

我所理解的RESTful Web API [Web标准篇]【转】
原文:http://www.cnblogs.com/artech/p/restful-web-api-01.html
REST不是一个标准,而是一种软件应用架构风格。基于SOAP的Web服务采用RPC架构,如果说RPC是一种面向操作的架构风格,而REST则是一种面向资源的架构风格。REST是目前业界更为推崇的构建新一代Web服务(或者Web API)的架构风格。由于REST仅仅是一种价格风格,所以它是与具体的技术平台无关的,也就是说采用REST架构的应用未必一定建立在Web之上,所以在正式介绍REST之前,我们先来简单认识一下Web。
目录
一、TCP/IP与HTTP
二、Web资源
媒体类型
URI、URL和URN
三、HTTP事务
HTTP方法
响应状态码
四、HTTP报文
如果要问大家这样一个问题:“在过去半个世纪中,哪种信息技术对人类的影响最为深远?”,我想很多人的答案是Web(World Wide Web、WWW、W3或者万维网),因为它改变了我们的生活方式和思维方式。如果各位阅读过W3C介绍WWW的官方文档(“http://www.w3.org/WWW/”),应该对它的第一句话记忆犹新——“The World Wide Web (known as "WWW', "Web" or "W3") is the universe of network-accessible information, the embodiment of human knowledge”。如果将这句话翻译成简洁的中文,就是“Web是(网络)信息的来源,知识的化身”。
Web为我们提供了一种利用HTTP协议获取和操作网络资源的方式,这些将Web服务器作为宿主的资源不仅仅包含像文字和图片这些传统的信息载体,还包含音频和视频这些多媒体信息。Web的核心主要体现在三个方面,即HTTP、超文本(Hypertext)和超媒体(Hypermedia)[1],超文本和超媒体规范了网络信息的表现形式,而HTTP则提供了网络访问的标准协议。接下来我们就以围绕着HTTP对Web作一下基本的介绍。
一、TCP/IP与HTTP
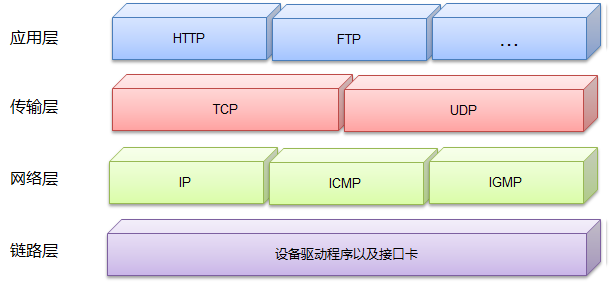
TCP/IP是以IP和TCP协议为核心的一整套网络协议的总称,所以有时候我们也称其为TCP/IP协议簇。毫不夸张地说,TCP/IP支撑着整个互联网,因为它就是互联网采用的网络协议。TCP/IP协议簇划分为如右图所示的4个层次[2](应用层、传输层、网络层和链路层),构成整个协议簇的各个子协议处于相应层次中。
既然将整个协议簇命名为TCP/IP,那么IP和TCP自然就是其中最为核心的两个协议了。处于网络层的IP协议提供的IP数据报传输是不可靠的,因为它只承诺尽可能地将数据报发送出去,但不能保证发送的数据报能够成功地抵达目的地。IP协议的不可靠性还体现在它不能检测数据在传输过程中是否发生了改变,也就是说数据的完整性得不到保证。IP协议是一个无连接(Connectionless)的网络协议,每次数据报的处理对它来说均是独立的,因此IP协议也不能提供针对有序传输(数据接收的顺序与发送的顺序一致)的保证。
虽然IP协议只能提供不可靠的数据传输,同时有序传输也得不到保证,但是建立在它之上的传输层协议TCP有效地解决了这两个问题。TCP是一个基于连接的协议,数据交换双方在进行报文传输之前需要建立连接,报文传输结束之后需要关闭连接。这是一个双工(Duplex)连接,数据交换的双工均可以利用它向对方发送数据。
TCP利用“接收确认”和“超时重传”机制确保了数据能够成功抵达目的地。具体来说,接收方在成功接收到数据之后会回复一个确认消息。发送方在本地具有一个存放尚未得到确认的已发消息的缓冲区,如果发送方在一个设定的时限内没有接收到针对某个已发报文的确认消息,它会从该缓存区中选择对应的报文进行重新发送。在接收到确认之后,相应的报文会从缓存区中移除。
为了解决有序传输的问题,发送方会为每个报文进行编号,报文的序号体现了它们被发送的顺序。接收端在接收到某个报文之后,它会利用此序号判断是否具有尚未成功接收的已发报文,如果有的话,该报文会被存放到本地的缓冲区中。等到之前发送的报文全部被接收之后,接收方按照序号对接收的报文依次向上(应用层)递交,成功递交的报文会被从缓存区中移除。除了接收到“失序”的报文之外,接收方还有可能接收到重复的报文,因为没有报文均具有一个唯一的序号,如果该序号小于已经成功递交或者添加到缓存区中的报文序号,它会被认为是重复接收的报文而被丢弃。
