【论文阅读】Run, Don't Walk- Chasing Higher FLOPS for Faster Neural Networks1
🚩前言
- 🐳博客主页:😚睡晚不猿序程😚
- ⌚首发时间:
- ⏰最近更新时间:
- 🙆本文由 睡晚不猿序程 原创
- 🤡作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
1. 内容简介
论文标题:Run, Don't Walk- Chasing Higher FLOPS for Faster Neural Networks
发布于:CVPR 2023
自己认为的关键词:轻量化、卷积变种
是否开源?:https://github.com/JierunChen/FasterNet
2. 论文速览
论文动机:
-
降低 FLOPs 和降低延迟没有必然关系,而目前模型更注重 FLOPs,反倒忽略了 FLOPS,导致了延迟更大
老生常谈的问题
-
常见的降低 FLOPs 的操作实际上会更频繁访存,实际上并不能很好的降低延迟
-
轻量化的 ViT 使用 DWConv,仍然有上述的几个问题
本文工作:
- Partial conv:只对特征图的部分通道做卷积,计算少,访存少
- FasterNet:新的网络族
完成效果:
- 比 MobileViT-XSS 快2.8x
- 比Swin-B 快 36%,正确率更高
3. 图片、表格浏览
图一

提出的 PConv,但是也是比较奇怪的,他说就是只对图像的某一部分做卷积,其他的不变
感觉有点违反常理,但是这样好像有利于梯度传播?感觉可以看作是另一种 残差连接
图二
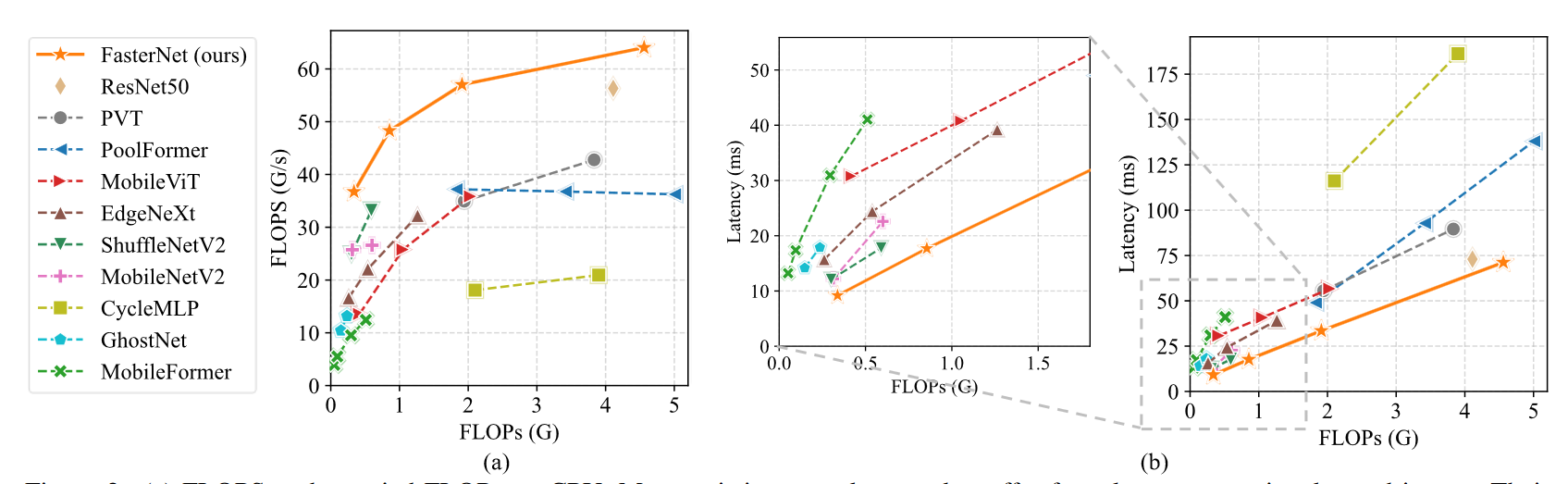
FLOPs 和 相同 FLOPs 下的延迟,这里应该是想要证明 FLOPs 和延迟之间没有必然联系
图三

ResNet50 中间激活可视化,左上角为输入图像,可以看到它有非常的大的冗余
图四
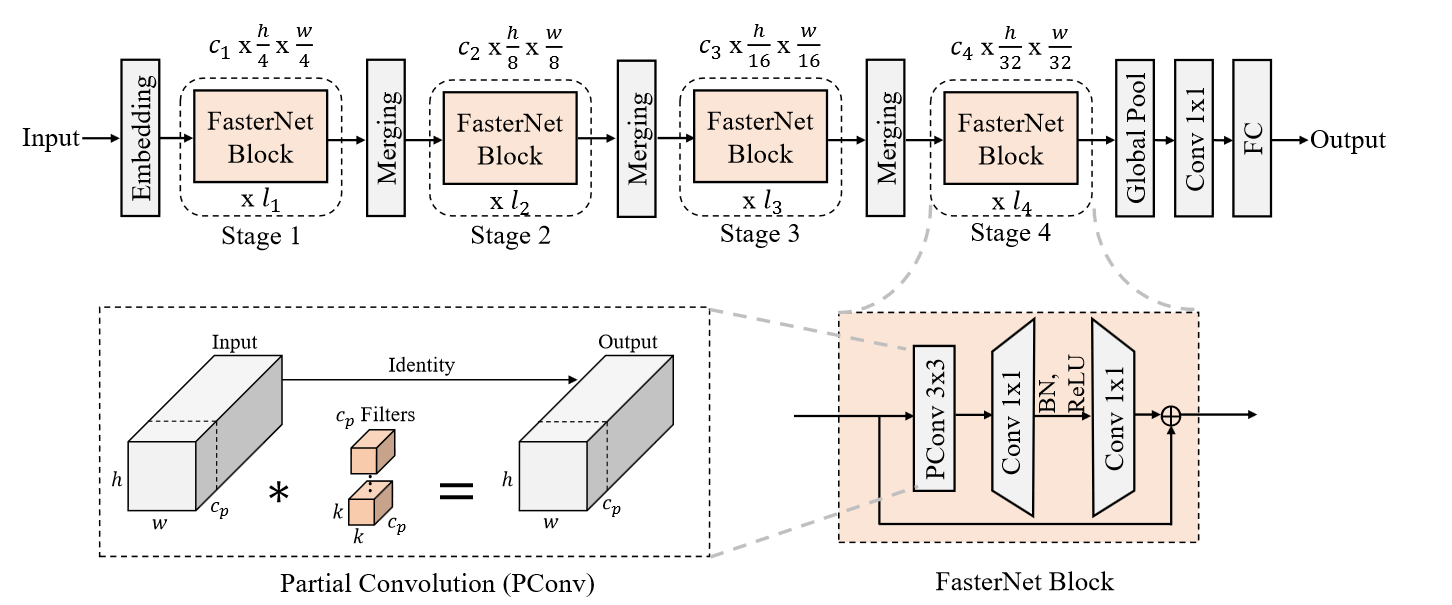
经典四阶段下采样架构
