
在浏览器中输入URL并回车后都发生了什么?
1.解析URL
________________________________________________________________________
关于URL:
URL(Universal Resource Locator):统一资源定位符。俗称网页地址或者网址。
URL用来表示某个资源的地址。(通过俗称就能看出来)
URL主要由以下几个部分组成:
a.传输协议
b.服务器
c.域名
d.端口
e.虚拟目录
f.文件名
g.锚
h.参数
也就是说,通常一个URL是像下面这样

连起来就是:http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
上面的链接有几个要注意的地方:“;” 和“/”的使用,80端口默认不显示,“?” 到“#”之间跟着参数,多个参数使用“&”连接,“#”后面跟着锚。
___________________________________________________________________________________________________________________________________________________________________
现在来讨论URL解析,当在浏览器中输入URL后,浏览器首先对拿到的URL进行识别,抽取出域名字段。
2. DNS解析
DNS解析(域名解析),DNS实际上是一个域名和IP对应的数据库。
IP地址往都难以记住,但机器间互相只认IP地址,于是人们发明了域名,让域名与IP地址之间一一对应,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,整个过程是自动进行的。
可以在浏览器中输入IP地址浏览网站,也可以输入域名查询网站,虽然得出的内容是一样的但是调用的过程不一样,输入IP地址是直接从主机上调用内容,输入域名是通过域名解析服务器指向对应的主机的IP地址,再从主机调用网站的内容。
在进行DNS解析时,会经历以下步骤:
查询浏览器缓存(浏览器会缓存之前拿到的DNS 2-30分钟时间),如果没有找到,
检查系统缓存,检查hosts文件,这个文件保存了一些以前访问过的网站的域名和IP的数据。它就像是一个本地的数据库。如果找到就可以直接获取目标主机的IP地址了。没有找到的话,需要
检查路由器缓存,路由器有自己的DNS缓存,可能就包括了这在查询的内容;如果没有,要
查询ISP DNS 缓存:ISP服务商DNS缓存(本地服务器缓存)那里可能有相关的内容,如果还不行的话,需要,
递归查询:从根域名服务器到顶级域名服务器再到极限域名服务器依次搜索哦对应目标域名的IP。
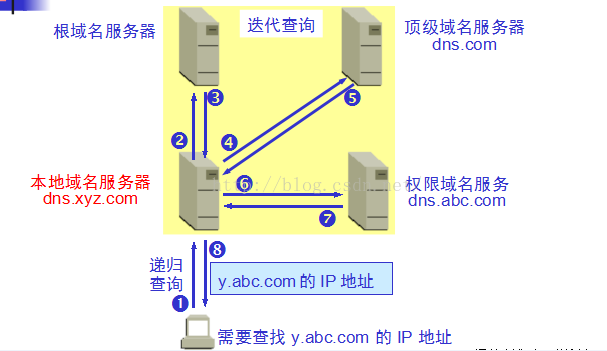
通过以上的查找,就可以获取到域名对应的IP了。接下来就是向该IP地址定位的HTTP服务器发起TCP连接。
3. 浏览器与网站建立TCP连接(三次握手)
第一次握手:客户端向服务器端发送请求(SYN=1) 等待服务器确认;
第二次握手:服务器收到请求并确认,回复一个指令(SYN=1,ACK=1);
第三次握手:客户端收到服务器的回复指令并返回确认(ACK=1)。
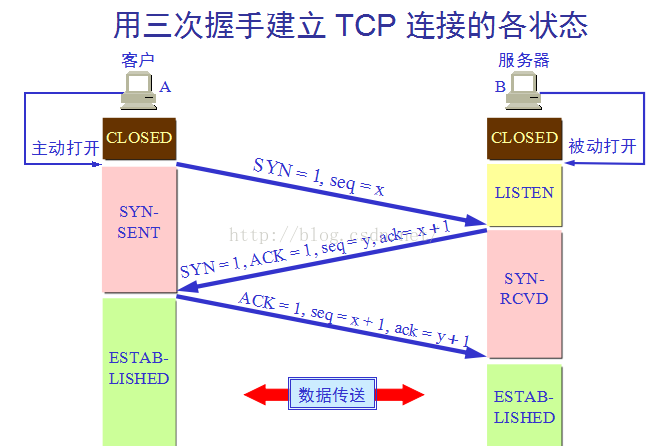
通过三次握手,建立了客户端和服务器之间的连接,现在可以请求和传输数据了。
4.请求和传输数据
比如要通过get请求访问“http://www.dydh.org/”,通过抓包可以看到:
请求网址(url):http://www.dydh.org/
请求方法:GET
远程地址:IP
状态码:200 OK
Http版本: HTTP/1.1
请求头: ...