由于每个TCP报文段都具有一个16位的检验和(Checksum),所以接收方可以根据它确认数据在传输过程中是否被篡改。除此之外,TCP还提供了“流量控制”功能避免了双方因缓存区大小不一致而导致报文丢失。具体来说,如果发送方的缓冲区大于接收方的缓存区,会导致接收方在缓冲区已满的情况下无法处理后续接收的报文,所以接收方会将自己缓存区剩余的大小及时通知给发送端,后者据此控制报文发送“流量”。
HTTP(Hypertext Transfer Protocol),全称为“超文本传输协议”,是TCP/IP协议簇的一部分。从图1-1可以看出,这是一个位于应用层的网络协议,在它之下的就是TCP协议。由于TCP协议是一个“可靠”的协议,HTTP自然也能提供可靠数据传输功能。
IP协议利用IP地址来定位数据报发送的目的地,而利用域名系统(DNS)可以实现域名与IP地址之间的转换。TCP协议利用端口号标识应用程序,所以某个应用程序在使用TCP协议进行通信的时候必须指定目标应用的IP地址(或者域名)和端口号。HTTP默认采用的端口号为80,而HTTPS(利用TLS/SSL为HTTP提供传输安全保障)的默认端口号则为443,当然在网络可达的前提下,我们可以指定任意的端口。
二、Web资源
这里所说的资源是一个宽泛的概念,任何寄宿于Web服务器可以利用HTTP协议获取或者操作的“事物”均可以称为资源。这也是一个抽象的概念,不仅仅是寄宿于Web服务器的某个静态物理文件可以视为Web资源,通过Web应用根据请求动态生成的数据也是Web资源。
媒体类型
资源实际上是一种承载着某种信息的数据,相同的信息可以采用不同形态的数据来展现,数据的“形态”主要体现为展示数据所采用的格式,比如一个数据对象可以通过XML格式来表示,也可以通过JSON格式来表示。数据的处理必须依赖于一种已知的格式,所以将Web资源的形态以一种标准化的方式固定下来显得尤为重要,这就是我们接下来着重介绍的媒体媒体(Media Type)。
不论是通过HTTP请求从Web服务器上获取资源,还是利用请求向服务器提交资源,响应或者请求的主体(Body)除了包含承载资源本身的数据之外,其报头(Header)部分还应该包含表示数据形态的媒体类型。
媒体类型又被称为MIME(Multipurpose Internet Mail Extension)类型,MIME是一个互联网标准,它扩展了电子邮件标准,使其能够支持非ASCII字符、二进制格式附件等多种格式的邮件消息。由于MIME在电子邮件系统应用得非常好,所以被HTTP用于描述并标记多媒体内容。下面的列表给出了一种常用的媒体类型。
- text/html:HTML格式的文档。
- text/xml(application/xml):XML格式的文本。
- text/json(application/json): JSON格式的文本。
- image/gif(image/jpeg、image/png):GIF(JPEG、PNG)格式的图片。
- audio/mp4(audio/mpeg、audio/vnd.wave):MP4(MPEG、WAVE)格式的音频文件。
- video/mp4(video/mpeg、video/quicktime):MP4(MPEG、QUICKTIME)格式的视频文件。
URI、URL和URN
可操作的Web资源应该具有一个 唯一的标识。虽然具有很多唯一性标志符的种类可供选择(比如GUID),但是采用URI来标识Web资源已经成为了一种共识,实际上URI的全称为“统一资源标志符(Uniform Resource Identifier)”。
我想有很多人弄不清楚URI和URL之间的区别,有人甚至觉得这是同一概念的不同表述而已。一个URL肯定是一个URI,但是一个URI并不一定是一个URL,URL仅仅是URI的一种表现形式而已。两者的差异其实可以直接从其命名来区分,URI是Web资源的标志符,所以只要求它具有“标识性”即可;URL全称为“统一资源定位符(Uniform Resource Locator)”,所以除了标识性之外,它还具有定位的功能,用于描述Web资源所在的位置。