每一个 PConv 都会跟着一个 1x1 卷积,和 DWConv 异曲同工
DWConv 是对每一个通道做卷积,而这个 PConv 是对不同通道做卷积
自由阅读
4. 相关工作
这里讲了一下 CNN 和 Transformer,作者说论文主要集中分析 DWConv,三个原因:
- 自注意力对于卷积的收益暂无理论依据
- 自注意力模型运行速度慢
- DWConv 仍然是最常用的轻量化卷积方式
5. 方法
设计 PConv 和 FasterNet
DWConv
这里提到 DWConv 后面一般会跟着一个 PointWiseConv,用来提高通道数来缓解通道降低带来的性能下降
partial conv
部分卷积
作者这里考虑使用开头的和结尾的几个连续通道
取了四分之一通道来做普通卷积
这里没有选择去除其余通道而是选择保留,因为这些通道对于后面的 PConv 来说是有用的
PWConv
每一个 Pconv 后面都会跟着 PWconv
就是一个 1x1 卷积
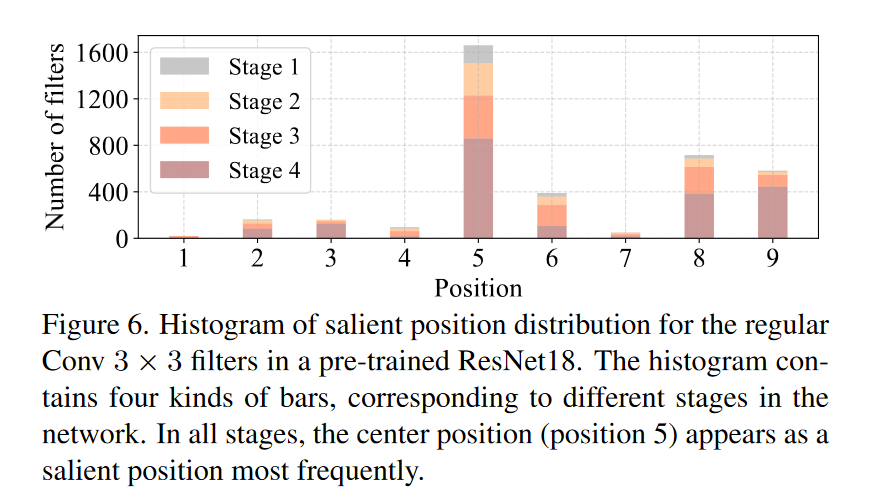
