常见内置函数
-
三元表达式(简化代码)
-
各种生成式(简化代码)
-
匿名函数(简化代码)
-
常见重要内置函数
-
常见内置函数
一、三元表达式
''''''
使用场景:二选与的时候 推荐使用三元式表达式
''''''
# 例题1 编写一个求两个数大小的函数
# def index(a,b): 用三元表达式可写为:
# if a > b: res =a if a>b else b
# return a print(res)
# else:
# return b
# 例题2 如果用户名是jason则打印管理员 否则打印DSB
# username =input('请输入您的用户名>>>>:').strip()
# if username =='jason':
# print('管理员') 例2用三元表达式可写为:
# else: res ='管理员' if username ='jason' else 'DSB'
# print('DSB') print(res)
# 从而引出了三元表达式的定义
值1 if 条件 else 值2
条件如果成立则使用用1(也就是if前面的数据)
条件如果不成立则使用值2(else后面的数据)
另外注意的是:三元表达式只适用于二选一的情况 最好不要嵌套使用(避免语法不简洁)
比如:res='下午' if 1 == 1 else (2 if 2==3 else '上午') # 不推荐使用
“”“ 并不是代码写的最少和功能最多就越好 还有考虑写的代码需要简洁易读
#例题3 写一个电影系统 需要决定电影是否收费 可以用于一些简单那的逻辑判断
is_choice =input('是否收费(y/n)').strip()
is_free ='收费' is_choice == 'y' else '免费'
print(is_free)
# 需要补充的是:针对分支结构 也有简化写法版本
'''子代码块都只有简单的一行情况下 也可以简写成一行
没有三元表达式简单 但是也有人写 我们也要看得懂'''
eg:
name ='jason'
if name =='jason':print(name)
else:print('去你妹的')
二、各种生成式
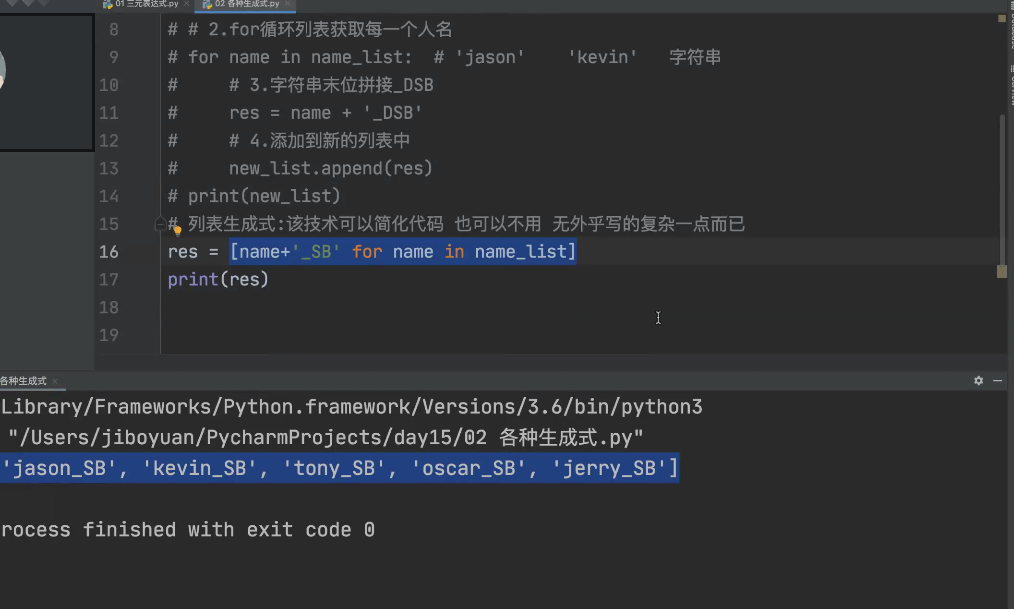
# 列表生成式:该技术可以简化代码 也可以不用 也可以用,不用的话可能会更复杂一点
# 列表生成式 写法:
# res =[name+ '_sb' for name in name_list if name =='jason']
print(res) # jason_SB
res = [name+'_SB' for name in name_list if name != 'jason']
print(res) # kevin_SB,tony_sb,oscar_SB,jerry_SB
列表生成式中值允许出现for和if 但是不能出现else 因为if和for都可以与else使用 避免产生歧义
# 1.列表生成式
# 例题1
# name_list =['jason','kevin','tony','oscar','jerry']
#'''''' 我们的需求:将列表所有的人名后面加上_DSB后缀
