【论文阅读】CvT:Introducing Convolutions to Vision Transformers
🚩前言
- 🐳博客主页:😚睡晚不猿序程😚
- ⌚首发时间:
- ⏰最近更新时间:
- 🙆本文由 睡晚不猿序程 原创
- 🤡作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
1. 内容简介
论文标题:CvT: Introducing Convolutions to Vision Transformers
发布于:ICCV 2021
自己认为的关键词:Transformer, Conv, hybrid model
是否开源?:https://github.com/microsoft/CvT
2. 论文速览
论文动机:
- 尽管 ViT 在大规模数据上表现优秀,但是在小规模数据上的性能逊色于同等大小的 CNN model
- ViT 缺乏 CNN 所具有的归纳偏置(局部性,平移等变性,分层次架构),导致 ViT 不适合于某些 CV 任务
本文工作:
- 直接在 ViT 中引入卷积
- ViT 中的映射全部以卷积替代,取消了位置编码操作
完成效果:
- ImageNet22K 上进行预训练,在 ImageNet1K 上取得 87.7% 正确率
3. 图片、表格浏览
图二
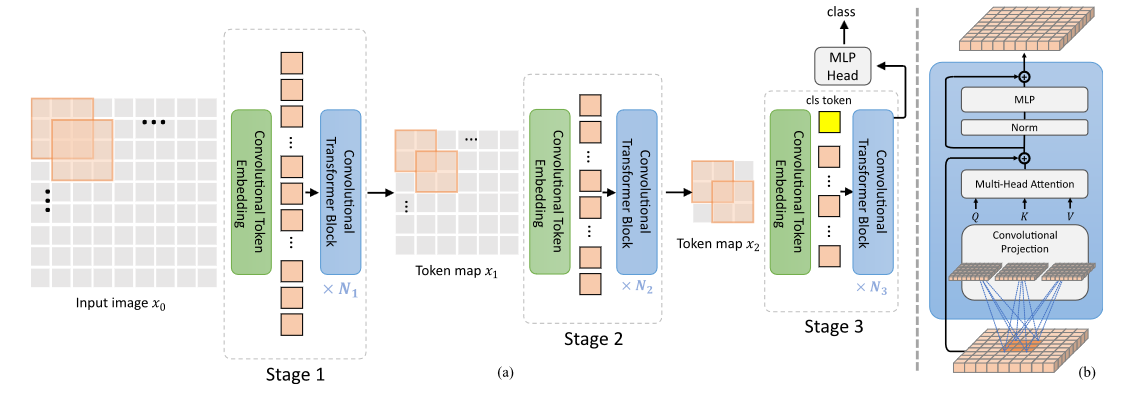
模型架构,把全部的线性层替换成 CNN 了,这样在 ViT 中引入了卷积的归纳偏置,并且控制卷积核的步长可以进行下采样操作,形成类似 ConvNet 的随着网络的深入,分辨率变小,特征通道数增加的架构
图三
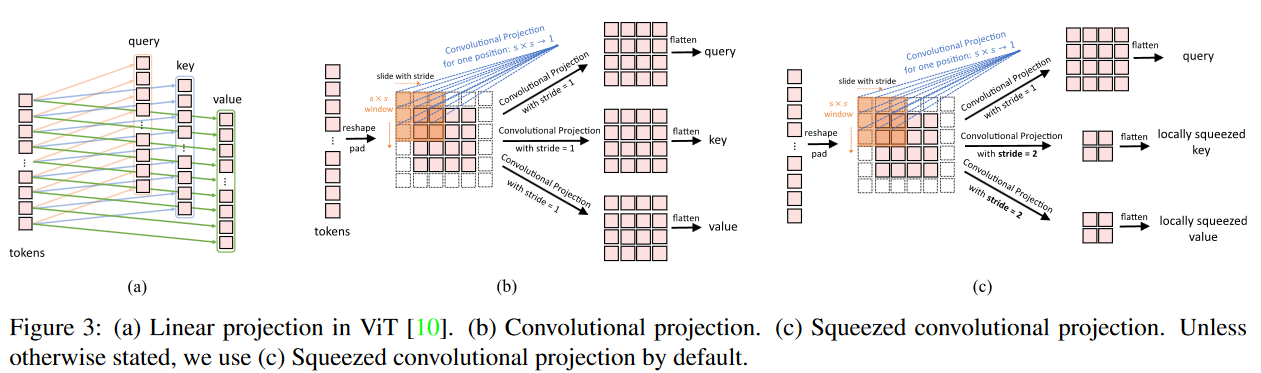
不同的映射方式,通过控制卷积核的步长可以生成较少的 KV,有助于减少计算量
好操作,我认为甚至可以用池化操作,不用参数,更加暴力
