【归一化】Transformer、ConvNeXt 中的 LayerNorm
🚩前言
- 🐳博客主页:😚睡晚不猿序程😚
- ⌚首发时间:2023.6.13
- ⏰最近更新时间:2023.6.13
- 🙆本文由 睡晚不猿序程 原创
- 🤡作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
目录
1. 内容简介
对比在传统 NLP 任务,CNN 任务中的 LayerNorm 的差异,并以 ViT 以及 ConvNeXt 为例,具体查看他们的 LayerNorm 和原本的 LayerNorm 有什么异同
原本觉得都是差不多的,后面发现差异还是挺明显的
2. LayerNorm
2.1 LayerNorm 是什么
提出背景:用于应对序列任务中输入的序列长度可能不一样的问题。在序列任务中使用 BN 效果较差,因为文本数据有长有短,可能导致某些位置没有足够的数据来累计统计量。
具体做法
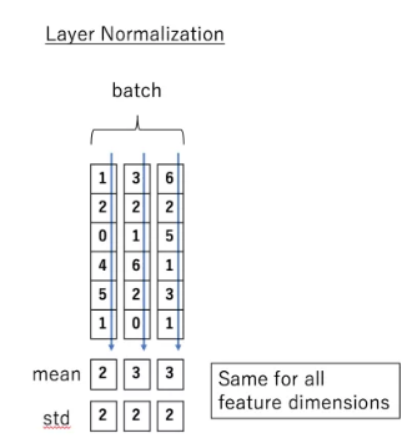
- 输入数据展平
- 对于数据的每一个维度,对其进行归一化【实际上就是对最后一个维度进行归一化】
对比这些 Norm 方式其实关键在于——均值和方差是在哪一个维度上计算得到的
对比 BN,LN 是对一个样本的所有特征进行归一化,而 BN 是对每个通道的所有样本进行归一化
优势
- 每一个特征独立进行标准化,解决了在序列问题中长度不同无法规范化的问题
- 在生成模型上似乎作用更大
劣势
均值和方差在同一个样本内计算,好像没啥道理?这样不同的特征的差异可能被抹除
比如上面这个例子,这样做归一化直接抹除了不同特征之间的差异
2.2 CV 中的 LayerNorm
将上面的理论推广到图像中,其实也就是对每一张图像,独立的计算均值和方差,然后对这张图像进行归一化
我刚开始一直要和 InstanceNorm 弄混,但是确实是这样的
2.2 Transformer 中的 LayerNorm
def forward(self, x):
# x: (B,N,C)
shortcut = x
x = self.norm1(x) # preNorm
x = self.attn(x)
attnout = x+shortcut
mlpout = self.feedForward(attnout)
mlpout = self.norm2(mlpout)
out = mlpout + attnout
return out
直接看一个 Transformer block 的 forward,这里使用的是 preNorm,均值和方差在最后一个维度上计算,也就是每一个 Token 计算均值和方差并进行归一化
假设输入 N 个词语,则会有 N 个均值和 N 个方差
这个也就是 NLP 的 LayerNorm 操作的方式
2.3 ConvNeXt 中的 LayerNorm
ConvNeXt 从 ViT 中吸取了非常多的经验,它的 LayerNorm 也和 NLP 中的 LayerNorm 更为接近
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
上面的代码为 ConvNeXt block 的 forward,可以看到其实它直接使用了 permute 将通道转到最后一维进行 LayerNorm,实际上也就是对每一个像素的所有通道计算均值方差,所以假设分辨率为 H*W,一共会有 H*W 个均值和方差
感觉比 CV 的 LayerNorm 更像 Transformer 的 LayerNorm,如果把像素看成是图像的 Token 的话,和 Transformer 的 LayerNorm 完美契合
总结
分析了 LayerNorm 在不同模型上的作用,要注意计算均值和方差的位置在那里,接着就可以准确的进行判断和分析了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律