Kafka01--Kafka生产者使用方式
Kafka之--生产者入门
前言:
Kafka诞生至今,产生两个版本的生产者客户端:1是早期基于scala语言编写的客户端;2是随着Java用户的广泛涌入,kafka0.9版本开始退出Java版本的客户端;
一个基本生产者producer逻辑需要具备以下基本条件:
-
- 配置Producer,创建生产者实例;
- 构建待发送消息;
- 发送消息;
- 关闭生产者实例;
KafkaProducer必要参数和常用参数配置:
必要参数:
-
bootstrap.servers:待连接的broker地址;
- key.serializer和value.serializer:kafka中的消息都需要转化为字节数组byte[]进行传递,一般会使用到改参数指定key和value的序列化方式。对应的服务端的参数配置中需要有反序列化参数配置,他们是对应的。
KafkaProducer是线程安全的,可以在多个线程中共享单个KafkaProducer实例,或者进行池化,这样方便了使用。在实际使用中,可以通过Java配置方式,在项目启动时进行生产端的初始化,生成对应的实例即可。
可选参数,部分参数没有列出:
- acks :消息发送到某个partition,该参数指定需有多少个副本同步确认后,服务端才会向客户端确认消息发送成功。有三个String的值可配置:
- “1”:默认值。leader副本写入即可确认;
- “0”:生产者只管发送,不需要服务端确认;
- "-1"或者"all":ISR集合中的所有副本确认之后,才会确认;(若ISR中只有leader副本,那仍然无法百分百可靠)
- max.request.size :客户端一条消息容量的最大值,默认为1M。
- retries ,retry.backoff.ms :生产者发送异常时的重试次数和两次重试间的时间间隔。
- max.in.flight.request.per.connection :默认值为5,限制客户端与Node之间最多缓存的请求数量。
- Kafka只能保证一个partition中的消息是有序的。当缓存数>1,且配置重试机制后,有可能出现先发送的消息异常,后发送消息成功,然后先发送的消息重试,这样两条消息的顺序就出现了错乱。若要保证顺序,建议将connection置为1.
- linger.ms :指定生产者发送ProducerBatch之前等待更多消息的写入,默认为0。当batch满了或者linger时间到了,才会 发送。
- request.time.out :生产者发送消息后等待响应的最长时间。
KafkaProducer发送消息:
kafka消息的发送需要通过构建ProducerRecoder对象来实现,该类的属性有:
private final String topic; private final Integer partition; private final Headers headers; private final K key; private final V value; private final Long timestamp;
其中,最简的一种使用只需要指定topic和消息体即可。`ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!");
Kafka有三种发送消息的模式:
-
- 发送即忘:KafkaProducer只管发送,不管有没有发送成功。
- 同步模式:KafkaProducer发送后阻塞,一致等到Server端返回消息或者抛出异常;(Server端一般有多个副本,多副本的消息确认机制等到服务端介绍时再说);
- 同步模式下,可以根据返回的数据进行进一步的业务处理,比如返回的partition,offset等;
异步模式:通过CallBack回调函数,对服务端响应后的事件进一步处理,;
示例代码如下:


1 public static void main(String[] args) { 2 Properties properties = new Properties(); 3 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); 4 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); 5 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); 6 KafkaProducer<String, String> producer = new KafkaProducer<>(properties); 7 ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!"); 8 try { 9 /**①:发送不管*/ 10 producer.send(record); 11 /**②:同步发送:通过调用get方法,进行阻塞,可以通过Future获取发送结果,进行业务逻辑处理*/ 12 producer.send(record).get();//同步发送 13 Future<RecordMetadata> future = producer.send(record); 14 RecordMetadata metadata = future.get(); 15 //分区为:0偏移量为:240048 16 System.out.println("分区为:" + metadata.partition() + "偏移量为:" + metadata.offset()); 17 /**③:异步发送:KafkaProducer将发送请求暂存,当服务端response响应后,从中取出对应的发送请求,然后调用回调函数*/ 18 producer.send(record, new Callback() { 19 @Override 20 public void onCompletion(RecordMetadata metadata, Exception exception) { 21 if (exception != null){ 22 exception.printStackTrace(); 23 }else { 24 //分区为:0偏移量为:240048 25 System.out.println("分区为:" + metadata.partition() + "偏移量为:" + metadata.offset()); 26 } 27 } 28 }); 29 } catch (Exception e) { 30 e.printStackTrace(); 31 } 32 producer.close(); 33 }
KafkaProducer消息序列化:
生产端和消费端的序列化方式要一一对应,一般而言,会将消息进行json话之后发送,因此一般指定为kafka自带的StringSerializer类即可;
KafkaProducer分区器:
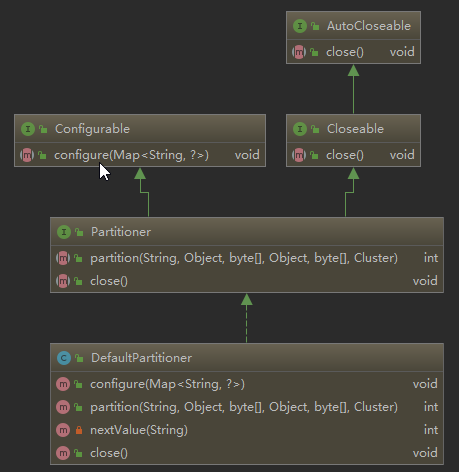
1、生产端将消息发送到broker时,可能要经过拦截器,序列化器,分区器等一系列节点进行处理。默认情况下,Kafka中的消息在发送前,会经过 DefaultPartation 默认分区器进行处理,其从父类实现了两个方法, close(...) 主要进行分区器关闭之后的资源回收。 partition(...) 主要就进行分区的分配,返回int值。configure(...)方法继承自Configurable接口,可以用来获取配置信息和初始化数据,这里只是空实现。
* @param key The key to partition on (or null if no key) key的值 * @param keyBytes serialized key to partition on (or null if no key) key序列化后的值 * @param value The value to partition on or null value值,待发送内容值 * @param valueBytes serialized value to partition on or null value值序列化后的值 * @param cluster The current cluster metadata 集群的元数据信息,包含一些分区数量等信息; */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster
由上面的ProducerRecoder的属性可知,可以在发送消息时,指定消息发送到哪个分区。若采用默认的分区器 DefaultPartation则会包含以下两种情况:
- key为null,消息以轮询的方式发送消息到 topic 中的所有可用分区;
- key不为null,对key进行hash,通过hash值计算分区号,相同key的消息会被发送到同一个分区。
采用默认分区器时,不改变分区的数量,那么key与分区号的映射关系时对应的。若增加一个分区,那么相同的key在增加分区后,就可能不在同一个分区中了。
2、若采用自定义分区器,完全可以根据业务需要,进行自定义分配规则,只需继承父类 Partitioner ,并在生产端配置中加入分区器配置即可,代码示例如下:
//配置中指定分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DemoPartitioner.class); ... //因为用了字符串序列化方式,消息体中指定key值为字符串“1”。(这里是根据key值进行分区分配的) ProducerRecord<String, String> record = new ProducerRecord(topic,"1", "hello, Kafka!");
自定义分区器的示例代码如下:
public class DemoPartitioner implements Partitioner { //原子类,线程安全 private final AtomicInteger counter = new AtomicInteger(0); @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { //获取可用分区 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); // if (null == keyBytes) { // return counter.getAndIncrement() % numPartitions; // } else // return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; if (key.toString() == "0"){ return 0; }else return 1; } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }
通过send之后的Future,可以观察到消息确实发送到了不同的分区中。
KafkaProducer拦截器:
拦截器分生产者拦截器和消费者拦截器(后续介绍);
生产者拦截器的作用时间点:
-
- 消息序列化和计算分区之前,调用生产者拦截器的 onSend() 方法进行个性化操作;
- 消息被服务端应答,或者发送失败时,调用 onAcknowledgement() 方法进行处理,该操作优先于回调函数。

Kafka中提供了父接口 ProducerInterceptor 方便用户进行自定义的拦截器实现,比如可以在自定义的拦截器中对kafka消息的发送数量进行统计:
注:通过onAcknowledgement()统计发送成功与失败数量,而不是 onSend()方法;
public class HawkKafkaProducerInterceptor implements ProducerInterceptor<String, String> { @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) { return producerRecord; } @Override public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) { if (e == null) { /// success Cat.logEvent(HawkConstants.KAFKA_PRODUCER_EVENT_TYPE, recordMetadata.topic()); } else { /// failed Cat.logEvent(HawkConstants.KAFKA_PRODUCER_EVENT_TYPE, recordMetadata.topic(), HawkConstants.EVENT_FAILED_STATUS, null); } } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }
然后需要在配置文件中加入该拦截器:
// 只配置一个拦截器 props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, HawkKafkaProducerInterceptor.class.getName()); // 若想配置多个拦截器,形成拦截链,则配置顺序即为拦截顺序,以“,”隔开(注意,若拦截器2完全依赖拦截器1的结果,则不利于稳定性) props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "Intercepter01"+","+"Intercepter02);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号