字符编码的基础知识
-
字符编码的实际应用
-
文件操作简介
-
文件的读写模式
-
文件的操作模式
-
文件的操作方法
-
文件补充说明
-
利用文件充当数据库完成用户注册登录
...........
今日内容详细
一 、字符编码的实际应用
# 1.编码与解码
编码:将人类能够读懂的字符编码成计算机能够直接读懂的字符 表示方法:encode
解码:将计算机中能够直接读懂的字符解码成人类能够读懂的字符 表示方法:decode
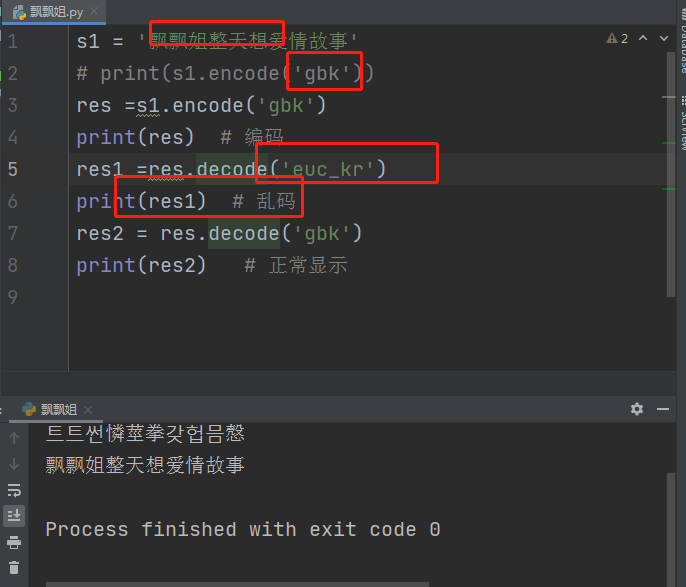
eg:s1 = '飘飘姐整天想爱情故事'
编码:print(s1.encode('gbk'))
结果:字符串前面如果加了字母b 表示的是该数据类型为bytes类型
bytes类型可以看成是二进制
解码:user =b'\xca\xc2\xd2\xd1\xd6\xc1\xb4\xcb \xba\xce\xb2\xbb\xd2\xbb\xb2\xab'
print(user.decode('gbk'))
为了基于网络传输数据 数据都必须是二进制格式 就必须涉及到编码与解码
# 2.如何解决数据乱码的问题
采用数据当初以什么编码编写的就要以什么编码翻译破解即可(意思就是需要采用同一个编译本)
s1 = '飘飘姐整天想爱情故事'
# print(s1.encode('gbk'))
res =s1.encode('gbk')
print(res) # 编码正常显示
res1 =res.decode('euc_kr')
print(res1) # 乱码
res2 = res.decode('gbk')
print(res2) # 正常显示
# 3.python解释器层面
python2解释器默认的编码是ASCII码
文件头:必须写在文件的最上方告诉解释器使用指定的编码 形式:coding:utf8或-*- coding:utf8 -*-(美化写法)
字符前缀:在使用python2解释器的环境下定义‘字符串’习惯在前面加‘u’ eg:name = u'你好啊'
在python3解释器上默认的是utf8
![]()
二、文件操作简介
# 文件的定义:操作系统暴露给用户直接可以操作硬盘的快捷方式
# 代码操作文件的流程
1、打开文件、创建文件(open)
2、编辑文件内容
3、保存文件内容
4、关闭文件(close)
# 基本语法结构
结构1(了解即可)
f1 = open() # 打开文件
f1.close() # 关闭文件
结构2(条件使用):
with open() as f:
pass(为了符合语法不会起功能的词)
# 1.使用关键字打开文件
以后写路径是为了防止特殊符号的特定含义 为取消直接在前面加r
eg:res = open(r'a.txt','r',encoding='utf8')
""""""
open(文件的路径,文件的操作模式,文件的编码)
1.文件的路径是必须要写的
2.文件的操作模式、文件的编码有时候可以不用写
''''''
# print(res.read()) # 读取文件内容
''''''上述操作open完最后都需要执行close 而close这一行很容易被遗忘''''''
# with上下文管理
with open(r'a.txt','r',encoding='utf8') as f:
data = f.read()
print(data)
其中with包含了打开文件和用完后自带关闭功能
![]()
三、文件的读写模式
r read 表示只读模式 只能读不能写
w write 表示只写模式 只能写不能读
a append 表示追加模式 在文件末尾添加内容
# r模式分为路径存在与不存在
路径存在时:正常打开文件并等待内容读取
with open(r'a.txt','r',encoding ='utf8') as f1:
print(f1.read) # 一次性读取文件内所有内容
f1.write('python是最牛逼的语言!!') # 报错
路径不存在时:会直接报错
with open(r'b.txt','r',encoding='utf8') as f1:
pass
# w模式
路径存在:会先清空文件内内容 之后再写入数据
with open(r'a.txt','w',encoding='utf8') as f1:
f1.write('你们是大帅比\n') # 写入内容 如果需要换行需要在后后面添加\n
换行 最早时候是:\r\n 源自于打印机的原理
后为了节省空间支持一个字符 根据操作系统的不同可能有所区别,后只有这个\n、\r
路径不存在:自动会创建文件
随便添加一个新的文件后然后在使用时会出现自动创建文件
# a模式
路径存在时:不会清空文件内容 而是在文件末尾等待新内容的添加
with open(r'a.txt','a',encoding='utf8') as f1:
f1.write('哈哈哈哈')
print(f1.read())
路径不存在时:会自动创建文件
with open(r'c.txt','a',encoding='utf8') as f1:
pass
随意添加一个新的不存在文件时,计算机会自动创建文件
![]()
四、文件的操作模式
t模式:文本模式 表示的是默认的模式
r rt(txt)
w wt(txt)
a at(txt)
1.该模式下只能操作文本文件
2.该模式下必须要指定encoding参数
3.该模式读写都是以字符串作为最小单位
b模式:采用的是二进制模式 可以操作任意类型的文件
rb 不能省略b,否则又会回到t模式
wb 不能省略b,否则又会回到t模式
ab 不能省略b,否则又会回到t模式
1.该操作模式下可以操作任意数据类型的文件(因为计算最底层只会使用的都是二进制)
2.该模式下不需要指定encoding参数
3.该模式读写都是以字节bytes类型为最小单位![]()
五、文件内置方法
read() # 一次性读取完文件内容
1.执行完之后光标在文件末尾 继续读取则没有内容
2.当文件内容特别大的时候 容易造成内存溢出
readline() # 一次只读取一行内容
readlines() # 结果是一个列表 里面的各个元素是文件的一行行内容
readable() # 判断当前文件是否可读
支持for循环 # 一行行读取文件内容(推荐使用) 内存中同一时刻只会有一行内容 避免了内存不够用的情况
write() # 写入文件内容(字符串或者是bytes)
waitelines() # 可以将列表中多个元素写入文件
writable() # 判断文件是否可写
flush() # 相当于主动按了ctrl+s(保存) -




 浙公网安备 33010602011771号
浙公网安备 33010602011771号