
Spark基础
Spark基本知识
1、简单架构 (重点)
2、主要数据抽象RDD
RDD ——弹性分布式数据集 (重点)
RDD特性 (重点)
RDD创建
RDD分区器
3、RDD的依赖关系 (重点)
依赖关系对比
Shuffle过程
触发shuffle的算子
4、DAG工作原理
5、算子 (重点)
转换算子(Transformation)
动作算子(Actions):
6、RDD持久化
缓存cache
检查点
7、共享变量
广播变量
累加器
8、分区及优化
分区设计
数据倾斜
9、常见数据源的装载
装载CSV数据源
装载Json文件
10、基于RDD的Spark程序开发
Spark与MapReduce对比
Spark是一种有别于MR的计算框架,它偏向于使用内存处理数据,并且尽可能的减少数据写入磁盘和shuffle的过程。 Spark = 基于内存的分布式计算框架 + SCALA + Schema的应用
为什么是schema而不是sql ? 尽管Spark提供了众多拓展SQL的组件和接口,但不可否认的是它并不是一个数据库,数据往往存储在另一个分布式的存储系统上,Spark同hive一样仅维护关于数据的元数据库。
2014年Spark超过MapReduce成为排序的排行榜第一
MapReduce缺点:
- 只有Map和Reduce两个操作,复杂逻辑需要繁杂的代码支持
- Map和Reduce工作都要落到磁盘
- 数据迁移的资源耗费
- 不适合迭代处理(计算依赖上一次的运行结果,会造成多次读写磁盘)、交互式处理和流式处理
Spark的优点:
- 中间结果可以保存在内存,不需要读写HDFS
- 在发生数据迁移shuffle时会将数据落入磁盘,在内存不足时也会将数据溢写到磁盘
————————————————————————————————————
Spark基本知识
1、简单架构 (重点)



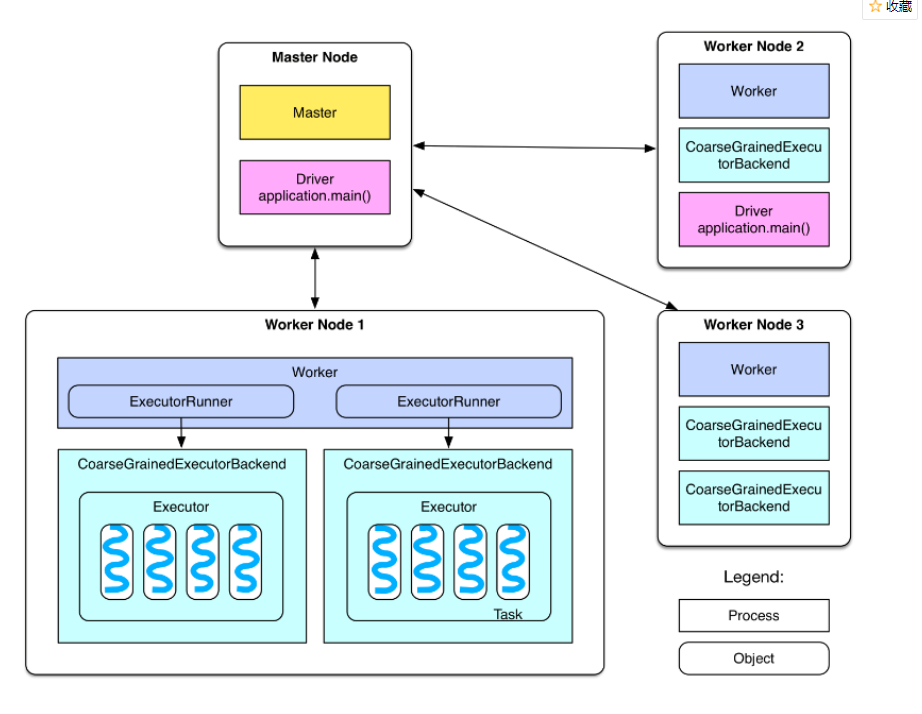
第一步:Driver进程启动之后,会做一些初始化的操作;在这个过程中,就会发送请求到master上,进行spark应用程序的注册,说白了,就是让master知道,有一个新的spark应用程序要运行
第二步:master,在接收到了spark应用程序的注册申请之后,或发送请求给worker,进行资源的调度和分配,OK,说白了资源分配就是executor的分配
