应对复杂软件的思考
由于自己身处SAAS行业,在经历了几轮复杂需求的蹂躏之后,我一直试图寻找一种解法,可以尽量cover住复杂多变的需求。在过去的一年中,通过反复阅读和实践,似乎让我对此有了一些清晰的思路,所以我想写一点东西总结一下自己的这一年里的思考。
在我们的项目初期,项目的规模可能比较小,代码量很少,我们的代码或许还能整理的比较干净,就像这几组交换机的网线一样,比较有条理。

但是随着功能复杂之后,项目也随之变得庞大,整个代码就可能会和这个机房一样,非常的混乱。在经历几次这种状况之后,于是我便在想,究竟是什么问题导致了这种混乱。

首先来看一段代码(Kotlin Code):
fun executeRequest(request: Request) : String {
// 校验身份
val isValidate = validateRequest(request)
if( isValidate ) {
return "Request is not valid"
}
// 处理业务
dealBiz(request)
try {
// 存储数据
saveToDB(request)
} catch (exception:Exception) {
return "Occur error when save results to DB"
}
// 发送消息
val isSendSuccess = sendMessage(request)
if (isSendSuccess == false) {
return "message send unsuccessfully."
}
return "success"
}
这是我们比较常见的一些代码结构,其实看起来问题也不算很大,但是随着业务复杂,业务逻辑的控制和控制逻辑耦合的很厉害,阅读这种"面条代码"的成本越来越高。每一位新进入项目的伙伴犹如进入了一个“代码迷宫”。来来回回去寻找自己需要的那一段代码,实际上这个时候已经形成了:
只有上帝和我能看得懂的“上帝代码”了。
这显然是我们不愿见到的代码,在左耳听风专栏里有一篇《编程的本质》里讲到:
有效地分离 Logic、Control 和 Data 是写出好程序的关键所在。
那什么又是Logic,Control,Data 呢?
- Logic : 就是一般的业务代码,类似上面代码中的
dealBiz(),sendMessage()等等 - Control : 对业务逻辑的流程控制,比如遍历数据、查找数据、多线程、并发、异步等等
- Data :函数和程序之间传递的这部分信息
如果有效地将这几种代码分离,代码可读性将会大大提升。通过这种拆分,我们也降低除了自己之外的维护者阅读代码翻译业务内容的成本。通过分离,我们可以将代码写成这样:
fun executeRequest(request: Request) : String {
return Result
.of(request)
.flatMap { validateRequest(request) }
.flatMap { dealBiz(request) }
.flatMap { saveToDB(request) }
.flatMap { sendMessage(request) }
.fold(
success = { return "success" },
failure = { return it.message }
)
}
当然这里说了如何写细节的代码,那么代码架构又如何去做才可能保证可以应对这么多的变化?
一般的项目中我们把一个软件系统进行分层,这是我们目前做工程项目的一个共识,我们最初学习的分层架构就是经典的三层架构了。它自顶向下分成三层:
- 用户界面层(User Interface Layer)
- 业务逻辑层(Business Logic Layer)
- 数据访问层(Data Access Layer)
到数据访问层这块,其实很多系统已经变成了面向数据编程,最终做成了“数据库管理系统”。按照传统的三层模型,用户界面的开发依赖Service层,而Service层又依赖着DAO,DAO对应着数据库。大家相互依赖,业务逻辑一旦修改,就意味着要从DAO层开始修改,数据库也跟着被修改,而往往随着我们开发的深入,业务的模型会被不断调整,这样数据库可能就要频繁的变动。代码也开始变得复杂... ...