# 传统的解决方法:
# 1.先创建一个空的列表用于存储修改之后的数据
# new_list = []
# # 2.for循环列表获取每一个人名
# for name in name_list: # 'jason' 'kevin' 都是一些字符串
# # 3.将字符串末尾拼接成_DSB
# res =name +'_DSB'
# # 4.添加到新的列表中
# new_list.append(res)
# print(new_list)
# 列表生成式:该技术可以简化代码 也可以不用 也可以用,不用的话可能会更复杂一点
# 列表生成式 写法:
# # res =[name+ '_sb' for name in name_list if name =='jason']
# print(res) # jason_SB
# res = [name+'_SB' for name in name_list if name != 'jason']
# print(res) # kevin_SB,tony_sb,oscar_SB,jerry_SB
# 列表生成式中值允许出现for和if 但是不能出现else 因为if和for都可以与else使用 避免产生歧义
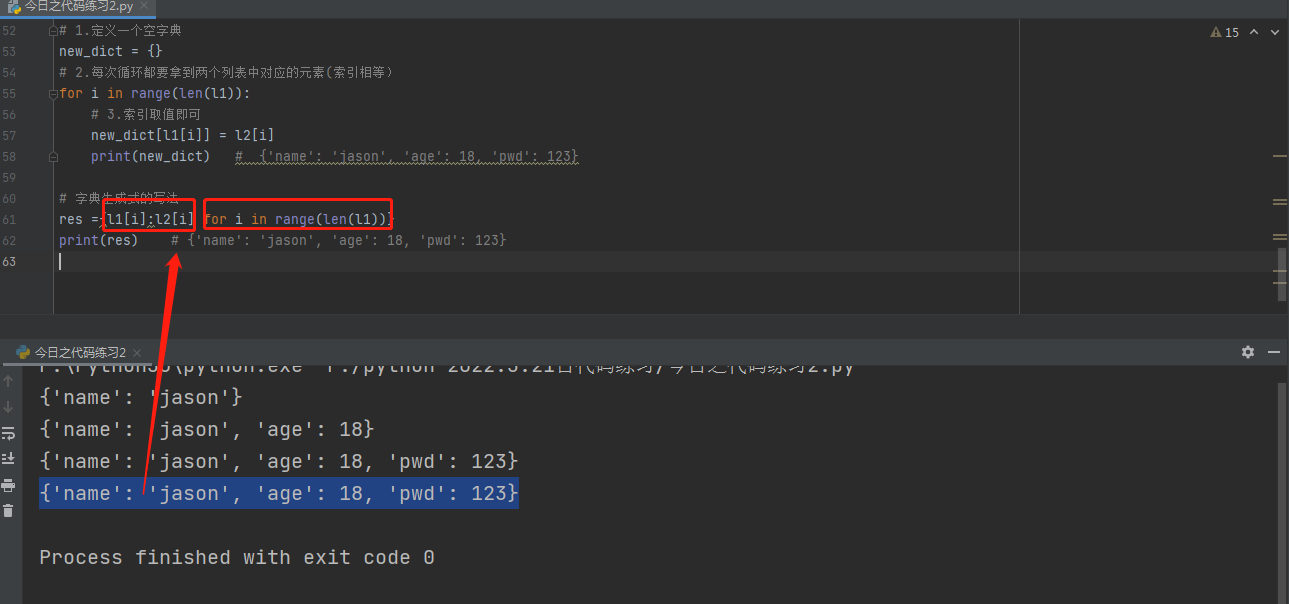
# 2.字典生成式
# l1 =['name','age','pwd']
# l2 =['jason',18,123]
# # 需求:将上述两个列表分别制作成字典的键值
# # 1.定义一个空字典
# new_dict = {}
# # 2.每次循环都要拿到两个列表中对应的元素(索引相等)
# for i in range(len(l1)):
# # 3.索引取值即可
# new_dict[l1[i]] = l2[i]
# print(new_dict) # {'name': 'jason', 'age': 18, 'pwd': 123}
#
# # 字典生成式的写法
# res ={l1[i]:l2[i] for i in range(len(l1))}
# print(res) # {'name': 'jason', 'age': 18, 'pwd': 123}
# res ={l1[i]:l2[i] for i in range(len(l1)) if i == 1}
# print(res) # {'age': 18}
# 3.集合生成式
res = {i for i in range(10)}
print(res,type(res)) # {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
res = {i for i in range(10) if i != 2}
print(res,type(res)) # {0, 1, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
三、匿名函数