第三步:worker接收到master的请求之后,会为spark应用启动executor
第四步:executor启动之后,会向Driver进行反注册,这样,Driver就知道哪些executor是为它进行服务的了
第五步:Driver注册了一些executor之后,就可以开始正式执行我们的spark应用程序了,首先第一个步就是创建初始RDD,读取数据源
第六步:RDD的分区数据放到内存中
第七步:Driver会根据我们对RDD定义的操作,提交一大堆task去executor上
第八步:task会对RDD的partition数据执行指定的算子操作,形成新的RDD的partition
-
每个Spark应用程序包含两部分:驱动代码(Driver)和执行代码(Executor)
-
Driver主驱动,负责发起任务,但不参与实际计算。
应用的主函数,创建Spark Context主导应用的执行。
-
ClusterManager:在集群上获取资源的外部服务
-
Executor执行器,实际计算的执行者,在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,会将数据存储在内存或硬盘中。执行器不会共享,每个job会分配各自独立的Executor(可以设置Executor的Task数目)。
-
Job/Task/Stage:
- 一个应用程序可能包含多个Job,由action算子触发,每个Job包含多个Task的并行计算。
- 每个Job将是否发生数据迁移shuffle或Action(result)动作,将Task按前后顺序分为不同的stage,各个 stage 会按照执行依赖顺序依次执行(可以并行,无依赖时)。每个stage就是一个Task集合,这些Task集合之间存在相互依赖关系(类似map和reduce的依赖关系)。
- 每个Task是Stage下的一个工作单元(Executor内的执行对象),Task是按RDD的分区数分配的,一个Task对应处理当前RDD的一个分片。同一Excutor内的Task可以通过共享堆内内存交换数据。
-
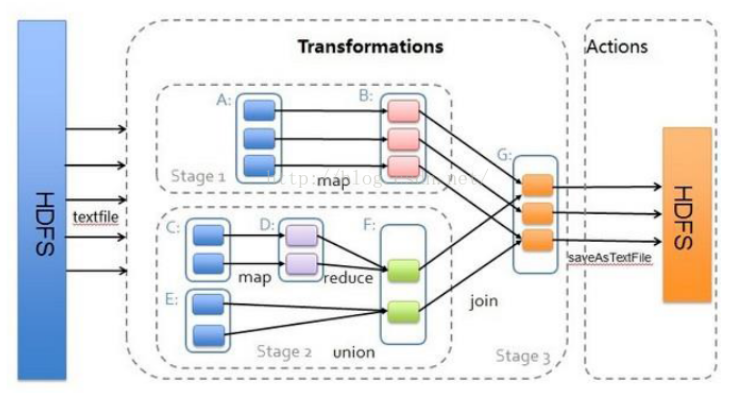
注:下面的流程图仅展示Stage与算子的关系,不是Task。
![]()
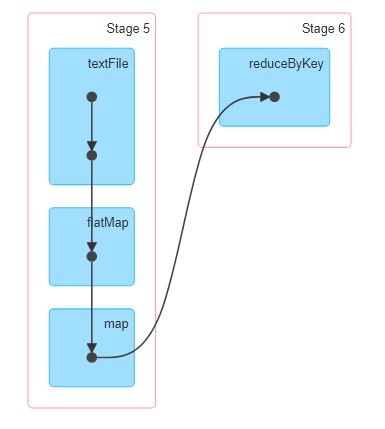
问:为什么要划分Stage?