URL不仅仅用于定位目标资源所在的位置,还指名了获取资源所采用的协议,一个完整的URL包含协议名称、主机名称(IP地址或者域名)、端口号、路径和查询字符串5个部分。比如对于“ http://www.artech.com:8080/images/photo.png?size=small”这样一个URL,上述的5个部分分别是“http”、“www.artech.com”、“8080”、“/images/photo.png”和“?size=small”。
除了URL,URN也是URI的一种表现形式,URN全称“统一资源定位符(Uniform Resource Name)”。URN与资源所在的位置无关,倘若采用URN来唯一标识某个资源,在位置发生改变的时候标志符依然可以保持不变。URN一般也不会涉及到获取被标识资源采用的网络协议,所以不需要为利用不同协议访问的相同资源定义不同的标志符。
三、HTTP事务
虽然TCP是一种基于连接的传输层协议,并且保存双方针对同一个连接的多轮消息交换的会话状态,但是建立其上的HTTP则是一种无状态的网络协议。HTTP采用简单的“请求/响应”消息交换模式,一次HTTP事务(Transaction)始于请求的发送,止于响应的接收。针对客户端和Web服务器的多次消息交换来说,每个HTTP事务均是相互独立的。
HTTP方法
HTTP采用简单的请求/响应模式的消息交换旨在实现针对某个Web资源的某种操作。至于针对资源的操作类型,不外乎CRUD(Create、Retrieve、Update和Delete)而已。一个HTTP请求除了利用URI标志目标资源之外,还需要通过HTTP方法(HTTP Method或者HTTP Verb)指名针对资源的操作类型。我们常用的HTTP方法 包括GET、POST、PUT、DELETE、HEAD、OPTIONS、TRACE、CONNECTION和PATCH等,我们将在《设计篇》以REST的视角来对它们进行详细介绍。
响应状态码
针对客户端向Web服务器发送的任意一个HTTP请求,不论在何种情况下得到一个响应,每个响应均具有一个由3位数字表示的状态码和相应的描述文字。不同数值的状态码体现了不同类型的响应状态,W3C对响应状态码的范围作了如下的规范。
- 100~199:信息状态码,代表请求已被接受,需要继续处理。
- 200~299:成功状态码,代表请求已成功被服务器接收、理解、并接受。
- 300~399:重定向状态码,代表需要客户端采取进一步的操作才能完成请求。
- 400~499:客户端错误状态码,代表了客户端看起来可能发生了错误,妨碍了服务器的处理。
- 500~599:服务器错误状态码,代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。
四、HTTP报文
客户端和Web服务器在一次HTTP事务中交换的消息被称为HTTP报头,客户端发送给服务器的请求消息被称为请求报文,服务器返回给客户端的响应消息被称为响应报头。请求报文和响应报头采用纯文本编码,由一行行简单的字符串组成。一个完整的HTTP报文由如下三个部分构成。
- 起始行:代表HTTP报文的第一行文字,请求报文利用起始行表示采用的HTTP方法、请求URI和采用的HTTP版本,而响应报文的起始行在承载着HTTP版本和响应状态码等信息。
- 报头集合:HTTP报文的起始行后面可以包含零个或者多个报头字段。每个报头表现为一个键/值对,键和值分别表示报头名称和报头的值,两者通过冒号(“:”)进行分割。HTTP报文采用一个空行作为报头集合结束的标志。
- 主体内容:代表报头集合结束标志的空行之后就是HTTP报文的主体部分了。客户端提交给服务器的数据一般置于请求报头的主体,而响应报头的主体也承载着服务器返回给客户端的数据。不论是请求报文还是响应报文,其主体部分均是可以缺省的。
接下来我们看看一个具体HTTP报文具有怎样的结构。下面这个文本片段反映的是我们通过Chrome浏览器访问微软的官网(www.microsoft. com)对应的HTTP请求,起始行体现了HTTP请求的三个基本属性,即HTTP方法(GET)、目标资源(http://www.microsoft.com/en-us/default.aspx)和协议版本(HTTP/1.1)。
1: GET http://www.microsoft.com/en-us/default.aspx HTTP/1.1