匿名函数的定义:没有函数名》》》没有函数名的函数是如何调用呢》》》》》需要结合其他函数一起使用
# 定义匿名函数
lambda x:x+2
lambda 形参:返回值
用普通的函数来表示
def index(x):
return x+2
# print(lambda x:x+2) 用匿名函数写法
# max:统计最大值
l1 =[11,32,41,22,13,45,66,54,78,98,34,43,99,40]
print(max(l1)) # 99 直接获取数据集中最大的元素值
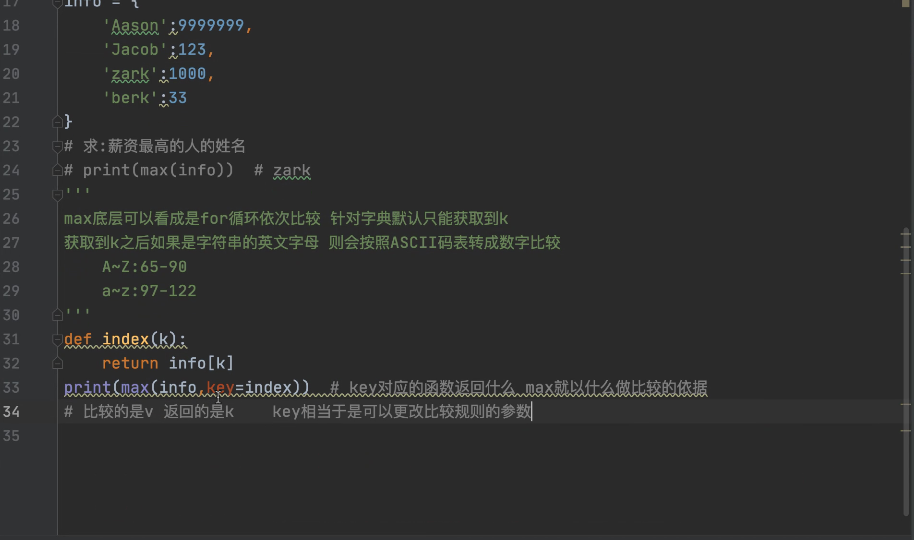
user ={
'jason':3000,
'Mary':1223,
'zark':1000,
'benk':1222
}
# 求薪资最高的人的姓名
# print(max(user)) # zark
# """"这样只能得到key值""" max 底层可以看成是for循环依次比较 针对字典默认只能获取到k值
# 获取到k值之后如果是字符串的英文字母 则会按照ASCII码表转成数字比较
# A-Z:65-90
# a-z:97-122 这样是不行的 所以只能换一种
def index (k):
return user[k]
print(max(user,key=index)) # jason # key对应的函数返回什么 max就以什么做比较的依据
# 比较的是v 返回的是k key相当于可以更改比较规则的参数
# 为了便于上述代码的简写 因为函数功能单一 所以可以简写
print(max(user,key=lambda key:user[key] )) # jason
四、常见重要的内置函数
# 1.内置函数之 map映射
l1 =[11,22,33,44,55]
# 需求:元素全部自增10
#方式1:列表生成式
#res =[ i+10 for i in l1 ]
# print(res) [21, 32, 43, 54, 65]
# 方式2:内置函数
# def index(n):
# return n +10
# res =map(index,l1)
# # print(res) # 迭代器(节省空间的 目前不用考虑)
# print(list(res)) # [21, 32, 43, 54, 65]
# 因为也是功能单一 也是可以简写的
# res =map(lambda x:x+10,l1)
# print(list(res)) # [21, 32, 43, 54, 65]
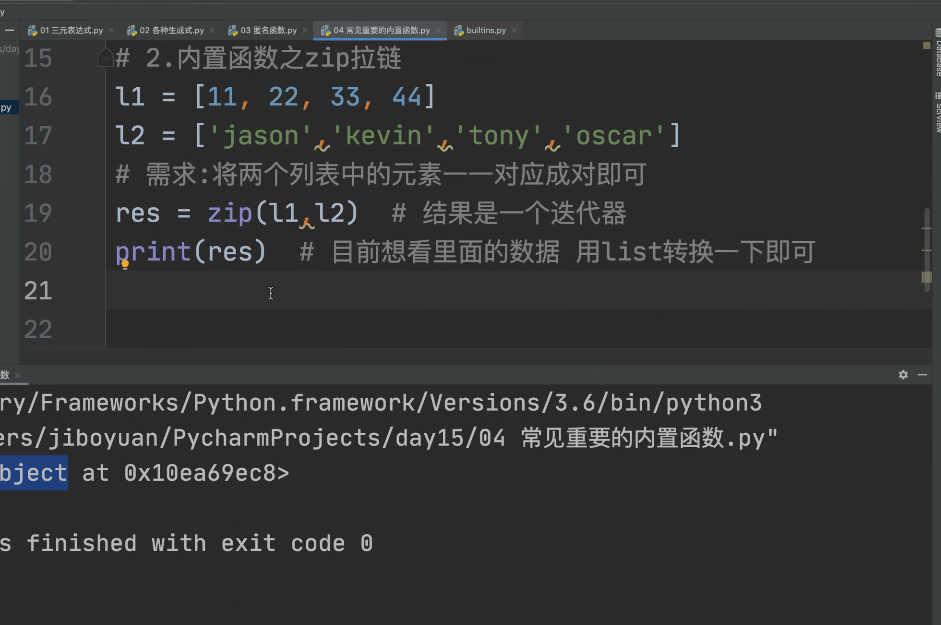
# 2.内置函数之zip拉链
# l1 =[11,22,33,44]
# l2 =['jason','kevin','kevin','oscar']
# # 需求:将两个列表中的元素一一对应成对即可
# res =zip(l1,l2) # 结果也是一个迭代器
# print(list(res)) # [(11, 'jason'), (22, 'kevin'), (33, 'kevin'), (44, 'oscar')]
# # zip可以主动整合多个数据集
#
# # 2.