而在领域驱动设计中提出了另外一种四层架构,在此之前,我想先分享《实现领域驱动设计》一书讲的六边形模型。
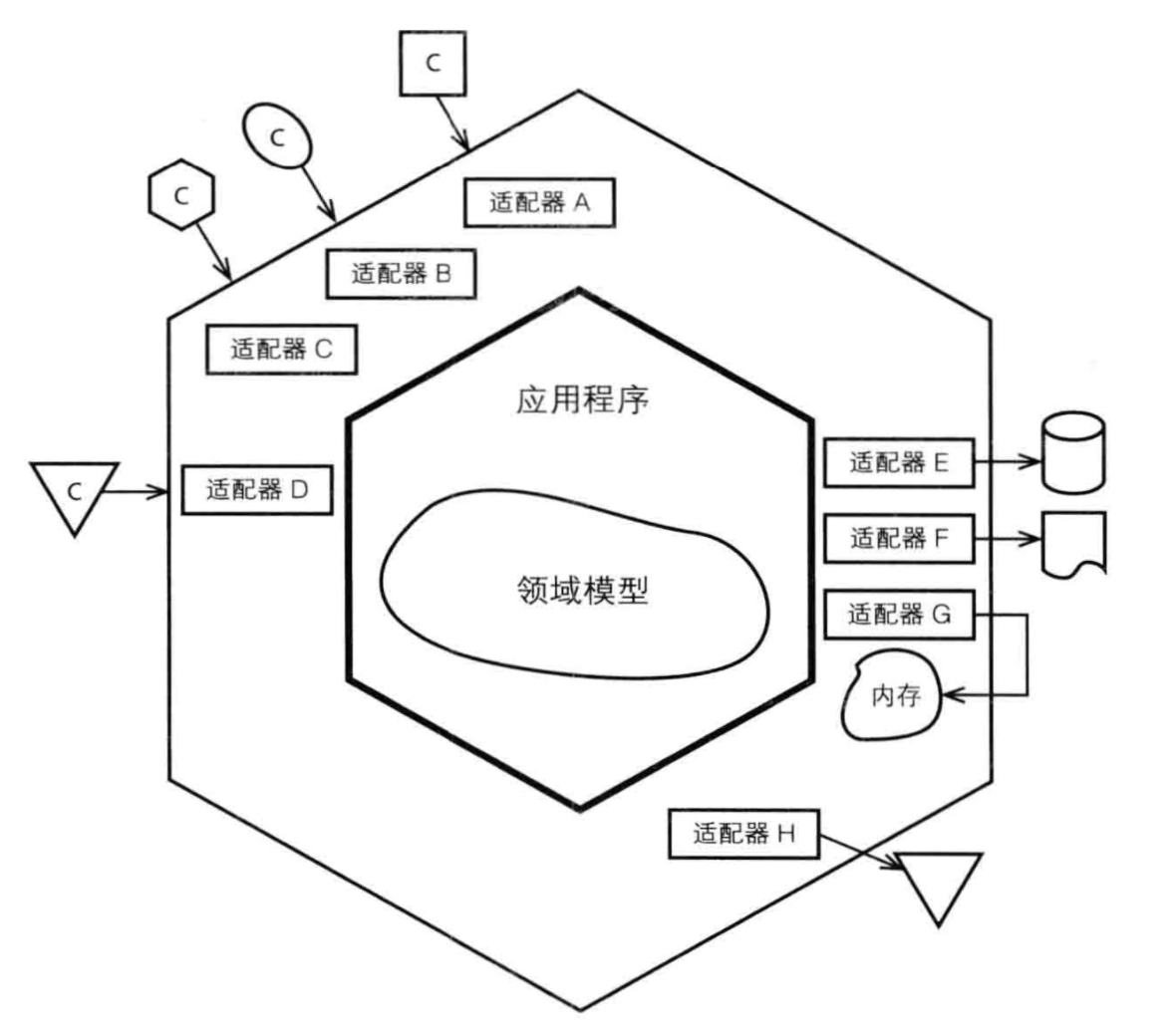
我们在设计系统的时候,往往过于关注数据库,Http接口等基础设施的设计,而忽略了我们需要关注的业务。在复杂系统中,最容易变化的也是业务形态,产品经常会要求改来改去,因为业务本身就在不断地演进,如果我们一开始就基于数据库作所有的设计,那么势必一旦遇上业务的修改,库表肯定也需要对应先进行变化。假如我们融入六边形架构,将数据库和暴露的Controller都视为是基础设施,先去关注业务的模型和代码,Class的修改比要数据库改起来要简单的多。另外一方面,也大大提高了程序的可测试性:在没有准备一堆基础设施(数据库,接口,异步通知等等)情况下,可以先测试逻辑的完整性。
另外,有时候随着业务增长有的基础设施是会需要进行替换的,采用六边形架构之后,这种更换的成本就会降低。另外如果出现需要使用Web Service的客户,我们也不必纠结于之前的HTTP接口,直接开出一套新的协议代码供客户使用,而不会纠结领域部分代码有逻辑上的缺失。