响应头: ...

注意响应头中有一个:Set-Cookie:"PHPSESSID=c882giens9f7d3oglcakhrl994; path=/",说明浏览器中没有关于这个网站的cookie信息。
当我们下一次访问相同的网站时:
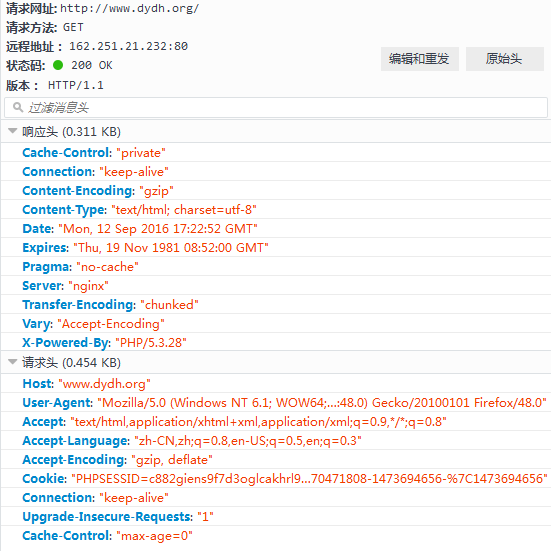
可以看到,请求头中包含了这个cookie信息,
Cookie:"PHPSESSID=c882giens9f7d3oglcakhrl994; CNZZDATA1253283365=1870471808-1473694656-%7C1473694656"
cookie可以用来保存一些有用的信息:Cookies如果是首次访问,会提示服务器建立用户缓存信息,如果不是,可以利用Cookies对应键值,找到相应缓存,缓存里面存放着用户名,密码和一些用户设置项。
通过这种GET请求,和服务器的响应。可以将服务器上的目标文件传输到浏览器进行渲染。
5.浏览器渲染页面
客户端拿到服务器端传输来的文件,找到HTML和MIME文件,通过MIME文件,浏览器知道要用页面渲染引擎来处理HTML文件。
a.浏览器会解析html源码,然后创建一个 DOM树。
在DOM树中,每一个HTML标签都有一个对应的节点,并且每一个文本也都会有一个对应的文本节点。
b.浏览器解析CSS代码,计算出最终的样式数据,形成css对象模型CSSOM。
首先会忽略非法的CSS代码,之后按照浏览器默认设置——用户设置——外链样式——内联样式——HTML中的style样式顺序进行渲染。
c.利用DOM和CSSOM构建一个渲染树(rendering tree)。
渲染树和DOM树有点像,但是是有区别的。
DOM树完全和html标签一一对应,但是渲染树会忽略掉不需要渲染的元素,比如head、display:none的元素等。
而且一大段文本中的每一个行在渲染树中都是独立的一个节点。
渲染树中的每一个节点都存储有对应的css属性。
d.浏览器就根据渲染树直接把页面绘制到屏幕上。
————————————————————————————————————————————————————————————————————————————————————
参考链接:
https://www.zhihu.com/question/34873227
http://blog.csdn.net/qq991029781/article/details/50938475
http://blog.csdn.net/lihongxun945/article/details/37830667
http://www.myexception.cn/go/1860953.html
http://www.nowcoder.com/discuss/3853?pos=264&type=1&order=0
http://www.cnblogs.com/xiaohuochai/p/4750444.html