这里提到了它的感受野像一个 T 形,所以他会更关心中心的内容

并且做了一个小实验,证明了普通卷积的中心区域一般来说是较为重要的
FasterNer
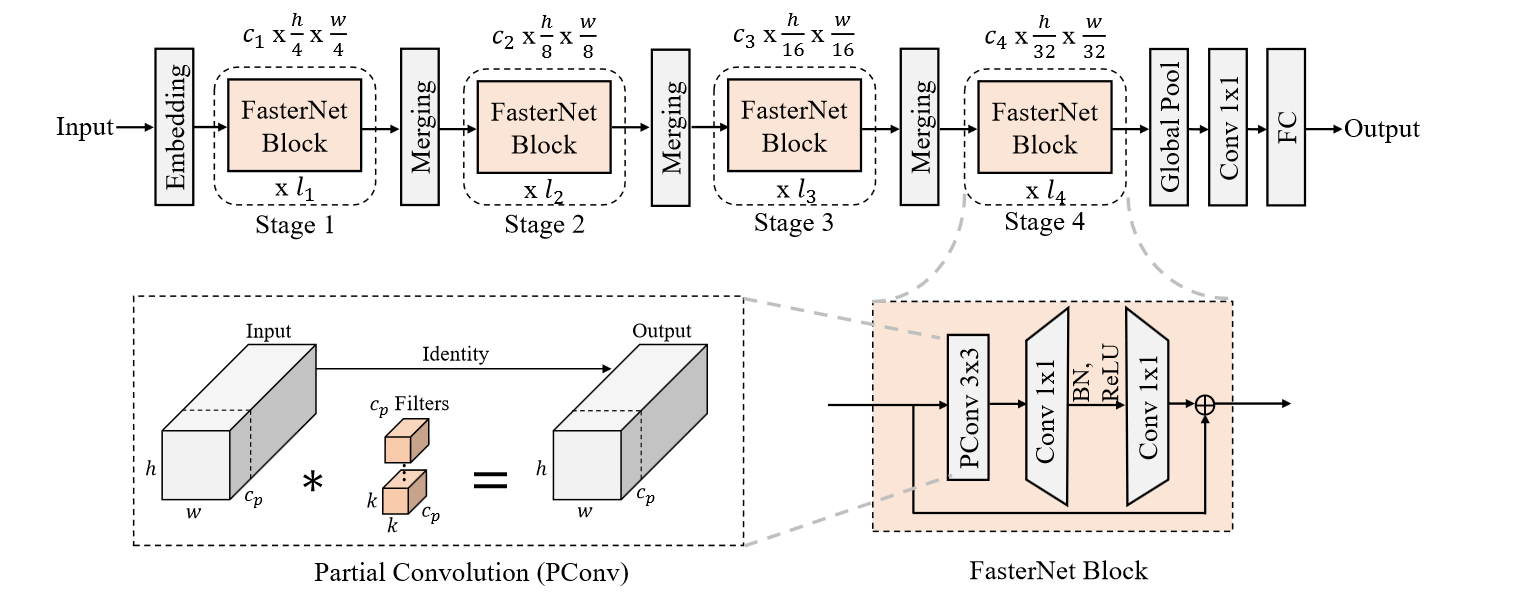
embedding:4x4 步长为 4 的卷积
merging:2x2 步长为 2 的卷积,缩小分辨率扩张通道数
作者发现最后两个 stage 的效率较高,所以选择增加层数
只在 PWConv 的中间使用了归一化,作者说放在这个位置可以保证特征的多样性,并且得到一个可以接受的延迟
作者这里使用了 BN,并使用结构重参数化处理,小模型用了 GELU,较大的模型使用 ReLU
最后使用全局平均池化和 1x1 卷积做分类:D
6. 实验
6.1 实验结果
ImageNet1K 分类
训练策略:
- AdamW,300epoch,batchsize2048,lr=bs/1024,warmup 20 epoch
- 权重衰减、随机深度、标签平滑、mixup、cutmix、randAug