2: Host: www.microsoft.com
3: Connection: keep-alive
4: Cache-Control: max-age=0
5: User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.75 Safari/535.7
6: Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
7: Accept-Encoding: gzip,deflate,sdch
8: Accept-Language: en-US,en;q=0.8
9: Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
10: Cookie: ...
上述这个请求报文不具有主体,所以起始行之外的所有内容均为报头集合,我们们可以根据这些报头获得主机名称、采用的缓存策略、浏览器相关信息、以及客户端支持的媒体类型(Media Type)、编码方式、语言和字符集等。
前面的HTTP请求通过浏览器发送给服务端之后会接收到具有如下结构的响应报文,我们可以此从它的起始行得到采用的HTTP版本(HTTP/1.1)和响应状态码(“200 OK”,表示请求被正常接收处理)。响应的内容被封装到响应报文的主体部分,其媒体类型的通过报头“Content-Type”表示。由于该响应报文的主体内容是一个HTML文档,所以“Content-Type”报头表示的媒体类型为“text/html”。
1: HTTP/1.1 200 OK
2: Cache-Control: no-cache
3: Pragma: no-cache
4: Content-Type: text/html; charset=utf-8
5: Content-Encoding: gzip
6: Expires: -1
7: Vary: Accept-Encoding
8: Server: Microsoft-IIS/7.5
9: X-AspNet-Version: 2.0.50727
10: VTag: 791897542300000000
11: P3P: CP="ALL IND DSP COR ADM CONo CUR CUSo IVAo IVDo PSA PSD TAI TELo OUR SAMo CNT COM INT NAV ONL PHY PRE PUR UNI"
12: X-Powered-By: ASP.NET
13: Date: Wed, 18 Jan 2012 07:06:25 GMT
14: Content-Length: 34237
15:
16: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
17: <html>…</html>
[1]超文本/超媒体(HyperText/HyperMedia):超文本是一份呈现文本内容的电子文档,其核心在于可以利用内嵌的“超链接(Hyperlink)”直接访问引用的另一份文档。超媒体对超文本作了简单的扩展以呈现多媒体内容(比如图片、音频和视频等)。HTML文档是我们常见的最为典型的超文本/超媒体文件。
[2] 除了采用这种4个层次的划分方法之外,还具有另外两种典型的划分方式。其中一种在链路层下面添加一个基于物理网络硬件的物理层,这种划分方法与此没有本质的区别。另外一种则是将TCP/IP协议簇划分为包括应用层、表示层、会话层、传输层、网络层、链路层和物理层在内的7个层次。
参考资料:
[1] 《HTTP: The Definitive Guide》, By By David Gourley, Brian Totty, Marjorie Sayer, Anshu Aggarwal, Sailu Reddy
[2] 《RESTful Web Services》, RESTful Web Services
[3] 《A Brief Introduction to REST》,http://www.infoq.com/articles/rest-introduction
[4] 《TCP/IP Illustrated (Volumn 1: The Protocol)》, by W. Richard Stevens