采用六边形架构之后,我们的领域模型也会更加独立,更精简,在适应新的需求时修改也会更容易。在《架构整洁之道》之中提到的“整洁架构”也与“六边形架构”大同小异。
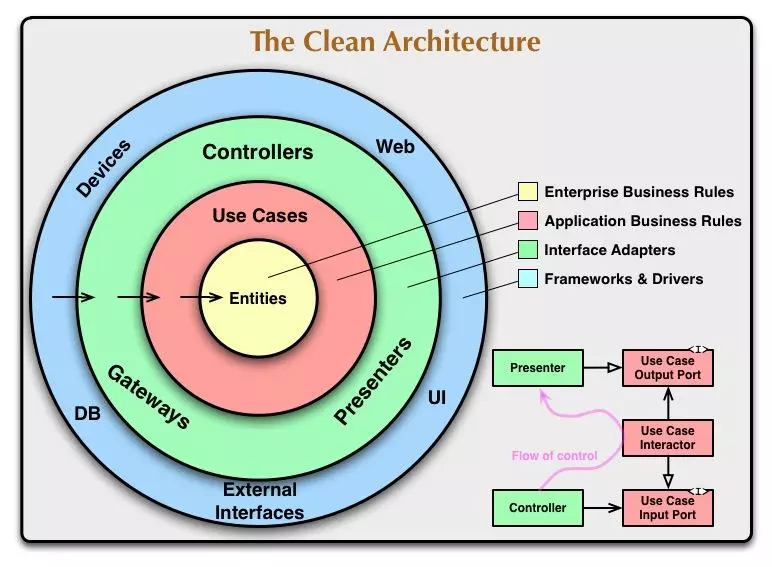
其实这两种架构也是依赖倒置原则很好的实现:
- 高层模块不应该依赖低层模块,两者都应该依赖其抽象
- 抽象不应该依赖细节
- 细节应该依赖抽象
此时再回顾原来定义的四层架构:
- 用户展示层
- 应用服务层
- 领域层
- 基础设施层
他们的依赖关系如图:
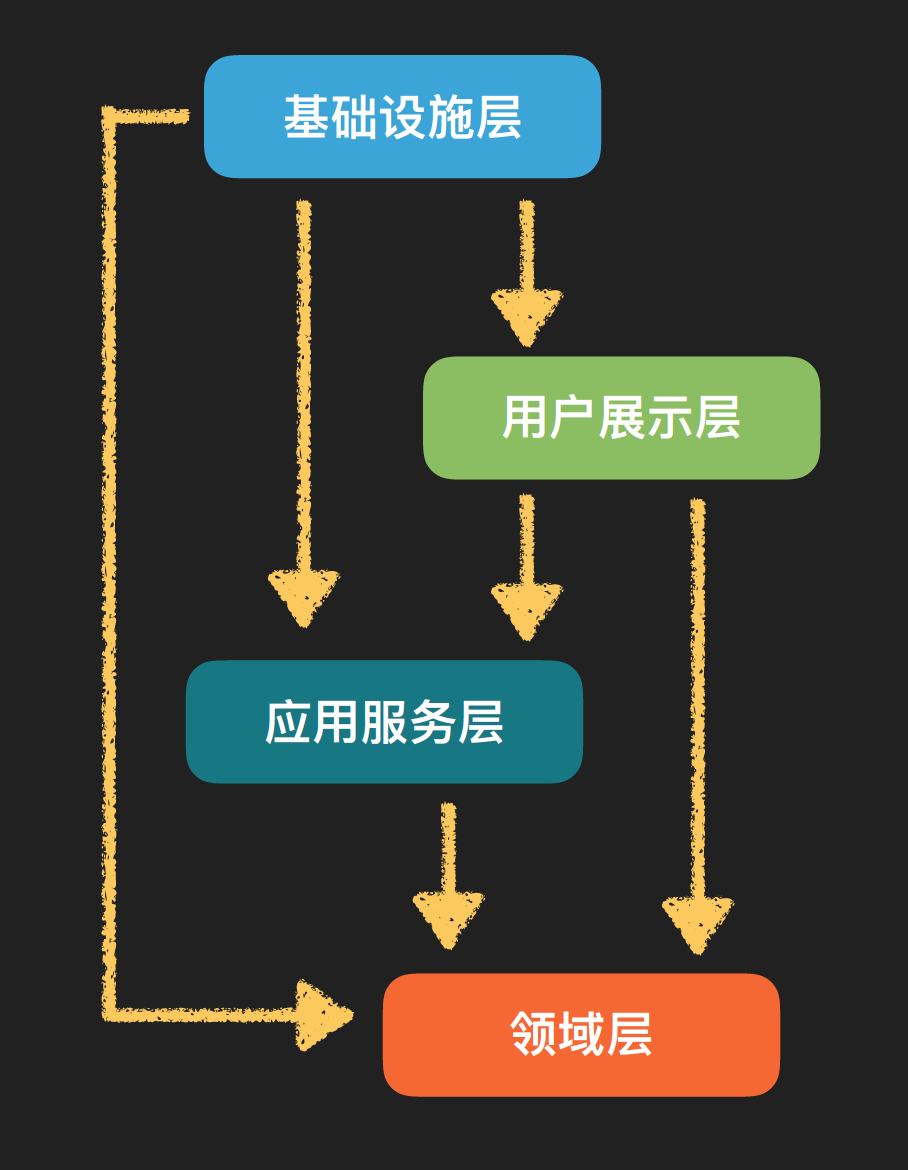
这样我们可以将业务核心代码放入领域层之中,要应对的各个场景代码放入应用服务层中。将协议转换、中间件和数据库的适配都放入基础设施层里。在应用层与Controller之间的那些VO作为用户展示层,以做出整洁架构。