- 前 280epoch 使用 192x192大小,之后使用 224x224 训练 20 epoch
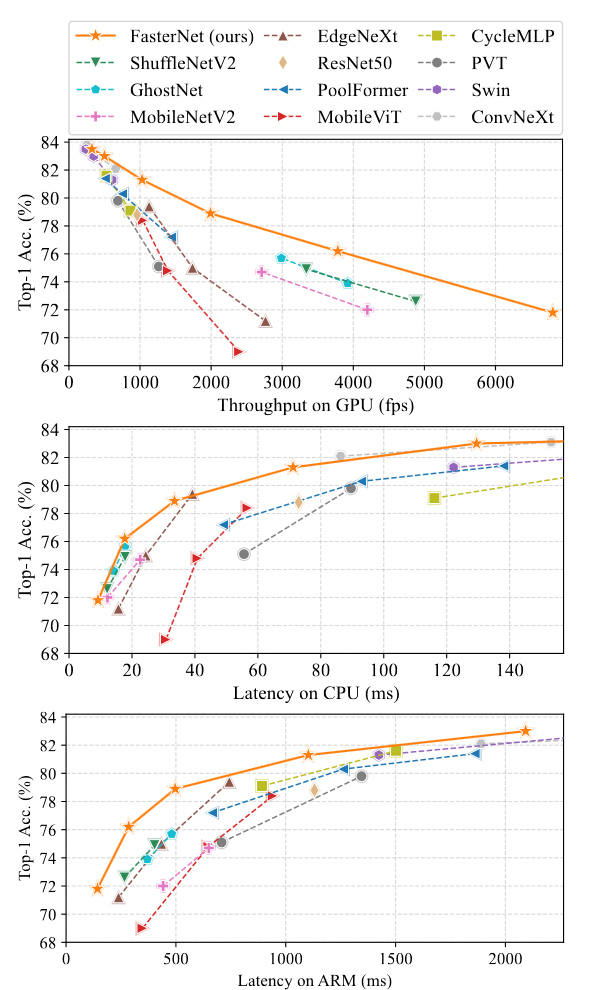
在相同的延迟下效果更好,这个图可以学习一下
看起来和 swin 和 Convnext 这些模型五五开,感觉确实是还可以的
等下,主要得看最上面的那些轻量化模型,速度可以达到这些轻量化模型的好几倍,确实可以
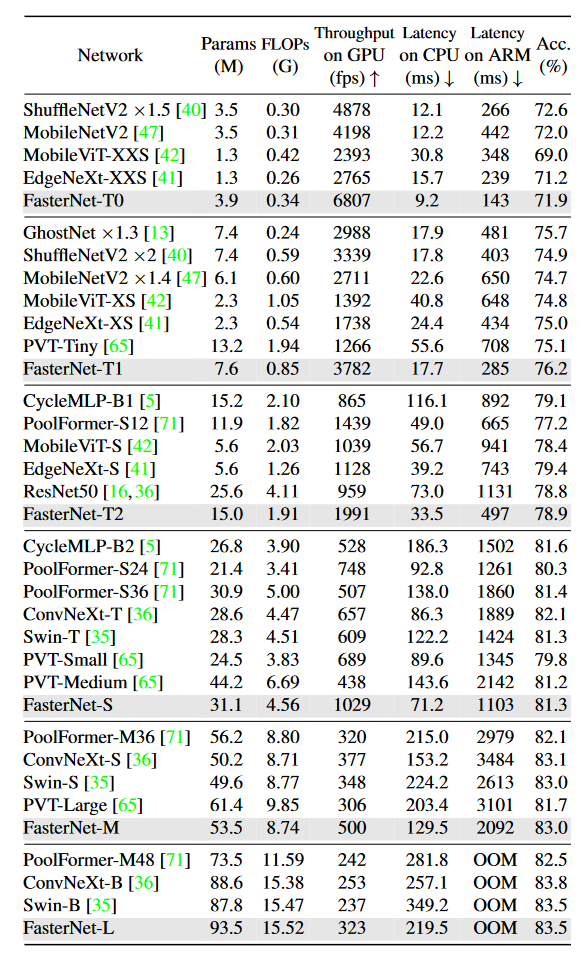
COCO 目标检测

看起来在参数量比较大的情况下表现也挺良好的,但是有一个问题,小模型怎么不见了
说好的分类检测分割,分割任务的实验怎么不见了?
6.2 消融实验
PConv:高 FLOPS,速度更快
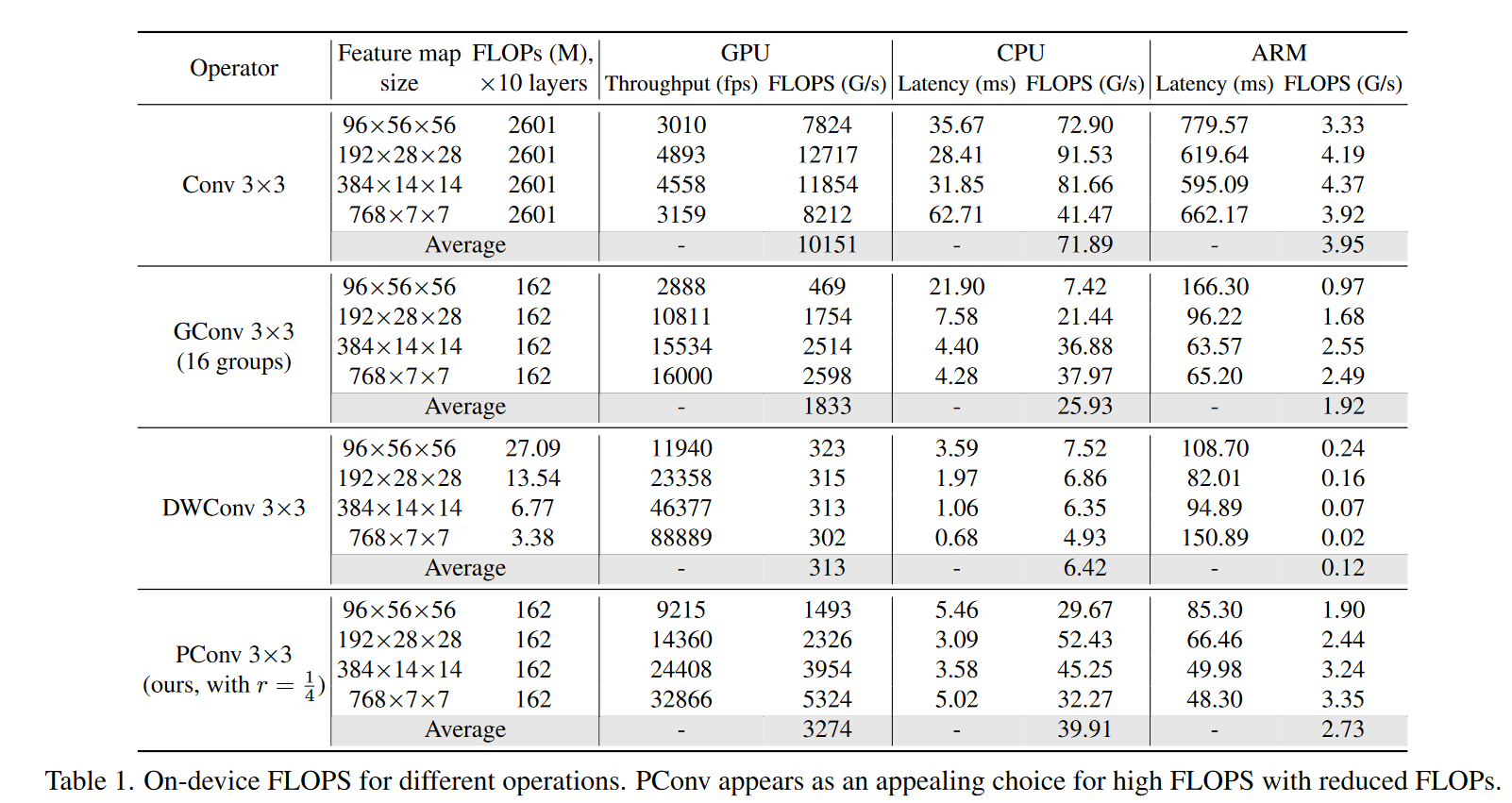
不见得快很多呀?
PConv 和 PWConv 组合效果更佳
构建了一个数据集用来测试:
使用 ResNet50,使用 ImageNet1K 输入模型,取出每一个 stage 的 3x3 卷积前后激活作为数据,并划分为训练、验证、测试集