答:保持数据本地化,移动计算而不是数据,保证一个Stage内不会发生数据的迁移
2、主要数据抽象RDD
注意:RDD即resilient distributed dataset,这个数据抽象是分布式的。尽量使计算任务运行在数据存储的节点上。
RDD ——弹性分布式数据集 (重点)
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度
-
首先,RDD是一种数据抽象,是对数据和操作的描述,包含指向数据存储位置的索引,不存储数据。
-
其次,RDD是描述分布式数据的信息结构,描述的是分布在不同节点上的数据对象。
- RDD是包含多个数据分片的集合,每个分区的数据分布在集群的不同节点上。数据存储在集群的工作节点上的内存中,分区数由Spark根据集群情况推断,也可以自己指定分区数。
- RDD是只读的,避免了写入(并发,锁)的时间成本
- RDD一般存储在内存中,不足时将写入磁盘
- 不同RDD之间存在依赖关系,依赖关系是有向无环的,这个依赖关系可以有分支但绝对不会成环,这使得RDD故障时可以依赖其他RDD来恢复。
-
最后,Spark是通过RDD操纵数据,任何数据必须先被包装为RDD才能使用Spark的各类操作
总结:RDD是描述数据的,而且描述的是分布式的数据,也就是一个RDD数据单元内的数据可以不在一个节点上,这种宽泛的数据描述结构减少了大量不必要的shuffle操作。比如union操作,并不移动数据,而是重新组织描述数据的RDD。
RDD特性 (重点)
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
RDD创建
- 使用并行化创建(同在内存中的List数据):::说明RDD就是以集合结构表述数据的
val sc=SparkContext.getOrCreate()
sc.makeRDD(List(1,2,3,4))
sc.parallelize(List(1,2,3,4,5,6),5) //5是分片数
- 通过加载文件创建
val distFile=sc.textFile("file:///home/hadoop/data/hello.txt")
//不指定file的话默认使用hdfs路径
//默认以一行数据为一个元素
//支持压缩文件和通配符
//以Spark集群方式运行,应保证每个节点均有该文件的本地副本,空间换时间,减少数据传输时间成本
//对应存储就是saveAsTextFile
- 大量小文件加载
SparkContext.wholeTextFile()
//返回<filename,fileContext>的pairRDD
-
PairRDD 以键值对形式存储的RDD
- PairRDD,集合元素为二值元组的RDD即键值对RDD
- Spark为PairRDD提供了一系列的ByKey函数
-
最佳应用:
- 测试环境:使用本地或者内存集合创建RDD
