
Spark集成
Spark集成
一、Spark 架构与优化器
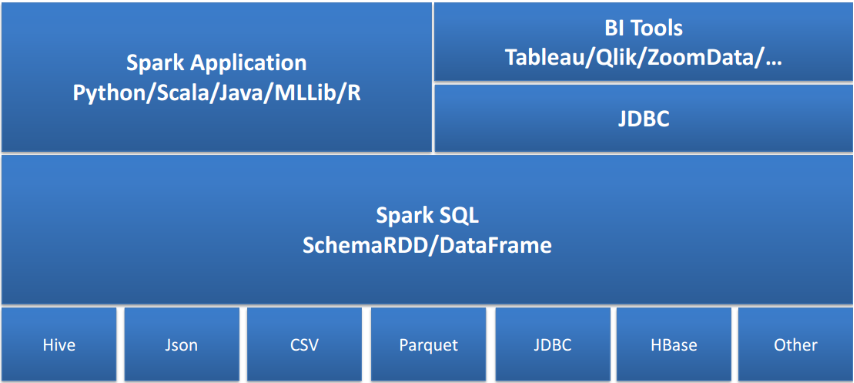
1.Spark架构 (重点)
- 能够直接访问现存的Hive数据(链接Hive的元数据寻址)
- 提供JDBC/ODBC接口供第三方工具借助Spark进行数据处理
- 提供了更高层级的接口方便地处理数据(sql算子,DataFrame类)
- 支持多种操作方式:SQL、API编程 (Spark-sql ,spark-shell,spark API)
- 支持多种外部数据源:Parquet、JSON、RDBMS、csv、text、hive、hbase等
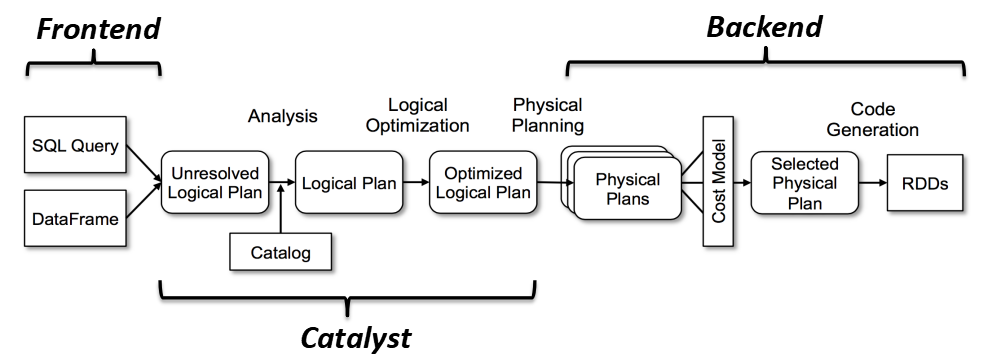
2.Spark优化器
SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan; Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan; 此时再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan; 优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan;
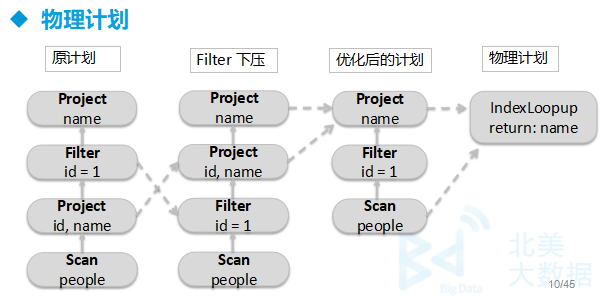
-
优化
1、在投影上面查询过滤器 2、检查过滤是否可下压
二、Spark+SQL的API (重点)
前言:Spark对具有Schema的数据的维护其实与Hive是相似的,自身维护了一个元数据库和一个数据仓库,DataFrame则是针对具有schema的数据所包装RDD类,提供了可以直接操作schema数据的sql接口,并且提供了sql函数直接解析原生sql语句。同时Spark也可以通过hive的metastore接口或者jdbc接口链接到外部的元数据库上,通过这个元数据库便实现了对hive的数据仓库和RDBMS上的数据的操作。
-
SparkContext
-
SQLContext
- Spark SQL的编程入口
-
HiveContext
- SQLContext的子集,包含更多功能
-
SparkSession(Spark 2.x推荐)
- SparkSession:合并了SQLContext与HiveContext
- 提供与Spark功能交互单一入口点,并允许使用DataFrame和Dataset API对Spark进行编程
———————————————————————————————————————————
1.DataSet简介
特定域对象(Seq、Array、RDD)中的强类型的集合,基于RDD,与RDD最大的区别在于:DS有schema数据结构信息。DataSet= RDD + Schema
- DataSet即有Schema数据结构信息(行列)的数据集合
scala> spark.createDataset(1 to 3).show
scala> spark.createDataset(List(("a",1),("b",2),("c",3))).show
scala> spark.createDataset(sc.parallelize(List(("a",1,1),("b",2,2)))).show
- createDataset()的参数可以是:Seq、Array、RDD
- 上面三行代码生成的Dataset分别是:Dataset[Int]、Dataset[(String,Int)]、Dataset[(String,Int,Int)]
- Dataset=RDD+Schema,所以Dataset与RDD有大部共同的函数,如map、filter等
———————————————————————————————————————————
2.DataFrame简介
基于DS,但是元素仅限为Row类,这种限定使得DF的操作可以针对性的优化,因此DF的操作往往比DS快3倍以上。Row就相当于SQL中的记录
DataFrame = RDD[ROW] + Schema
-
DataFrame=Dataset[Row]
-
类似传统数据的二维表格
-
在RDD基础上加入了Schema(数据结构信息)
-
DataFrame Schema支持嵌套数据类型
- 对应HBase的数据结构,资源消耗较大
- struct
- map
- array
-
提供更多类似SQL操作的API,比如直接使用sql算子以sql语句作为参数进行查询:
df.sql("select * from table_name")
———————————————————————————————————————————
3.RDD与DF/DS的创建
WHAT is the schema of this:

- DS/DF 转换到RDD
case class Point(label:String,x:Double,y:Double)
val points=Seq(Point("bar",3.0,5.6),Point("foo",-1.0,3.0)).toDF("label","x","y")
//转换
val s=points.rdd
-
将RDD组织为DS或DF
- toDF/toDS 算子
- 这种方法根据RDD内部数据类型的反射信息自动推断生成Schema
case class Person(name:String,age:Int)
//反射获取RDD内的样例类的Schema来构造DF
import spark.implicits._
val people=sc.textFile("file:///home/hadooop/data/people.txt")
