怎么通过CSS选择器采集网页数据
做了个数据采集插件准备拿博客园练练手。想一下要采集什么数据,就从首页文章列表采集起到第10页就结束采集,然后在点击进去采集文章内容。
视频演示地址:https://www.bilibili.com/video/BV1HP4y157rR
数据采集工具
九头虫网页数据采集插件 大家如果也想试下,那么可以点击进去下载。
九头虫网页数据采集插件 帮助文档
采集内容
首页:文章标题、文章介绍、作者、作者头像、点赞数、评论数、发布时间
内容页:正文内容
编写首页列表采集规则
按F12打开开发者工具里面看到文章列表HTML代码结构:
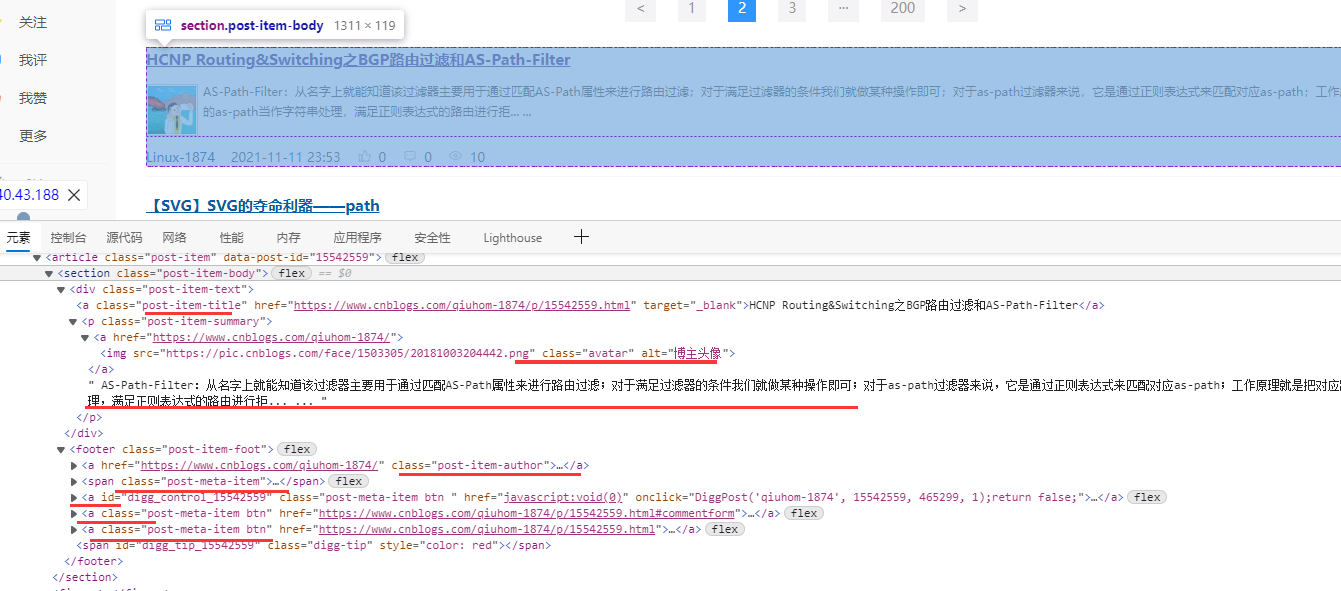
文章标题可以通过CSS选择器.post-item-title获取到;
文章地址可以通过CSS选择器.post-item-title获取到;
文章介绍可以通过CSS选择器.post-item-summary获取到;
作者可以通过CSS选择器.post-item-author获取到;
用户头像可以通过CSS选择器img.avatar获取到;
点赞数可以通过CSS选择器.post-item-foot a.post-meta-item获取到;
评论数可以通过CSS选择器.post-item-foot a[class*=post-meta-item]:nth-of-type(3)获取到;
浏览数可以通过CSS选择器.post-item-foot a[class*=post-meta-item]:nth-of-type(4) span获取到;
那么现在开始编写采集规则,采集规则保存之后,进入页面检验当前是否采集到数据了。
{
"title": "博客园首页文章列表",
"match": "https://www.cnblogs.com/*",
"demo": "https://www.cnblogs.com/#p2",
"delay": 2,
"rules": [
{
"root": "#post_list .post-item",
"multi": true,
"desc": "文章列表",
"fetches": [
{
"name": "文章标题",
"selector": ".post-item-title"
},
{
"name": "文章地址",
"selector": ".post-item-title",
"type": "attr",
"attr": "href"
},
{