- 生产环境:使用HDFS文件创建RDD
RDD分区器
- 分区器仅适用于PairRDD
- 任何会触发shuffle的宽依赖算子都会产生新的分区
- 这些算子往往都重载了包含分区器或者分区数的函数
1、Hash分区与默认分区
val rdd1=sc.makeRDD(List(1->"x",2->"y"))
val rdd2=rdd1.partitionBy(new org.apache.spark.HashPartitioner(5))//Hash分区
rdd2.foreachPartition(it=>{it.foreach(print(_));println(org.apache.spark.TaskContext.getPartitionId)})
/*
getPartitionId)})
Partition:0
Partition:3
Partition:4
(1,x)Partition:1
(2,y)Partition:2
*/
如果是rdd1,即默认分区时,按元素顺序进行分区
/*
(1,x)Partition:0
(2,y)Partition:1
*/
2、范围分区
3、RDD的依赖关系 (重点)
-
Lineage:血统、遗传
- RDD最重要的特性之一,保存了RDD的依赖关系
- RDD实现了基于Lineage的容错机制
-
依赖关系(父类主体)
- 宽依赖(超生家庭):一个父分区会分发到多个子分区,会发生shuffle
- 窄依赖(独生家庭):一个父分区只分发到一个子分区
![]()
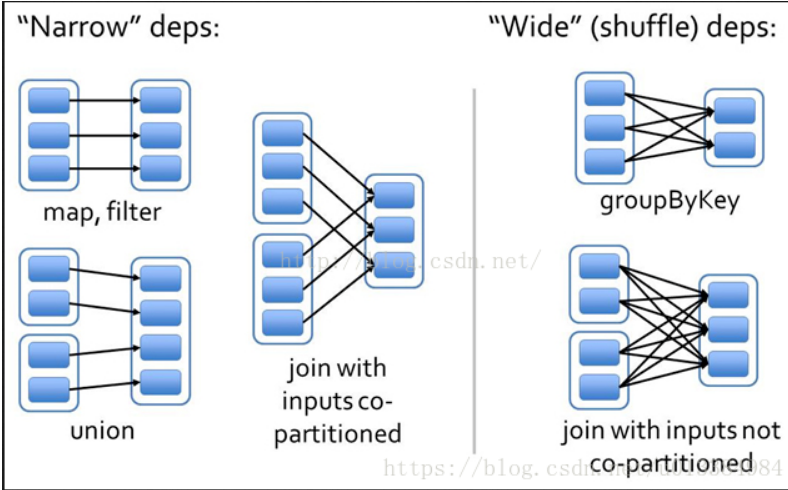
依赖关系对比
- 宽依赖对应shuffle操作,需要在运行时将同一个父RDD的分区传入到不同的子RDD分区中,不同的分区可能位于不同的节点,就可能涉及多个节点间数据传输(网络传输成本高)
- 当RDD分区丢失时,Spark会对数据进行重新计算,对于窄依赖只需重新计算一次子RDD的父RDD分区(容错恢复成本高)
- 窄依赖比宽依赖更有利于优化
Shuffle过程
-
shuffle即洗牌、迁移、混入,目的是在分区之间重新分配数据
- 父RDD中同一分区中的数据按算子要求重新进入子RDD的不同分区中 (宽依赖,一个父RDD的数据分配给多个子RDD)
- 中间结果写入磁盘(分区存储,同MR)
- 数据由子RDD拉取,而不是父RDD推送
- 默认情况下,shuffle不会改变分区数量(给定算子分区参数即可改变)
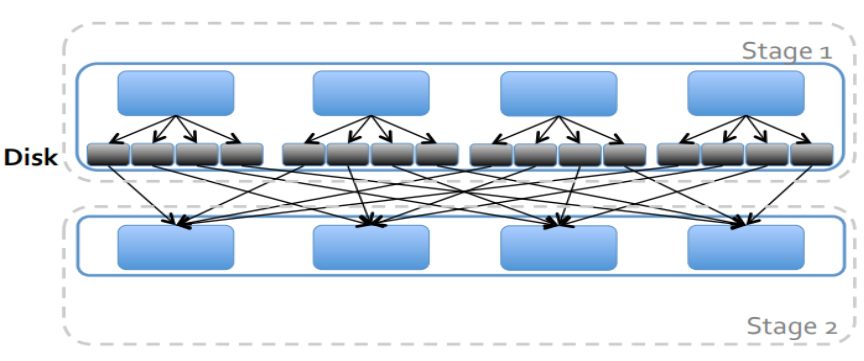
触发shuffle的算子
- ReduceByKey、
- GroupByKey、
- aggregateByKey、
- combineByKey、
- SortByKey、
- Distinct、intersection、subtract
- join:如果父子类分区协同的话,是窄依赖,不发生shuffle
问:shuffle的最佳实践?