拉链也可以整合多个数据集
# l1 =[11,22,33,44]
# l2 =['jason','kevin','kevin','oscar']
# l3 =[1,2,3,4]
# l4 =[55,66,77,88]
# res =zip(l1,l2,l3,l4)
# print(list(res)) # [(11, 'jason', 1, 55), (22, 'kevin', 2, 66), (33, 'kevin', 3, 77), (44, 'oscar', 4, 88)]
#
# # 3.zip也可以整合多个数据集之间个数不一致时 需要参考那个最短的数据集
# l1 =[11,22,33,44]
# l2 =['jason',]
# l3 =[1,2,3,4]
# res = zip(l1,l2,l3)
# print(list(res)) # [(11, 'jason', 1)]
#
# # 内置函数之filter过滤(筛选)
# l1 =[11,22,33,44,55,66]
# # 需求:筛选出大于30的元素
# # 方式一:列表生成式
# res =[i for i in l1 if i>30]
# print(res) # [33, 44, 55, 66]
# # 方式二:内置函数
# def index(x):
# return x >30
# res =filter(index,l1)
# print(list(res)) # [33, 44, 55, 66]
# # 因为涉及到功能单一 也可以使用匿名函数来表示
# res =filter(lambda x:x>30, l1)
# print(list(res)) # [33, 44, 55, 66]
# 内置函数之reduce归总
# 一般不会单独使用 需要在某个模块下面的子函数
from functools import reduce
l1 =[11,22,44]
# 需求:将列表中所有元素相加
def index(x,y):
return x+y
res =reduce(index,l1)
print(res) # 77
# 因为涉及的功能单一 也可以使用匿名函数来简写
res =reduce(lambda x,y:x+y,l1)
print(res) # 77
res =reduce(lambda x,y:x+y,l1,100)
print(res) # 177
五、常见内置函数
# 1.abs() 获取绝对值
print(abs(-123)) # 123
print(abs(123)) # 123
# 2.all()与any()
l1 =[0,0,0,1,True]
print(all(l1)) # False 数据集中必须所有的元素对应的布尔值为True返回的结果才是True
print(any(l1)) # True 数据集中其中元素只要有一个True返回的结果就是True
# 3.bin() oct() hex() 产生对应的进制数
print(bin(100)) 将100转化成二进制数