当我们开始学习Java的时候,都知道Java是一门面向对象的语言,我们本可以将现实世界翻译到代码的世界之中,但实际上我们往往在项目中只会将对象定义成贫血模型,最终写成面向过程的代码。如何做才能让这个复杂的世界反应到代码里呢?
让我们再从需求说起,对于一个复杂的软件,任何一个项目的参与者(包括初创的成员),都很难靠自己就看清整个项目的全貌,我们犹如图中的盲人,大家可能最后对项目的理解都是不一致的。此时每一位参与者都犹如“盲人摸象”中的“盲人”,对需求(大象)只有片面的理解,于是乎,有的人觉得大象是水管的形状,有的人觉得大象是扇子一样的形状,有的人说大象长得跟柱子一样... ...

通过讨论,我们会对自我的认知进行一些修正,最终大致得出一个需求的全貌。
比如我们要去识别一些系统边界,在DDD的战略设计中非常强调划分界限上下文。比如我作为一个个体,在不同的场景中,我的身份、角色都不大相同。
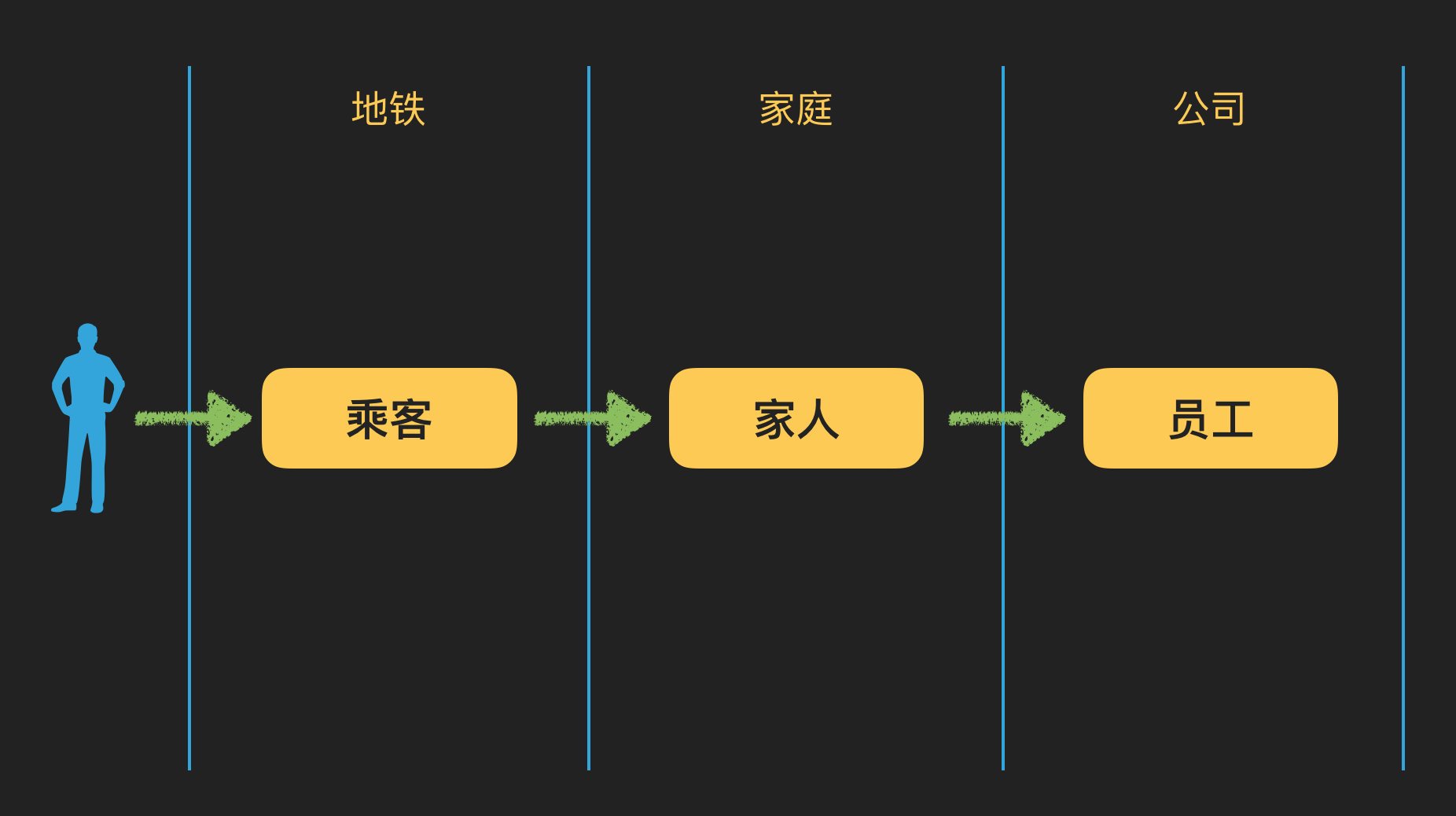
