
haproxy+keepalived部署高可用k8s集群
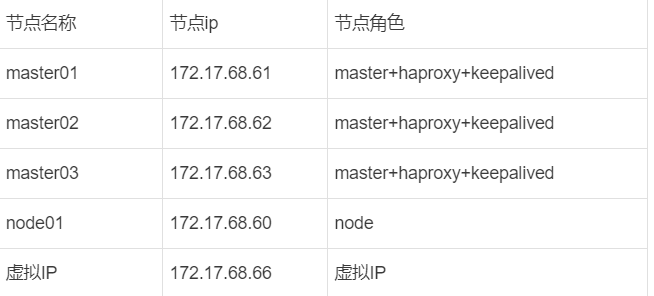
四台机器
节点名称节点ip节点角色
基础配置
1、升级机器内核
2、将机器ip 名称写入到/etc/hosts中
3、基础环境准备
#关闭防火墙,selinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
## 关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#系统优化
cat > /etc/sysctl.d/k8s_better.conf << EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cat >> /etc/security/limits.conf <<EOF
* soft nofile 1048576
* hard nofile 1048576
* soft nproc 1048576
* hard nproc 1048576
* hard memlock unlimited
* soft memlock unlimited
* soft msgqueue unlimited
* hard msgqueue unlimited
EOF
modprobe br_netfilter
lsmod |grep conntrack
modprobe ip_conntrack
sysctl -p /etc/sysctl.d/k8s_better.conf
#确保每台机器的uuid不一致,如果是克隆机器,修改网卡配置文件删除uuid那一行
cat /sys/class/dmi/id/product_uuid
#安装ipvs
yum install -y ipset ipvsadm
### 开启ipvs 转发
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules << EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack
安装docker
yum install -y yum-utils lvm2 device-mapper-persistent-data
yum-config-manager \
--add-repo \
https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce-20.10.24-3.el7
#编辑配置文件
mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://ioeo57w5.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"insecure-registries": ["xxx.com.cn" ],
"max-concurrent-downloads": 5,
"max-concurrent-uploads": 5,
"storage-driver": "overlay2",
"storage-opts": ["overlay2.override_kernel_check=true"],
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
EOF
#启动docker
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
使用cri-docker
#下载cri-docker(https://github.com/Mirantis/cri-dockerd)
#编写system管理文件
cat > /usr/lib/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container EngineDocumentation=https://docs.mirantis.com
After=network-online.target
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
ExecReload=/bin/kill -s HUP SMAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
# 写入socket配置文件
cat > /usr/lib/systemd/system/cri-docker.socket <<EOF
[Unit]
Description=CRI Docker Socket for the
APIPartof=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF
tee /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///var/run/cri-dockerd.sock
image-endpoint: unix:///var/run/cri-dockerd.sock
timeout: 10
debug: false
EOF
#解压文件
tar -zxvf cri-dockerd-0.3.1.amd64.tgz
mv cri-dockerd/cri-dockerd /usr/bin/
rm -rf cri-dockerd*
安装配置haproxy和keepalived
三台master节点上运行
yum -y install epel-release
yum -y install haproxy keepalived
#配置nginx和keepalived
[root@master01 haproxy]# cat haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4096
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
frontend kube-apiserver
mode tcp
bind *:8443
option tcplog
default_backend kube-apiserver
listen stats
mode http
bind *:8888
stats auth admin:password
stats refresh 5s
stats realm HAProxy\ Statistics #统计页面密码框上提示文本
stats uri /stats
log 127.0.0.1 local3 err
backend kube-apiserver
mode tcp
balance roundrobin
server master01 172.17.68.61:6443 check
server master02 172.17.68.62:6443 check
server master03 172.17.68.63:6443 check
##配置keepalived
[root@master01 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_1 #每个服务器名称需不同
router_id NGINX_MASTER #备机为NGINX_BUCKUP
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 2 #每两秒进行一次
weight -10 #如果script中的指令执行失败,vrrp_instance的优先级会减少10个点
}
vrrp_instance VI_1 {
state MASTER #备机为BUCKUP
interface ens192 #网口
virtual_router_id 51 #所有的需一致
priority 100 #master100,其他依次减10
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.17.68.66/24
}
track_script {
check_haproxy
}
}
#添加haproxy检查脚本
cat check_haproxy.sh
#!/bin/bash
flag=$(netstat -ntlp|grep 8443 |grep haproxy)
if [ -z "$flag" ]
then
systemctl stop keepalived
fi
chmod +x check_haproxy.sh
#修改 keepalived的service文件,保证keepalived在haproxy之后启动
[root@master02 ~]# cat /usr/lib/systemd/system/keepalived.service
[Unit]
Description=LVS and VRRP High Availability Monitor
After=syslog.target network-online.target haproxy.service
#启动haproxy
systemctl daemon-reload