"name": "文章介绍",
"selector": ".post-item-summary"
},
{
"name": "作者",
"selector": ".post-item-author"
},
{
"name": "头像",
"selector": "img.avatar",
"type": "attr",
"attr": "src"
},
{
"name": "点赞数",
"selector": ".post-item-foot a.post-meta-item"
},
{
"name": "评论数",
"selector": ".post-item-foot a[class*=post-meta-item]:nth-of-type(3)"
},
{
"name": "浏览数",
"selector": ".post-item-foot a[class*=post-meta-item]:nth-of-type(4)"
}
]
}
]
}

编写内容页采集规则
编写方式与上面的一样,这里就直接贴出代码了。
{
"title": "博客园文章内容",
"match": "https://www.cnblogs.com/*/p/*.html",
"demo": "https://www.cnblogs.com/bianchengyouliao/p/15541078.html",
"delay": 2,
"rules": [
{
"multi": false,
"desc": "文章内容",
"fetches": [
{
"name": "文章标题",
"selector": "#cb_post_title_url"
},
{
"name": "正文内容",
"selector": "#cnblogs_post_body",
"type": "html"
}
]
}
]
}
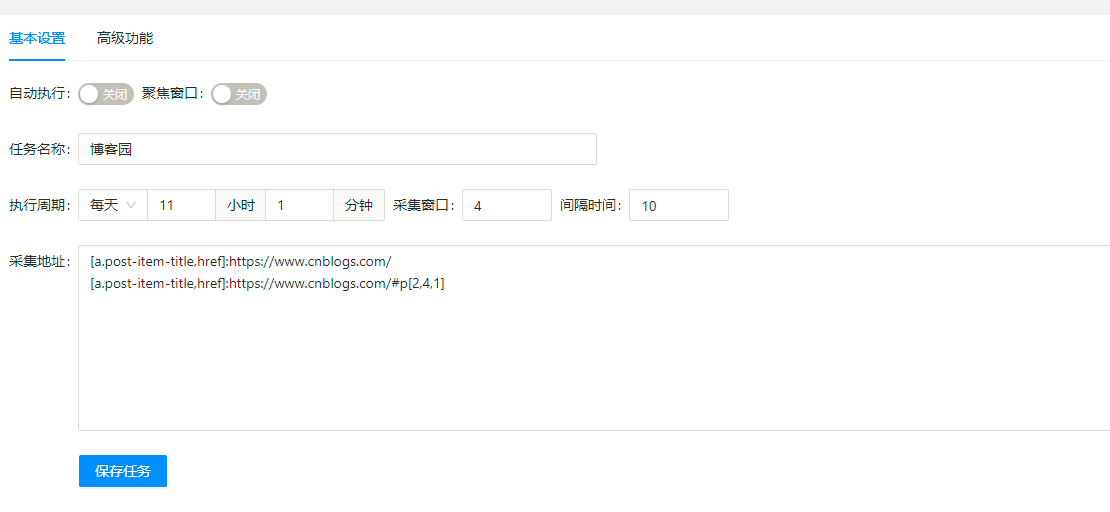
添加计划任务(实现批量采集、翻页采集)
在计划任务中,通过动态URL采集地址获取要采集的文章页面地址,获取完成之后插件就会自动去打开对应页面。只要打开页面,插件就会去匹配采集规则然后采集数据。
https://www.cnblogs.com/
[a.post-item-title,href]:https://www.cnblogs.com/#p[2,10,1]
预览数据


 浙公网安备 33010602011771号
浙公网安备 33010602011771号