置推送到对应指定的主机;pull表示把远端主机的配置拉去到本地;
验证:查看mon01主机上,对应配置文件和管理员密钥文件是否都推送过去了?

提示:可以看到对应配置文件和管理员密钥都推送到对应主机上,但是管理员密钥的权限对于cephadm是没有读权限;
设置管理员密钥能够被cephadm用户有读权限
sudo setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
sudo getfacl /etc/ceph/ceph.client.admin.keyring
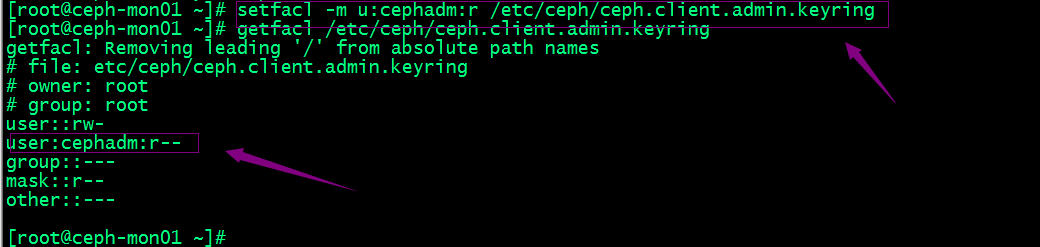
提示:上述设置权限的命令需要在每个节点都要设置;
7、配置Manager节点,启动ceph-mgr进程(仅Luminious+版本)
查看ceph-deploy mgr帮助
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mgr create ceph-mgr01 ceph-mgr02
在集群节点上执行ceph -s来查看现在ceph集群的状态
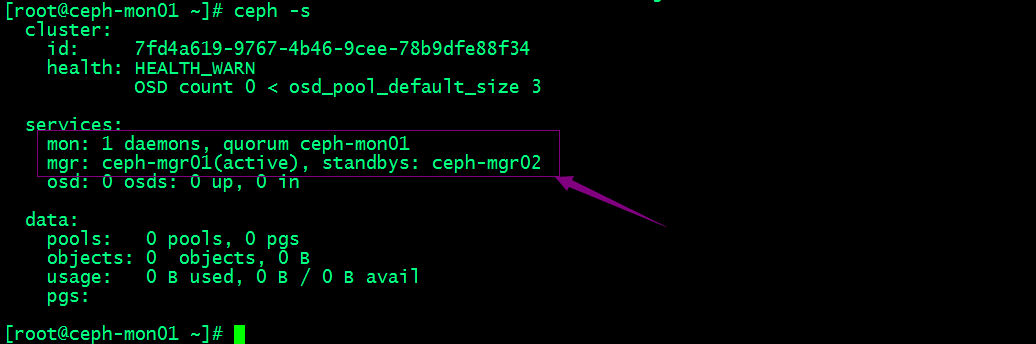
提示:可以看到现在集群有一个mon节点和两个mgr节点;mgr01处于当前活跃状态,mgr02处于备用状态;对应没有osd,所以集群状态显示health warning;
向RADOS集群添加OSD
列出并擦净磁盘
查看ceph-deploy disk命令的帮助
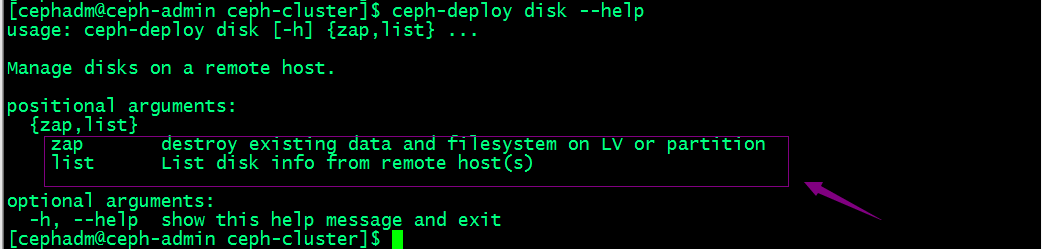
提示:ceph-deploy disk命令有两个子命令,list表示列出对应主机上的磁盘;zap表示擦净对应主机上的磁盘;
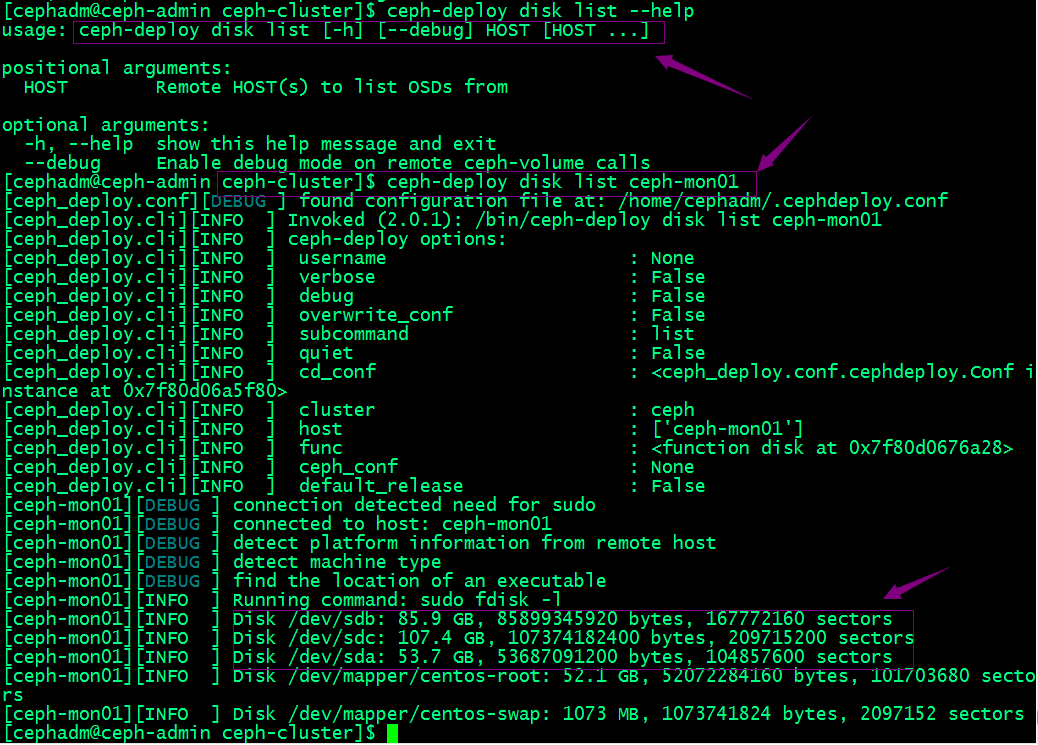
擦净mon01的sdb和sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap ceph-mon01 /dev/sdb /dev/sdc
提示:擦净磁盘我们需要在后面接对应主机和磁盘;若设备上此前有数据,则可能需要在相应节点上以root用户使用“ceph-volume lvm zap --destroy {DEVICE}”命令进行;