不知道他这里用的是什么卷积,经过我的实操,发现实际上在 ViT 中引入卷积建议使用 DWconv(depthwise conv)
自由阅读
4. 相关工作
提到了许多对 ViT 的改进工作:
-
Conditional Position encodings Vision Transformer(CPVT)
修改了位置嵌入方式,让模型在可以处理任意图像大小,并且不需要使用插值算法
-
TNT:一个外部 Transformer block 来把握 patch 间的信息,一个内部 Transformer Block 来把握像素之间的信息
-
T2T:改进了 Tokenization,变为滑动窗口构造 token
Transformer 中引入卷积
以往 NLP 领域都在试把 CNN 引入 Transformer,这里作者也做了类似的改进:
- 将 qkv 运算前的映射改为 CNN
- 金字塔结构实现多尺度
5. 方法
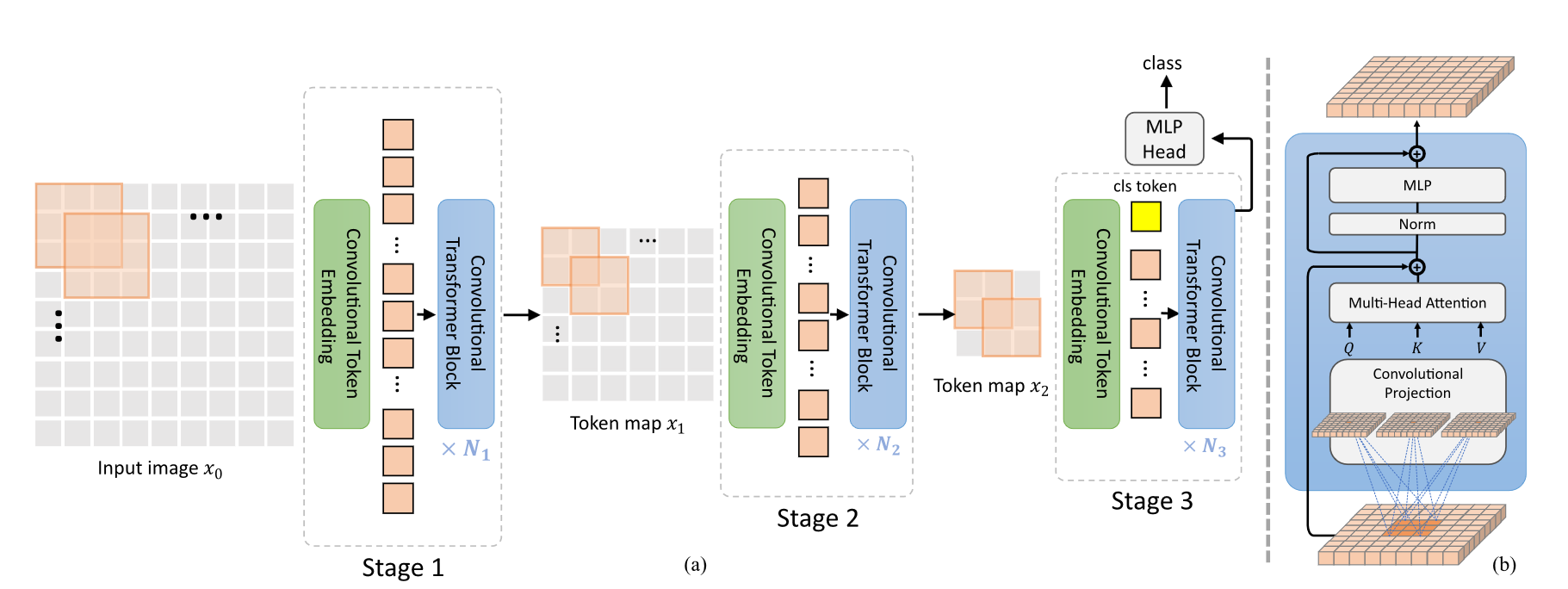
引入了两个卷积模块:
- Convolutional Token Embedding
- Oonvolutional Projection
应该就是在 qkv 映射以及开头的映射层中使用卷积
同样的,将整个模型划分为三个 stage,随着网络的加深,模型的分辨率降低,特征通道数增加
因为引入了卷积,所以只在最后一个 stage 添加 CLS Token 执行分类任务
合理,感觉甚至可以使用全局平均池化
我自己的实践发现,如果降低 patch 的大小,使用细粒度的划分再加上金字塔结构,ViT 的 近视眼效应 会改善
详情参考 How Do Vision Transformers Work?(ICLR 2022)
他用了一系列实验验证 ViT 的性质,总结来说一句话:ViT 是一个低通滤波器,而 CNN 是一个高通滤波器,二者表现的性质相反