答:尽量避免shuffle,提前部分聚合减少数据移动
4、DAG工作原理
DAG由RDD之间的依赖关系形成,DAG根据RDD之间的宽依赖关系将RDD分为多个Stage,
划分规则是:从后往前,遇到宽依赖就切分为一个新的stage
每个Stage由一组并行的Task组成

5、算子 (重点)
转换算子(Transformation)
RDD的所有转换都不会直接计算结果
- 仅记录作用于RDD上的操作,用于生成RDD DAG(有向无环图)=====>就是生成操作步骤记录
- 当遇到动作算子(Action)时才会进行真正计算
常见转换算子:
-
textfile 算子:读入指定路径的文件,返回一个RDD
-
map 算子 :对RDD的每一个元素都执行一个指定的函数来产生一个新的RDD,新旧元素是一一对应的,输入分区与输出分区一一对应。
-
filter算子:对RDD中的元素尽心那个过滤筛选,对每个元素应用指定函数,将返回值为True的元素保留在新的RDD中
-
mapValue算子:仅适用于PairRDD,原RDD中的Key保持不变,对value执行指定的函数来生成一个新的value的PairRDD
-
distinct(n)算子:去重原RDD中的各个元素(不安全的:顺序会打乱),参数n指定分区数或分区器,缺省则使用conf值。
val dis = sc.parallelize(List(1,2,3,4,5,6,7,8,9,9,2,6)) dis.distinct.collect dis.distinct(2).partitions.length -
reducByKey算子:仅适用于PairRDD,按Key值分组,然后按指定函数迭代归并所有value返回一个最终值
val a = sc.parallelize(List("dog", "salmon", "pig"), 3) val f = a.map(x=>(x.length,x)) //匿名函数,a\b分别对应一次迭代的前后value值 f.reduceByKey((a,b)=>(a+b)).collect //下划线代表两个缺省参数,默认就是一次迭代的前后value f.reduceByKey(_+_).collect -
groupByKey : 仅适用于PairRDD,按Key值分组,生成一个同组的value组合为可迭代的value集合的新PairRDD。
-
sortByKey算子:仅适用于PairRDD,按Key值的ASCII码进行排序,默认升序,false参数设置降序
-
union算子:拼接两个同类型的RDD,可以用++代替
-
intersaction算子 :求两个RDD的交集RDD
-
join算子:对两个PairRDD进行join操作,生成新的PairRDD,新的RDD仅保留具有相同Key值的元素,如果旧的value都相同的话,新value还是该值。如果不都是相同的话,新value是旧value形成的二值元组。
//相同的key是Apple val j1 = sc.parallelize(List("abe", "abby", "apple")).map(a => (a, 1)) val j2 = sc.parallelize(List("apple", "beatty","beatrice")).map(a => (a, 2)) //join,仅保留相同的 j1.join(j2).collect //res0 Array[(String, (Int, Int))] = Array((apple,(1,2))) //leftOuterJoin 保留左侧RDD的所有元素,未匹配到的key的value二值组之二设置为None j1.leftOuterJoin(j2).collect//Array[(String, (Int, Option[Int]))] = Array((abe,(1,None)), (abby,(1,None)), (apple,(1,Some(2)))) //rightOuterJoin 同理
动作算子(Actions):
RDD遇到Action就会立即计算,本质上是通过SparkContext触发RDD DAG的执行(也就是触发前面所有转换算子的执行计划)
常见动作算子:
-
collect :以Array返回RDD的所有元素。一般在过滤或者处理足够小的结果时使用
val rdd=sc.parallelize(List(1,2,3,4,5,6)) rdd.collect //res0: Array[Int] = Array(1, 2, 3, 4, 5, 6) -
count :返回数据集中元素的个数
-
take :返回数据集中的前n个元素
val rdd=sc.parallelize(List(1,2,3,4,5,6)) rdd.take(3) //res0: Array[Int] = Array(1, 2, 3) -
first :返回RDD数据集的第一个元素
-
reduce: 根据指定函数,对RDD中的元素迭代进行两两计算,返回计算结果
注意区分于reduceByKey:reduce返回的是计算的计算而不是新的RDD
val a=sc.parallelize(1 to 10) a.reduce((x,y)=>x+y) //等价于 a.reduce(_+_) //res3: Int = 55 val b=sc.parallelize(Array(("A",0), ("A",2), ("B",1), ("B",2), ("C",1))) b.reduce((x,y)=>{(x._1+y._1,x._2+y._2)}) //res4: (String, Int) = (AABBC,6) -
foreach : 对RDD中每个元素执行执行函数,无返回值
scala> val rdd=sc.parallelize(1 to 5) scala> rdd.foreach(print(_)) 12345 //没有res产生,说明无返回值 -