print(oct(100)) 将100转化成八进制数
print(hex(100)) 将100转化成十六进制数
# 4.bytes() 类型转换
其功能相当于encode 用来编码
print(bytes(s,'utf8'))
针对编码解码 可以使用关键字encode与decode 也可以使用bytes和str
# 5.callable() 判断当前对象是否可以加括号调用
name ='jason'
def index():pass
print(callable(name)) # False 变量名不能加括号调用
print(callable(index)) # True 函数名可以加括号调用
6.chr()、ord() 字符与数字的对应转换
print(chr(65)) # A 根据数字转字符 参考ASCII码
print(ord('A')) # 65 根据字符转数字 参考ASCII码
7.dir() 返回数据类型可以调用的内置方法(查看对象内部可调用的属性)
print(dir(123))
print(dir('jason'))
8.divmod()
可以使用在网站的分页制作上
问题:
总共250条数据 每页展示25条 需要多少页 10页
总共251条数据 每页展示25条 需要多少页 11页
总共249条数据 每页展示25条 需要多少页 10页
''''''
print(divmod(250,25)) # (10,0) 第一个参数是整数部分 第二个是余数部分
print(divmod(251,25)) # (10,1)
print(divmod(249,25)) # (9,24)
用函数来定义:
def get_page_num(total_num,page_num):# 后面django分页器使用
more,others =divmod(total_num,page_num)
if others:
more += 1
print('需要%s页'%more)
get_page_num(1000,30)
# 9.enumerate() 枚举
# name_list = ['jason', 'kevin', 'oscar', 'tony']
# for name in name_list:
# print(name)
# for i,j in enumerate(name_list):
# print(i,j) # i类似于是计数 默认从0开始
# for i,j in enumerate(name_list,start=1):
# print(i,j) # 还可以控制起始位置
# 10.eval() exec() 识别字符串中的python代码 使用频率很低
# print('print("有点饿了")')
# eval('print("有点饿了111")')
# exec('print("有点饿了222")')
res = """
for i in range(10):
print(i)
"""
# eval(res) 只能识别简单逻辑的python代码
# exec(res) 能够识别具有与一定逻辑的pytho