添加osd
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create ceph-mon01 --data /dev/sdb
查看集群状态
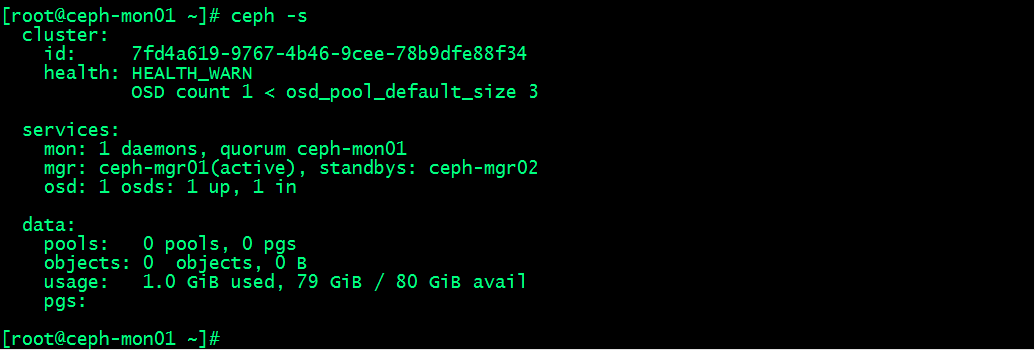
提示:可以看到现在集群osd有一个正常,存储空间为80G;说明我们刚才添加到osd已经成功;后续其他主机上的osd也是上述过程,先擦净磁盘,然后在添加为osd;
列出对应主机上的osd信息
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd list ceph-mon01
提示:到此我们RADOS集群相关组件就都部署完毕了;
管理osd ceph命令查看osd相关信息
1、查看osd状态
[root@ceph-mon01 ~]# ceph osd stat
10 osds: 10 up, 10 in; epoch: e56
#查看osd编号
[root@ceph-mon01 ~]# ceph osd ls
0
1
2
3
4
5
#查看osd映射状态
[root@ceph-mon01 ~]# ceph osd dump
#删除osd
[root@ceph-mon01 ~]# ceph osd out 0
#停止进程(不用执行)
systemctl stop ceph-osd@0
提示:停用进程需要在对应主机上停止ceph-osd@{osd-num};停止进程以后,对应集群状态就能看到对应只有9个osd进程处于up状态;
3、移除设备
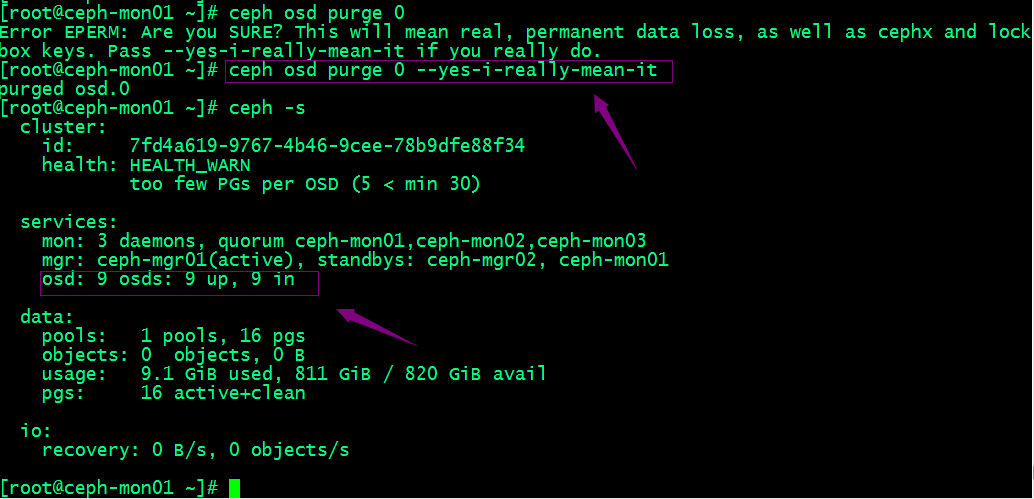
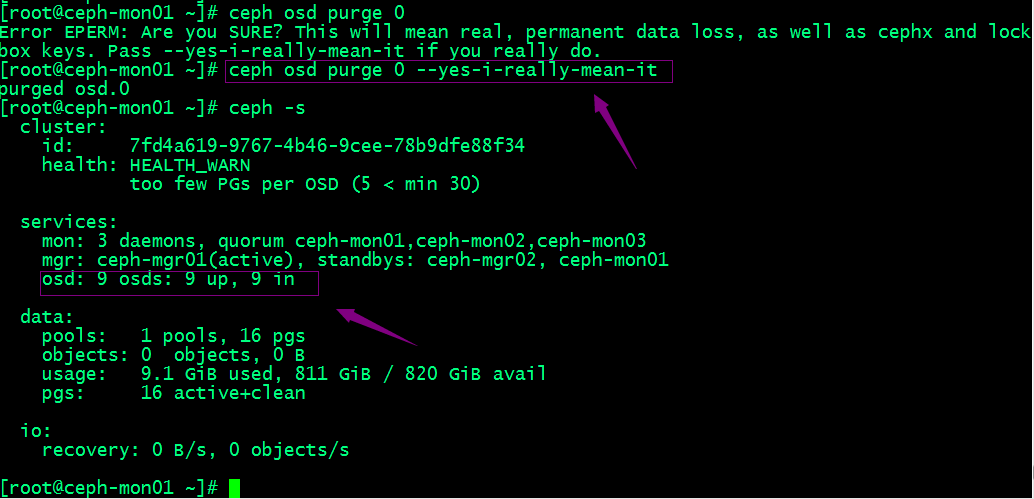
提示:可以看到移除osd以后,对应集群状态里就只有9个osd了;若类似如下的OSD的配置信息存在于ceph.conf配置文件中,管理员在删除OSD之后手动将其删除。
不过,对于Luminous之前的版本来说,管理员需要依次手动执行如下步骤删除OSD设备:
1. 于CRUSH运行图中移除设备:ceph osd crush remove {name}
2. 移除OSD的认证key:ceph auth del osd.{osd-num}