lookup :仅使用于PairRDD,给定参数K,返回K对应的所有V值
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4))) rdd.lookup('a') //res5: Seq[Int] = WrappedArray(1, 2) -
max/min :返回元素中的最大和最小值(按sort排序得到的最值)
-
saveAsTextFile : 保存RDD数据至文件系统
val rdd=sc.parallelize(1 to 10,2) rdd.saveAsTextFile("hdfs://hadoop000:8020/data/rddsave/")//hdfs可以省略,ip和port也可以省略 /* [root@hadoop137 ~]# hdfs dfs -cat /res/part-00000 1 2 3 4 5 */
6、RDD持久化
缓存cache
RDD有缓存机制:缓存数据至内存/磁盘,大幅度提升Spark应用性能
cache=persist(MEMORY)
persist
缓存策略Storage Level
MEMORY_ONLY (默认)
MEMORY_AND_DISK
DISK ONLY
默认在shuffle时候发生缓存,避免数据丢失
val u1 = sc.textFile("file:///root/data/users.txt").cache
u1.collect//删除users.txt,再试试
u1.unpersist()
常见缓存应用场景
- 从文件加载数据之后,因为重新获取文件成本较高
- 经过较多的算子变换之后,重新计算成本较高
- 单个非常消耗资源的算子之后
注意事项
- cache()或persist()后不能再有其他算子
- cache()或persist()遇到Action算子完成后才生效
检查点
类似于快照
sc.setCheckpointDir("hdfs:/checkpoint0918")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.checkpoint //转换算子,遇到action后才会生成checkpoint
rdd.collect //生成快照
rdd.isCheckpointed
rdd.getCheckpointFile
与collecct快照的区别在于:
- checkPoint其实保存仅是某一阶段的RDD的信息和数据
- 检查点会删除RDD lineage(依赖关系,也就是说生成的是孤立的单个DAG节点),而缓存不会
- SparkContext被销毁后,检查点数据不会被删除,从set语句可以看出来cp被存储到磁盘了,因此下一次启动sc还可以获取。
7、共享变量
广播变量
当多个Task同时需要一个Driver端的数据时,允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本,多个task共享Excutor上的广播变量,减少了Task的资源耗费。
val broadcastVar=sc.broadcast(Array(1,2,3)) //定义广播变量
broadcastVar.value //访问方式
注意事项:
- 广播变量一般来说不可写的,是只读的。但是部分数据类型可以改变元素的值的实现修改操作。
- 广播变量只能在Driver端定义,不能在Executor端定义。
- 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
- Driver端变量在每个Executor每个Task保存一个变量副本
- Driver端广播变量在每个Executor只保存一个变量副本
- 不能广播RDD,因为RDD是描述而不是数据本身
Tips:Driver端变量,按Task分发。广播变量,按Executor分发。
累加器
特殊的广播变量,只允许+加操作,常用于实现计数。相当于多Excutor并发向Driver端发送+的写入请求,Driver应该采取消息队列形式实现并发写入的。
val accum = sc.accumulator(0,"My Accumulator")
sc.parallelize(Array(1,2,3,4)).foreach(x=>accum+=x)
accum.value
//res0:Int=10
8、分区及优化
分区设计
-
分区大小限制为2GB
-
分区太少,不利于并发,更容易受数据倾斜影响 groupBy, reduceByKey, sortByKey等内存压力增大
-
分区过多,Shuffle开销越大,创建任务开销越大
-
经验,每个分区大约128MB,如果分区小于但接近2000,则设置为大于2000
数据倾斜
指分区中的数据分配不均匀,数据集中在少数分区中
- 严重影响性能
- 通常发生在groupBy,join之后
- 解决方案:使用新的Hash值(如Key加盐)重新分区
Tip:查看分区编号org.apache.spark.TaskContext.getPartitionId
9、常见数据源的装载
装载CSV数据源
-
CSV首行切除
- Spark1.x 中使用Spark Context
val lines = sc.textFile("file:///home/kgc/data/users.csv") val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(",")) //分区获取下标,然后map操作,默认分区时按元素顺序号分区的,因此idx==0就是分区1,iter时一个数据迭代器,textfile将文件按行划分元素,drop(1)就是丢掉第一行了。 //不稳定,分区0不一定是第一行所在分区 val fields=lines.filter(l=>l.startsWith("user_id")==false).map(l=>l.split(",")) //通过过滤器移除首行,效果与上一行相同 //可靠,性能低,遍历所有数据+if //综上 val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(","))- Spark2.x 使用SparkSession (推荐)
