
HDFS(second)
写在前面
其实之前学这个东西,就觉得能挣钱,自己不知道学啥然后就随便学,没有抓手,无处赋能,哈哈哈哈哈。大数据学习路线(在网上看大佬说的)elk起手,hadoop,zookeeper,Hive/Hbase,spark,flink,最后到云计算,人工智能,学到这一步就技术大牛了,就随便挣钱,年薪百万起步。
coding&环境变量配置
昨天没有服务器去搭建hadoop集群,故今天斥巨资买了三个服务器,来搭建Hadoop
环境配置
这个东西是大数据入门的东西比较重要
整个过程可以简单总结为以下几点
1.安装mysql,jdk,hadoop,Hive,Hbase,spark,后面三种未安装
- jdk安装
rz //选择对应JDK目录和hadoop和mysql目录
tar -zvf jdk
tar -zvf hadoop
tar -zvf mysql
vim /etc/profile
配置文件即可
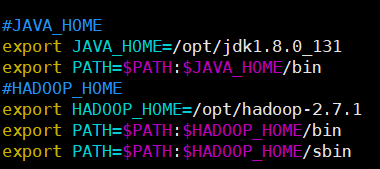
hadoop 配置文件修改
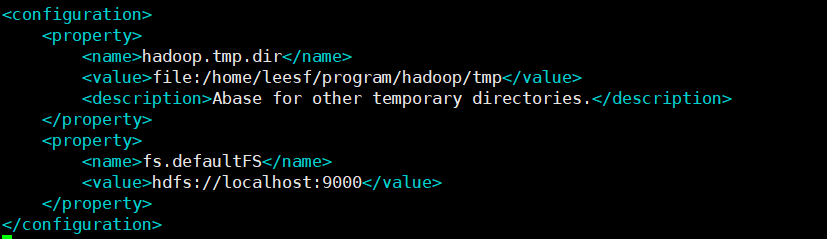
大致就是这样配置一个对应的环境
开启hadoop
开启hadoop的一个命令
访问对应的地址:
http://49.234.5.209:50070/
下来就是对应的命令写
命令其实巨简单,学会linux就会使用这个东西,,在前面添加一个
hadoop fs -【对应的指令】就OK
用Java操作
下载HDFS_client

 浙公网安备 33010602011771号
浙公网安备 33010602011771号