犹如在上图中,在“地铁”、“家庭”和“公司”中,我的身份是不一样的,但是我依旧是我,找出业务的场景,也就意味着我找到了系统的边界。通过分析场景识别边界来找出系统的核心领域和支撑领域,以此来最终确定系统的数量,降低系统的耦合。
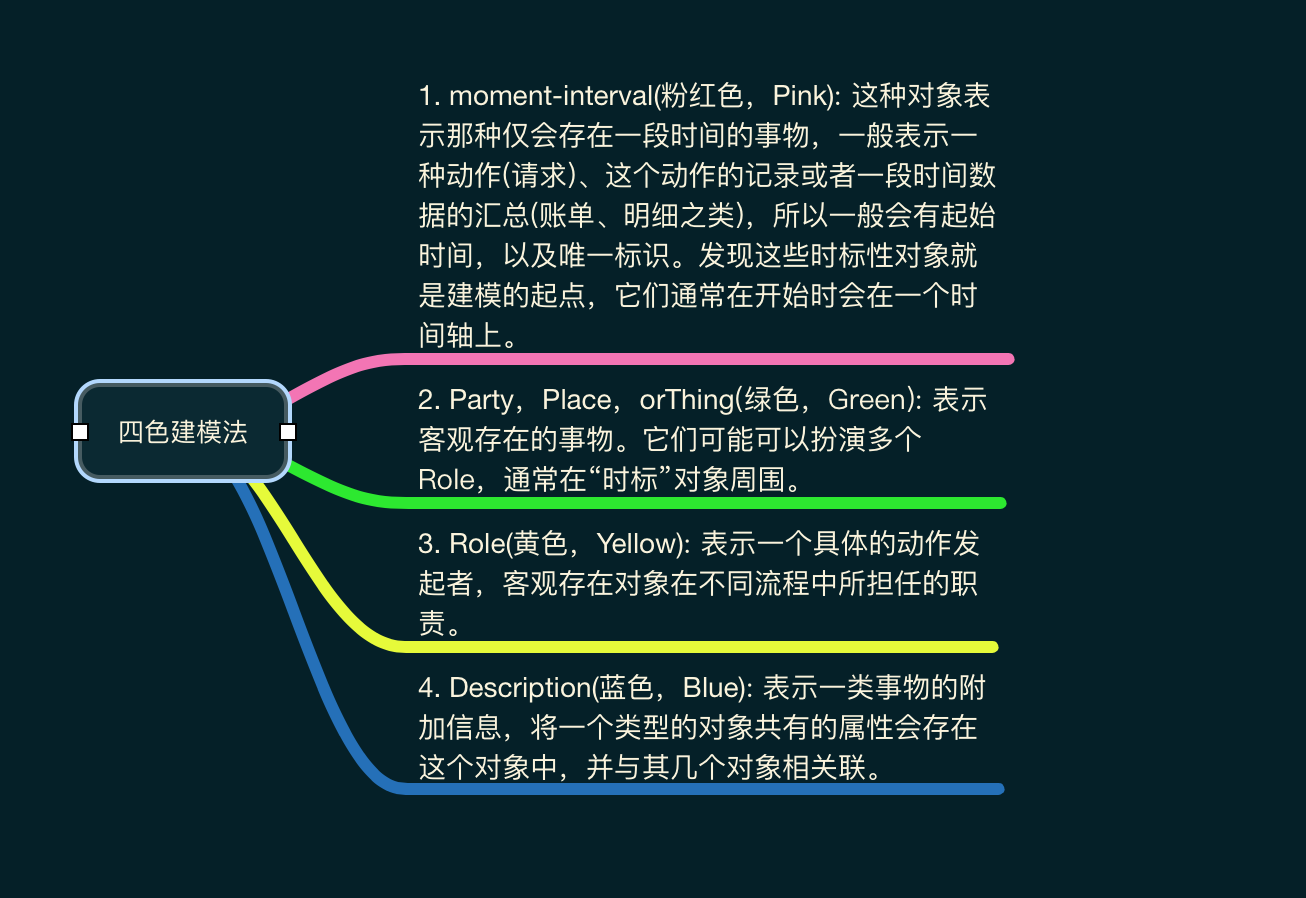
我们还可以用四色建模方法来识别出我们系统中发生的整个流程,发现究竟是谁通过什么方式触发了什么事情,最终又影响了哪些对象。
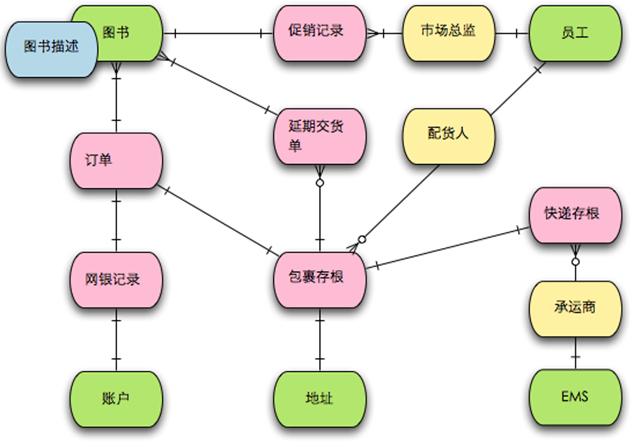
最终通过我们找出的事件,整理出一个能够让我们进行沟通的模型。在我们的模型被构建得相对完善之时,其实代码也差不多已经被构建出来了,因为这个时候再去回想面向对象的设计,我们发现模型即代码,代码即模型。
一直以来我都希望通过一些好的“工程实践”来提高团队的效率以及我们的代码质量,我想这也是思考这些架构的意义吧。我想用《架构整洁之道》中的一句话来做本文的总结:
软件架构的最终目标是,用最小的人力成本来满足构建和维护系统的需求。
正如《人月神话》里说的一样,软件工程里没有“银弹”,即使做了整洁架构也无法避免需求的变化和延期,只是希望当我们身处需求的困境中时,仍能给自己以更多的选择。
参考资料&活动 :
- 《领域驱动设计》
- 《架构整洁之道》
- 《实现领域驱动设计》
- 从三明治到六边形架构 http://insights.thoughtworkers.org/from-sandwich-to-hexagon/
- 运用四色建模法进行领域分析 https://www.infoq.cn/articles/xh-four-color-modeling
- 领域驱动战略设计实践 https://gitbook.cn/gitchat/column/5b3235082ab5224deb750e02
- 左耳听风 https://time.geekbang.org/column/48
- 领域驱动设计中国峰会DDD-China

 浙公网安备 33010602011771号
浙公网安备 33010602011771号