.map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)).toDF() ////map构造实例类,toDS或者toDF方法
people.show
people.registerTempTable("people") //将DF注册为临时表,以使用sql语句
val teenagers = spark.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
teenagers.show()
//也可以不定义样例类直接使用Array、Seq等集合的toDF方法,参数给定为列名,类型会自动推断
-
通过Schema+DF来定义有结构的DF (重点)
sc.textfile读取有格式的文本时需要解决隐式的格式问题以及数据头问题
spark.read.格式 无法解决字段格式自动转换,全是String
因此我们通过预定义schema再读取的方式解决繁琐的数据类型转换问题
前提是所有字段都是所需的,不然需要额外定义不关心的字段
import org.apache.spark.sql.Row import org.apache.spark.sql.types.{StructType, StructField, StringType} val myschema=new StructType().add("order_id",StringType).add("order_date",StringType).add("customer_id",StringType).add("status",StringType) val orders=spark.read.schema(myschema).csv("file:///root/orders.csv") -
通过ROW+Schema组织DF (适用于外部的原始数据源)
//构造ROW对象和指定Schema的方法组合 people=sc.textFile("file:///home/hadoop/data/people.txt") val schemaString = "name age" // 以字符串的方式定义DataFrame的Schema信息 import org.apache.spark.sql.Row import org.apache.spark.sql.types.{StructType, StructField, StringType} // StructType类自定义Schema val schema = StructType(schemaString.split(" ").map(fieldName =>StructField(fieldName,StringType, true))) //类型是Arrayp[StructField] //Row类包装数据内容 val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim)) // 创建DF类,参数为Row类和StructType类 val peopleDataFrame = spark.createDataFrame(rowRDD, schema) // 将DataFrame注册成临时表 peopleDataFrame.registerTempTable("people") val results = spark.sql("SELECT name FROM people") results.show
———————————————————————————————————————————
4.常用操作
//引用select
ds.select("name")
ds.select(ds("name"))
ds.select(col("name"))
ds.select(column("name"))
ds.select('name')
ds.select($"name")
//统计指标
df.describe("colname").show()
//日期处理类(JAVA)
import java.time.LocalDate
import java.time.format.DateTimeFormatter
LocalDate.parse("2018-08-01 12:22:21", DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss")).getDayOfWeek
//包装这个JAVA方法为scala函数,方便使用
def TimeParse(x:String):String={
LocalDate.parse(x,DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss")).getDayOfWeek.toString
}
//join操作,列比较时使用三元符号===
val joined=orderDS.join(order_itemsDS,orderDS("id")===order_itemsDS("order_id"))
//常见操作
val df = spark.read.json("file:///home/hadoop/data/people.json")
// 使用printSchema方法输出DataFrame的Schema信息
df.printSchema()
// 使用select方法来选择我们所需要的字段
df.select("name").show()
// 使用select方法选择我们所需要的字段,并未age字段加1!!!!!!!!!!!!!!
