HashMap与HashTable的区别
HashMap与HashTable的区别
1: hashtable是线程安全的:其实现方法中都添加了synchornized关键字来确保同步,但也造成了效率的降低;
hashmap非线程安全,无特殊需求时应使用hashmap。多线程下,使用hashmap需使用Collections.synchronizedMap()获取一个线程安全的集合Map。
Map map = Collections.synchronizedMap(new HashMap());
(其原理为:Collections中定义一个实现Map接口的名为SynchronizedMap的内部类,Collections.synchronizedMap()方法帮我们在操作HashMap时自动添加了synchronized来实现线程同步,类似的其它Collections.synchronizedXX方法也是类似原理)
2: HashMap可以使用null作为key和value
其哈希函数采用: return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
通过hash获取的具体存放地址为: return h & (length-1);
ref:https://www.zhihu.com/question/20733617/answer/111577937
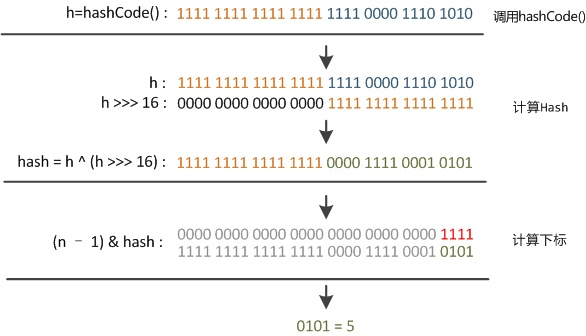
由于h是32位的int类型,h右移16位后与自身进行异或,混合原始哈希码的高位和低位,以此来加大低位的随机性。对获取的hash值与当前长度减1进行与操作获取实际存储位置,若果key为null,则其h为0,最终返回的地址也是0,存储在数组下标为0的位置。
计算出对象的存储地址后,若该地址处没有对象,则直接放入;若存在对象,则比较已存在对象的key是否与要存入对象的key相等,若相等则替换;若不等,则对象存入链表头位置,已存在对象向后移动。注意:HashMap中只能存放一个key为null的对象,value的则不限制。
HashTable不允许使用null作为key;
其哈希函数采用: int hash = key.hashCode(); 地址获取采用 int index = (hash & 0x7FFFFFFF) % tab.length;
相同点:都采用数组加链表的底层模式;
transient Entry[] table; static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; …… }
3: 接口实现不同:
HashMap是对Map接口的实现,HashTable实现了Map接口和Dictionary抽象类
4:初始容量不同
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1
话外:Hashtable与HashMap的remove,get,put,containskey等方法都是通过hash计算地址,效率较高;
但是containsValue方法比较粗暴,直接便利所有元素找到value,没有前面方法的高效。
5:补充:HashMap的初始容量为什么是 1<<4 ?
参考:博客园-YSOcean-由HashMap哈希算法引出的求余%和与运算&转换问题
初始容量设置为16,且每次容量扩增两倍,是为了满足hash算法:当 lenth = 2n 时,X % length = X & (length - 1);我们知道:求取存储位置的过程中,hashmap用与运算取代了模运算以提高效率,任意一个二进制数对 2k 取余时,我们可以将这个二进制数与(2k-1)进行按位与运算,保留的即使余数。
6:jdk1.8以后对hashmap有所改进,对于table中长度超过8的链表,转化成红黑树实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号