systemctl start haproxy
#启动keepalived
systemctl start keepalived
#设置开机自启
systemctl enable keepalived
systemctl enable haproxy
安装kubeadm等工具
所有节点运行
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.24.0 kubeadm-1.24.0 kubectl-1.24.0
cat > /etc/sysconfig/kubelet <<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd --container-runtime=remote --container-runtime-endpoint=/var/run/cri-dockerd.sock"
EOF
systemctl daemon-reload
systemctl restart kubelet
systemctl enable kubelet
systemctl start cri-docker
systemctl enable cri-docker
初始化集群
master01机器上执行(keepalived虚拟ip所在节点执行)
#生产kubeadm配置文件
[root@master01 pki]# kubeadm config print init-defaults > kubeadm.yaml
[root@master01 ~]# cat kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.17.68.61 #修改为当前主机的IP地址
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
name: master01 #当前主机名称
taints:
- effect: "NoSchedule"
key: "node-role.kubernetes.io/master"
---
apiServer:
certSANs: #添加master机器的IP地址
- master01
- master02
- master03
- 172.17.68.61
- 172.17.68.62
- 172.17.68.63
- 172.17.68.66
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
controlPlaneEndpoint: 172.17.68.66:8443 #VIP地址:haproxy端口
imageRepository: registry.aliyuncs.com/google_containers
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
kind: ClusterConfiguration
kubernetesVersion: 1.24.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.10.0.0/16
podSubnet: 10.172.0.0/16
scheduler: {}
---
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
mode: "ipvs"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
#初始化集群
[root@master01 ~]# kubeadm init --upload-certs --config kubeadm.yaml
#最后会提示,由于我本地有多个contrainer,需要加上--cri-socket unix:///var/run/cri-dockerd.sock
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 172.17.68.66:8443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:24f2c2c1d9292cf825c6b471151f47782cfd \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.17.68.66:8443 --token w5tlcr.q2diata7xbuydv02 \
--discovery-token-ca-cert-hash sha256:24f2c2c1d9292cf825c6b471151f47782cfd
#记录下执行成功后的加入命令(该命令为node节点加入),集群加入时,自己修改为的VIP地址:haproxy端口(本文为8443)
#建立master节点的免密
ssh-keygen #创建密钥,一路回车
ssh-copy-id 172.17.68.62 #发送证书
#在master02和master03上执行
mkdir -p /etc/kubernetes/pki/etcd
#回到master01上执行
cd /etc/kubernetes/pki/
scp ca.* master02:/etc/kubernetes/pki/
scp sa.* master02:/etc/kubernetes/pki/
scp front-proxy-ca.* master02:/etc/kubernetes/pki/
scp etcd/ca.* master02:/etc/kubernetes/pki/etcd/
scp ../admin.conf master02:/etc/kubernetes/
scp ca.* master03:/etc/kubernetes/pki/
scp sa.* master03:/etc/kubernetes/pki/
scp front-proxy-ca.* master03:/etc/kubernetes/pki/
scp etcd/ca.* master03:/etc/kubernetes/pki/etcd/
scp ../admin.conf master03:/etc/kubernetes/
#新的master加入,master01上执行
kubeadm token create --print-join-command
#要加入的节点执行,上面输出的命名后面需要加上--control-plane
kubeadm join 172.17.68.66:8443 --token a930ez.69wo7j00zeu1gghq --discovery-token-ca-cert-hash sha256:2240cd1f54550c5a4a57b3d3a8671bca10fa6 --control-plane --cri-socket unix:///var/run/cri-dockerd.sock
##执行上面的报错
root@master02 pki]# kubeadm join 172.17.68.66:8443 --token v53imx.riq7fu1bkpxaeim7 --discovery-token-ca-cert-hash sha256:2240cd1f54550c5a4a57b3d3a8671bca10fa6 --control-plane --cri-socket unix:///var/run/cri-dockerd.sock
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
error execution phase preflight:
One or more conditions for hosting a new control plane instance is not satisfied.
unable to add a new control plane instance to a cluster that doesn't have a stable controlPlaneEndpoint address
Please ensure that:
* The cluster has a stable controlPlaneEndpoint address.
* The certificates that must be shared among control plane instances are provided.
To see the stack trace of this error execute with --v=5 or higher
#解决
kubectl -n kube-system edit cm kubeadm-config
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
controlPlaneEndpoint: 172.17.68.66:8443 #虚拟VIP和haproxy的端口
自行部署calico和ingress


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App