df.select(df("name"), df("age") + 1).show()
// 使用filter方法完成条件过滤
df.filter(df("age") > 21).show()
// 使用groupBy方法进行分组,求分组后的总数
df.groupBy("age").count().show()
//sql()方法执行SQL查询操作
df.registerTempTable("people") //先要将df注册为临时表
spark.sql("SELECT * FROM people").show //直接在sql中查询注册的表
5、类型转换
read方法获得的字段都是String型,需进行类型转换
//1、单列转化方法
import org.apache.spark.sql.types._
val data = Array(("1", "2", "3", "4", "5"), ("6", "7", "8", "9", "10"))
val df = spark.createDataFrame(data).toDF("col1", "col2", "col3", "col4", "col5")
import org.apache.spark.sql.functions._
df.select(col("col1").cast(DoubleType)).show()
+----+
|col1|
+----+
| 1.0|
| 6.0|
+----+
//2、循环转变
//然后就想能不能用这个方法循环把每一列转成double,但没想到怎么实现,可以用withColumn循环实现。
val colNames = df.columns
var df1 = df
for (colName <- colNames) {
df1 = df1.withColumn(colName, col(colName).cast(DoubleType))
}
df1.show()
+----+----+----+----+----+
|col1|col2|col3|col4|col5|
+----+----+----+----+----+
| 1.0| 2.0| 3.0| 4.0| 5.0|
| 6.0| 7.0| 8.0| 9.0|10.0|
+----+----+----+----+----+
//3、通过:_*
//但是上面这个方法效率比较低,然后问了一下别人,发现scala 有array:_*这样传参这种语法,而df的select方法也支持这样传,于是最终可以按下面的这样写
val cols = df.columns.map(x => col(x).cast("Double"))
df.select(cols: _*).show()
+----+----+----+----+----+
|col1|col2|col3|col4|col5|
+----+----+----+----+----+
| 1.0| 2.0| 3.0| 4.0| 5.0|
| 6.0| 7.0| 8.0| 9.0|10.0|
+----+----+----+----+----+
//这样就可以很方便的查询指定多列和转变指定列的类型了:
val name = "col1,col3,col5"
df.select(name.split(",").map(name => col(name)): _*).show()
df.select(name.split(",").map(name => col(name).cast(DoubleType)): _*).show()
三、Spark外部数据源操作 (重点)
1.Parquet文件(默认文件)
一种流行的列式存储格式,以二进制存储,文件中包含数据与元数据 (ROW数据和Schema元数据)
import org.apache.spark.sql.types._
val schema=StructType(Array(StructField("name",StringType),
StructField("favorite_color",StringType),
StructField("favorite_numbers",ArrayType(IntegerType))))
val rdd=sc.parallelize(List(("Alyssa",null,Array(3,9,15,20)),("Ben","red",null)))
val rowRDD=rdd.map(p=>Row(p._1,p._2,p._3))
val df=spark.createDataFrame(rowRDD,schema)
val df=spark.read.parquet("/data/users/") //该目录下必须已存在parquet文件
df.write.parquet("/data/users_new/") //在该目录下生成parquet文件
——————————————————————————————————————————
2.Hive表
集成hive:
Spark SQL与Hive集成: hive打开元数据仓库的外部接口,spark连入该数据库,通过该元数据信息获取hive上的数据。其实与Hive的元数据管理相同。
测试环境集成(shell开发)
- 打开Hive的metastore服务
#hive打开元数据库的外部接口 9083
nohup hive --service metastore & #nohup 绑定系统,终端退出服务也会运行
- 进入Spark-shell 链接hive数据库
//Spark 链接到hive的元数据库
spark-shell --conf spark.hadoop.hive.metastore.uris=thrift://localhost:9083
//或者,自行建立session
val spark = SparkSession.builder()
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
//保存表到hive上
df.saveAsTable("tbl_name")
生成环境集成(IDE开发)
Spark SQL与Hive集成: 1、hive-site.xml拷贝至${SPARK_HOME}/conf下 2、追加内容
<property>
<name>hive.metastore.uris</name>
<value>thrift://master的IP:9083</value>
</property>
(可选,xml没有该配置会自动链接jdbc到mysql) 3、启动元数据服务:nohup hive --service metastore & 4、自行创建SparkSession,应用配置仓库地址与启用Hive支持
val spark = SparkSession.builder()
.config("spark.sql.warehouse.dir", warehouseLocation) //warehouse可选,默认在启动时的目录下