3. 最后移除OSD设备:ceph osd rm {osd-num}
测试上传下载数据对象
1、创建存储池并设置PG数量为16个
[root@ceph-mon01 ~]# ceph osd pool create testpool 16 16
pool 'testpool' created
[root@ceph-mon01 ~]# ceph osd pool ls
testpool
[root@ceph-mon01 ~]#
#上传文件到testpool
[root@ceph-mon01 ~]# rados put test /etc/issue -p testpool
[root@ceph-mon01 ~]# rados ls -p testpool
test
[root@ceph-mon01 ~]#
#获取存储池中数据对象的具体位置信息
[root@ceph-mon01 ~]# ceph osd map testpool test
osdmap e44 pool 'testpool' (1) object 'test' -> pg 1.40e8aab5 (1.5) -> up ([4,0,6], p4) acting ([4,0,6], p4)
[root@ceph-mon01 ~]#
#下载文件到本地
[root@ceph-mon01 ~]# ls
[root@ceph-mon01 ~]# rados get test test-down -p testpool
[root@ceph-mon01 ~]# ls
test-down
#删除数据对象
[root@ceph-mon01 ~]# rados rm test -p testpool
[root@ceph-mon01 ~]# rados ls -p testpool
[root@ceph-mon01 ~]#
#删除存储池
[root@ceph-mon01 ~]# ceph osd pool rm testpool
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool testpool. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[root@ceph-mon01 ~]# ceph osd pool rm testpool --yes-i-really-really-mean-it.
