

浅谈NVMe的多队列技术和IO调度
在NVMe标准中的诸多技术中,多队列技术是其中一个重要的提高性能的方法。借助于多队列技术,NVMe实现了按照任务、调度优先级和CPU的核来分配不同队列,完成高性能的存储功能。
每个队列是一个先进先出的FIFO管道,用于连通主机端(Host)和设备端(Device)。其中从主机端发送到设备端的命令管道称之为发送队列;从设备端发送到主机端的命令完成管道称之为完成队列。对于一个IO请求,在主机端组装完成后,通过发送队列发到设备端,然后在设备中进行处理并把相应的完成结果组装成IO完成请求,最后通过完成队列返还给主机端。
不管是发送队列还是完成队列,都是一段内存,通常位于主机端的DDR空间里。这段内存划分成若干等长的内存块,每一块用于存储一个定常的消息(NVMe的发送消息和完成消息都是定常的)。在使用的时候,对于这个队列,有一个头指针和一个尾指针。当两者相等时,队列是空的。见下图。
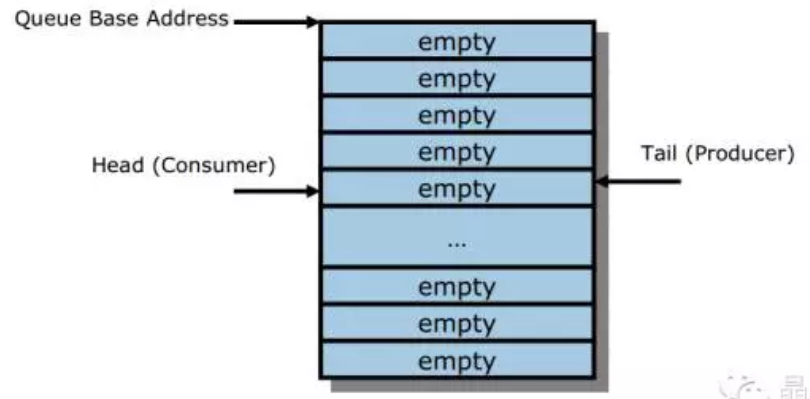
随着新的消息加入到队列中来,尾指针不停向前移动。因为内存是定常的,因此指针一旦移动到队内存的最后一个存储空间,之后再移动的话需要环回到内存的起始位置。因此内存在使用上实际上当作一个环来循环使用。当尾指针的下一个指针就是头指针的时候,这个队列不能再接收新的消息,即队列已经满了,如下图所示。
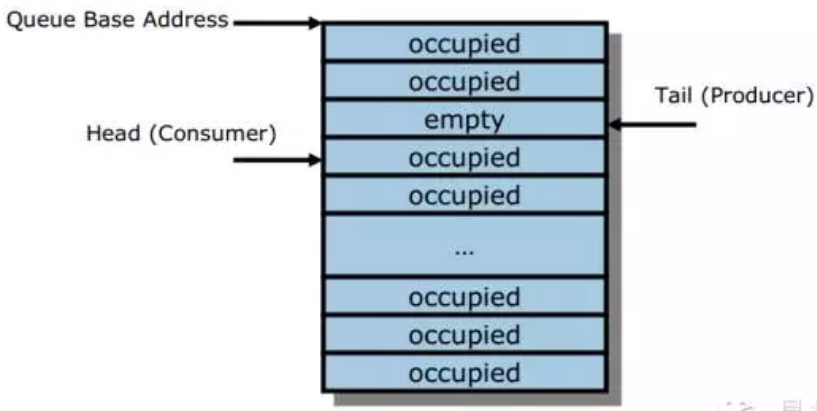
随着队列的使用者不断取出消息并修改头指针,队列中的元素不断释放,一直到头指针再次追上尾指针时,队列完全变空。
那么主机端将数据写入队列后,设备端是怎么知道该队列所在的内存已经更新了呢?这就需要利用门铃机制(Doorbell)。每个队列都有一个门铃指针。对于发送队列来说,这个指针表示的是发送队列的尾指针。主机端将数据写入到发送队列后,更新映射到位于设备寄存器空间中的门铃的尾指针。实现在SoC控制器芯片上的尾指针一旦被更新,设备就知道新数据到了。这里并未涉及到主机端如何知道数据已经取走并且设备已经更新了头指针了。NVMe协议并没有采用传统的查询寄存器的方式来让主机获得这个信息,因为这样势必造成CPU与硬件寄存器的交互。对于x86来说,每一次与硬件的交互都会带来性能的损失,因此降低硬件交互尤为重要。NVMe的方案是对于这个发送消息,在当它完成的时候会将完成的结果通过DMA的方式写入到内存中,主机根据每个IO请求及其完成请求中的CommandIdentifier (CID)字段来匹配相应的发送请求和完成请求。其中完成结果中携带有信息表明最新的该请求所对应的发送队列的当前头指针。
反过来,当设备端完成一个NVMe请求时,也需要通过完成队列来把完成的结果告知主机端,这是通过完成队列来实现的。与发送队列不同,完成队列是通过中断机制(INTx,MSI或MSIx)告诉接收端(主机CPU)收到了新的完成消息并安排后续处理。其中MSI和MSIx因为可以关联到具体的CPU核,所以通常建议使用MSI或MSIx类型的中断,并将中断关联到每一个完成队列。这样当中断产生的时候,根据中断向量可以确定是哪一个完成队列有新的完成消息。同样的,为了确定完成队列里到底有多少是新的完成消息,在每一个完成请求中,有一个标志位PhaseTag,这个标志位每次写入的数值都会发生改变,并据此确定每一个完成请求是否是新的完成请求。通过这种机制,虽然主机端不能一下子确定到底有多少新的完成请求,但是可以逐渐的、一步步完成所有的完成请求,并将完成队列用空。随着主机逐渐从完成队列里取出完成消息,主机会更新位于设备上的完成队列头指针寄存器,告诉设备完成队列的实施状况。
在最新的NVMe1.2A中,每一个NVMeController允许最多65535个IO队列和一个Admin队列。Admin队列在设备初始化之后随即创建,包括一个发送队列和一个完成队列。其他的IO队列则是由Admin队列中发送的控制命令来产生的。NVMe规定的IO队列的关系比较灵活,既可以一个发送队列对应一个完成队列,也可以几个发送队列共同对应一个完成队列。在主流的实现中,较多采用了一对一的方式。下图列举了两种方式的示意:

为了更好的说明这种设计如何被使用,我们拿NVMe Linux inbox driver作为一个例子来分析一下。这个驱动程序在内核版本3.3(RHEL7)中加入,最新的代码支持NVMe 1.0c。主要的代码位于/drivers/nvme/host/目录下。
在pci.c中,nvme_setup_io_queues负责初始化队列,它先查询了到底有多少个CPU,然后再调用nvme_set_queue_count发命令给设备,让设备按照CPU的个数来设置队列的个数。
在nvme_set_queue_count中,按照之前传入的CPU数量来设置设备的能力。其中NVME_FEAT_NUM_QUEUES对应于NVMe协议的Number of Queues (Feature Identifier 07h)。当然,根据设备能力不同,如果不巧设备刚好没办法支持这么多队列的话,驱动程序也会做一些取舍,选取设备的能力和CPU数量中较小的值。

之所以驱动程序主动去申请队列数量,而不是在NVMe Create Queue时逐个获得队列资源,主要是出于虚拟化的考虑(包括NVMf)。在虚拟化环境中,每个虚机所使用的队列资源在整个设备中是共享的,因此在Set Feature时设置有利于设备优化资源使用。
随后,在MQ初始化的地方,将MQ的数量设置为NVMe队列的数量。并且把每一个IO queue关联到一个NVMe队列上下文。
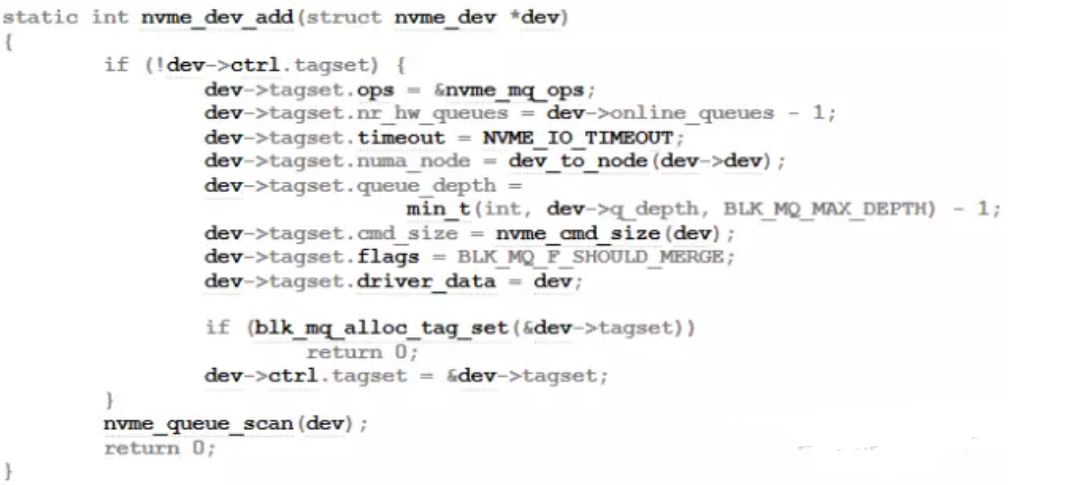
借助于Linux MQ,最终实现的效果是每一个CPU尽可能关联到一个独立的NVMe队列,从而实现操作IO时CPU之间不需要相互通信。因为每一个NVMe队列对应的中断也是独立的,因此从发送命令一直到接收请求的执行结果,全面实现了CPU之间的隔离,避免了锁带来的开销。
NVMe对于使用不同的队列还定义了调度策略,用于区分不同优先级的任务。其中Admin队列的优先级是最高的,IO队列可以定义绝对的优先级或Weighted round robin(WRR)的调度策略。Intel最新发布的DC P3700 SSD包括了这个功能,先于主流的驱动程序支持WRR。

从生态系统的反馈来看,目前这个功能在使用上还有一定障碍。一方面从刚才的Linux源生驱动来看,MQ保证了每个CPU独占一个队列。但是如果支持按照队列的优先级来进行调度的话,则是需要按照应用层面的任务来划分队列,这两个需求是矛盾的;另一方面,无论是绝对的优先级,还是WRR都不是符合使用者直觉特别是DBA使用习惯的方式。因此这一块后续的发展还需要NVMe组织和生态圈的共同努力。
[1] NVM Express Revision 1.2a