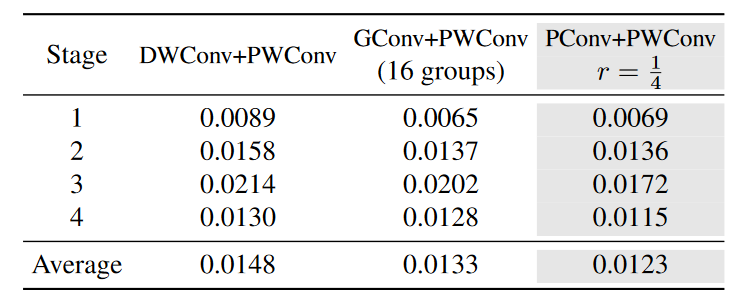
看起来效果确实是最好的(也相差不多就是了)
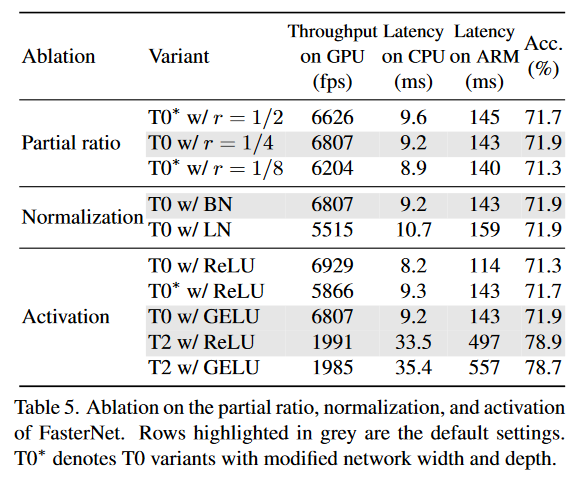
其实上面这个图才是他的消融实验,其他几个部分是他验证模型有效性的实验,我认为放消融实验里面比较合理
但是他的这个消融实验做的真的有够随便的啊。。。
6. 总结、预告
6.1 总结
利用了卷积中通道信息的冗余性,指出只需要对某些通道进行卷积就可以得到不错的性能提升
- 提出部分卷积 PConv,也就是只对四分之一的通道做卷积运算
- PConv 后面跟着 PWConv,也就是再使用 1x1 卷积构建倒瓶颈层
感觉这个还是有点道理的,后面的 1x1 卷积实际上就混合了通道信息,这样应该可以让模型更准确的去抽取信息,降低冗余性


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律