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool testpool. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[root@ceph-mon01 ~]#
提示:删除存储池命令存在数据丢失的风险,Ceph于是默认禁止此类操作。管理员需要在ceph.conf配置文件中启用支持删除存储池的操作后,方可使用类似上述命令删除存储池;
扩展ceph集群
扩展mon节点
Ceph存储集群需要至少运行一个Ceph Monitor和一个Ceph Manager,生产环境中,为了实现高可用性,Ceph存储集群通常运行多个监视器,以免单监视器整个存储集群崩溃。Ceph使用Paxos算法,该算法需要半数以上的监视器大于n/2,其中n为总监视器数量)才能形成法定人数。尽管此非必需,但奇数个监视器往往更好。“ceph-deploy mon add {ceph-nodes}”命令可以一次添加一个监视器节点到集群中。
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon add ceph-mon02
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon add ceph-mon03
扩展mgr节点
Ceph Manager守护进程以“Active/Standby”模式运行,部署其它ceph-mgr守护程序可确保在Active节点或其上的ceph-mgr守护进程故障时,其中的一个Standby实例可以在不中断服务的情况下接管其任务。“ceph-deploy mgr create {new-manager-nodes}”命令可以一次添加多个Manager节点。
把ceph-mon01节点添加为mgr节点
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mgr create ceph-mon01


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!