Convolutional Token embedding
使用卷积来进行 embedding,这里的一句话提醒了我——卷积不仅可以控制 Token 维度的大小,还可以控制 Token 的数量,可以通过减少 KV 数量的方式降低一点自注意力的计算量
降的不多就是了,我觉得还得是窗口自注意力
效率
引入卷积并提升效率:
- 使用深度可分离卷积
- 使用步长控制 kv 的长度
果然是 DWConv
6. 实验
ImageNet 分类
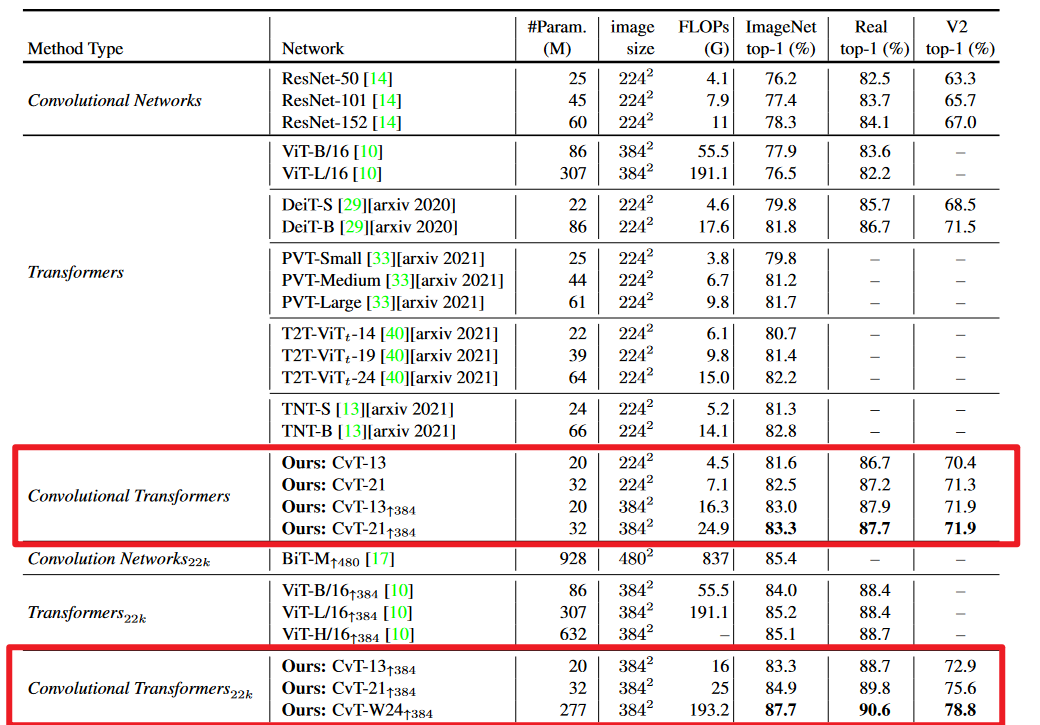
主要关注一下他的 based 模型,想起 PVT 等模型看起来效果不错
只做了分类,而不是分类检测分割全做,感觉感觉实验少了
消融实验
位置编码
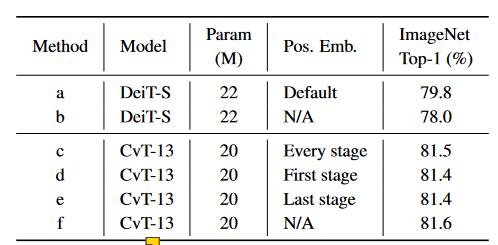
引入了卷积,所以位置编码的去除不会带来较大的影响
卷积映射
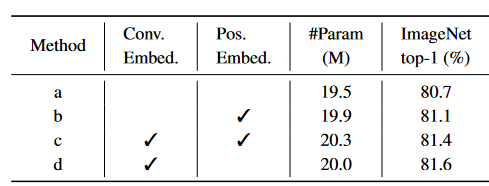
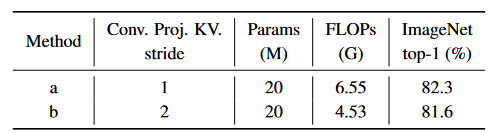
卷积映射可以提升 0.9%,并且使用步长为二的卷积核做映射,可以提升计算效率
6. 总结、预告
6.1 总结
简单粗暴的方式:直接把 ViT 中的全部线性映射换成了 DWConv,这样引入了位置信息,所以可以干掉 position embedding
按照我的想法,在 Token 中使用 DWConv 实际上是一个扩张卷积的操作,这里作者似乎没有没有改动 MLP,仍然保持线性层——我觉得是正确的,我认为 FFN 中的线性映射实际上引入了局部性
这个方法挺实用的,并且参数量的增加也不大,是一篇实用主义论文了
总结来说一句话——可以使用 DWConv 取代 Linear


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律