val df = spark.read.format("csv").option("header","true").load("file:///home/kgc/data/users.csv") //read 读,format 格式,option选项 header=true 即有表头
注:装载结果的格式是DataFrame,基于RDD的包装类,支持泛SQL的语法,也支持基于RDD的算子
装载Json文件
使用Spark1.x 的SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.json")
//scala内置的JSON库
import scala.util.parsing.json.JSON
val result=lines.map(l=>JSON.parseF ull(l))
//测试时lines可以用手写的json文本代替,使用三引号输入包含引号的json字符串
使用Spark2.x 的SparkSession
val df = spark.read.format("json").option("header", "true").load("file:///home/kgc/data/users.json")
注:Json返回的时Option格式的数据,使用getOrElse获取元素内容
10、基于RDD的Spark程序开发
开发环境:IDEA+MAVEN+SCALA
pom.xml
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.2.0</version>
</dependency>
demo
import org.apache.spark.{SparkConf, SparkContext}
object App extends App {
System.setProperty("hadoop.home.dir", "C:\\Program Files\\hadoop-2.7.3")
val conf=new SparkConf().setMaster("yarn").setAppName("WorldCount")//yarn 在服务器上运行
val sc=SparkContext.getOrCreate(conf)
var res0=sc.textFile("hdfs:/FIFA.txt").flatMap(x=>{x.split("[,\\.!\\s]")}).filter(x=>x!="").map(x=>(x->1)).reduceByKey(_+_).sortBy(x=>{x._2}).collect.reverse
res0.foreach(x=>{print(x+",")})
}
打包上传
注:关于打包,Spark服务器上是不需要IDEA中的依赖包的,而且maven打包scala程序需要额外的插件,这里简化配置直接使用Porject Structure中配置Artifacts,选择+号添加 Jar —> From modules with dependencies,配置主类,完成。最后在生成的Output Layout中删除除自身的编译输出包以外的所有Extract。回到IDEA主界面,菜单build -> build artifacts -> build
spark-submit
--class com.spark.core.WordCount
--master spark://192.168.137.137:7077
/root/spark-1.0.SNAPSHOT.jar
//如果主函数args需要类似数据文件路径的参数 直接在命令后追加即可
11、知识点小提问 如何判断RDD的宽依赖与窄依赖?
答:父RDD的一个分片的数据要分发到子RDD的多个分片上是为宽依赖,父RDD的一个分片的数据分发到子RDD后还在一个分片上即为窄依赖。
DAG工作原理
答:DAG指RDD的有向无环图,当job生成后,流程从后往前遍历,根据RDD间的依赖关系将RDD分为不同的Stage,划分的依据时当出现宽依赖关系时。每个Stage都是一组并行的Task集合。
Driver、Worker、Executor、Task的关系是什么?
答:Driver负责发起任务,但不参与实际计算。是Spark应用的主函数,创建Spark Context主导应用的执行,为Worker们分发指令。
Worker是集群中节点上的工作进程,一个物理节点可以有一个或多个Worker,负责Executor的的创建和分配
Executor是Task的执行容器,一个Executor包含一个或多个Cpu核心和内存,是Task的实际执行者
Task对应RDD中的各个分片,每个Task处理一个分片,由Driver分发到Worker上,Worker为其指定Executor,Executor完成Task的执行
Stage、RDD、Partition、Task的关系又是什么?
答:RDD是对于一个阶段的数据的描述,是一种数据抽象模型,一个RDD中包含多个Partition,这些Partition可能存储在不同的节点上。每个Task对应处理一个RDD中的一个Partition,多个Task并行执行会根据算子对应产生多个RDD,多个RDD的集合根据依赖关系的不同被划分为不同的Stage。划分的依据是父RDD同一分区内的数据是否会被分发到子RDD的多个分区上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号