.enableHiveSupport()
.getOrCreate()
spark存储到hive
hive --service metastore
spark-shell
spark.sql("show tables").show
//或者
val df=spark.table("toronto") //返回的是DataFrame类
df.printSchema
df.show
df.write.saveAsTable("dbName.tblName")
//hive
select * from dbName.tblName;
———————————————————————————————————————————
3.MySQL表(MySQL)
RDBMS关系型数据库管理系统,集成与hive基本相同,但是没有通过hive的metastore服务,而是直接使用jdbc去链接mysql
spark-shell --driver-class-path /opt/hive/lib/mysql-connector-java-5.1.38.jar
val df=spark.read.format("jdbc").option("delimiter",",").option("header","true").option("url","jdbc:mysql://192.168.137.137:3306/test").option("dbtable","orders").option("user","root").option("password","rw").load()
//
$spark-shell --jars /opt/spark/ext_jars/mysql-connector-java-5.1.38.jar //使用jdbc的jar去连RDBMS
val url = "jdbc:mysql://localhost:3306/test" //test是一个数据库名
val tableName = "TBLS" //TBLS是库中的一个表名
// 设置连接用户、密码、数据库驱动类
val prop = new java.util.Properties
prop.setProperty("user","hive")
prop.setProperty("password","mypassword")
prop.setProperty("driver","com.mysql.jdbc.Driver")
// 取得该表数据
val jdbcDF = spark.read.jdbc(url,tableName,prop)
jdbcDF.show
//DF存为新的表
jdbcDF.write.mode("append").jdbc(url,"t1",prop)
四、Spark+SQL的函数
1.内置函数(org.apache.spark.sql.funtions.scala)
- 区分于scala的函数,spark的sql函数时针对表的列的。
- 内置函数是针对DataFrame的,并非hive的UDF
| 类别 | 函数举例 |
|---|---|
| 聚合函数 | countDistinct**、sumDistinct** |
| 集合函数 | sort_array**、explode** |
| 日期、时间函数 | hour**、quarter、next_day** |
| 数学函数 | asin**、atan、sqrt、tan、round** |
| 开窗函数 | row_number |
| 字符串函数 | concat**、format_number、regexp_extract** |
| 其他函数 | isNaN**、sha、randn、callUDF** |
2.自定义函数
-
定义函数
-
注册函数
- SparkSession.udf.register():只在sql()中有效 (spark的sql集成)
- functions.udf():对DataFrame API均有效 (spark基于RDD的数据库)
-
函数调用
//注册自定义函数,注意是匿名函数
spark.udf.register("hobby_num", (s: String) => s.split(',').size)
spark.sql("select name, hobbies, hobby_num(hobbies) as hobby_num from hobbies").show
五、Spark-SQL
因为招了好多Hive的研发人员,因此Spark-SQL的操作类似于hive
但是Spark-SQL基于的框架不是MR,因此速度相比非常快。
- Spark SQL CLI是在本地模式下使用Hive元存储服务和执行从命令行所输入查询语句的简便工具 注意,Spark SQL CLI无法与thrift JDBC服务器通信
- Spark SQL CLI等同于Hive CLI(old CLI)、Beeline CLI(new CLI)
- 启动Spark SQL CLI,请在Spark目录中运行以下内容
./bin/spark-sql
六、性能优化
1.序列化
-
Java序列化,Spark默认方式
-
Kryo序列化,比Java序列化快约10倍,但不支持所有可序列化类型
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); //向Kryo注册自定义类型 conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]));//case class如果没有注册需要序列化的class,Kyro依然可以照常工作,但会存储每个对象的全类名(full class name),这样往往比默认的 Java serialization 更浪费空间
2.注意事项
- 使用对象数组、原始类型代替Java、Scala集合类(如HashMap)
- 避免嵌套结构
- 尽量使用数字作为Key,而非字符串
- 以较大的RDD使用MEMORY_ONLY_SER
- 加载CSV、JSON时,仅加载所需字段
- 仅在需要时持久化中间结果(RDD/DS/DF)
- 避免不必要的中间结果(RDD/DS/DF)的生成
- DF更快,执行速度比DS快约3倍
- 自定义RDD分区与spark.default.parallelism,该参数用于设置每个stage的默认task数量
- 将大变量广播出去,而不是直接使用
- 尝试处理本地数据并最小化跨工作节点的数据传输
3.表连接(join操作)
- 包含所有表的谓词(predicate)
select * from t1 join t2 on t1.name = t2.full_name
where t1.name = 'mike' and t2.full_name = 'mike'
- 最大的表放在第一位
- 广播最小的表
- 最小化表join的数量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号