


作业4报告
一、作业①:爬取股票数据信息并存储到MySQL
1. 作业目标
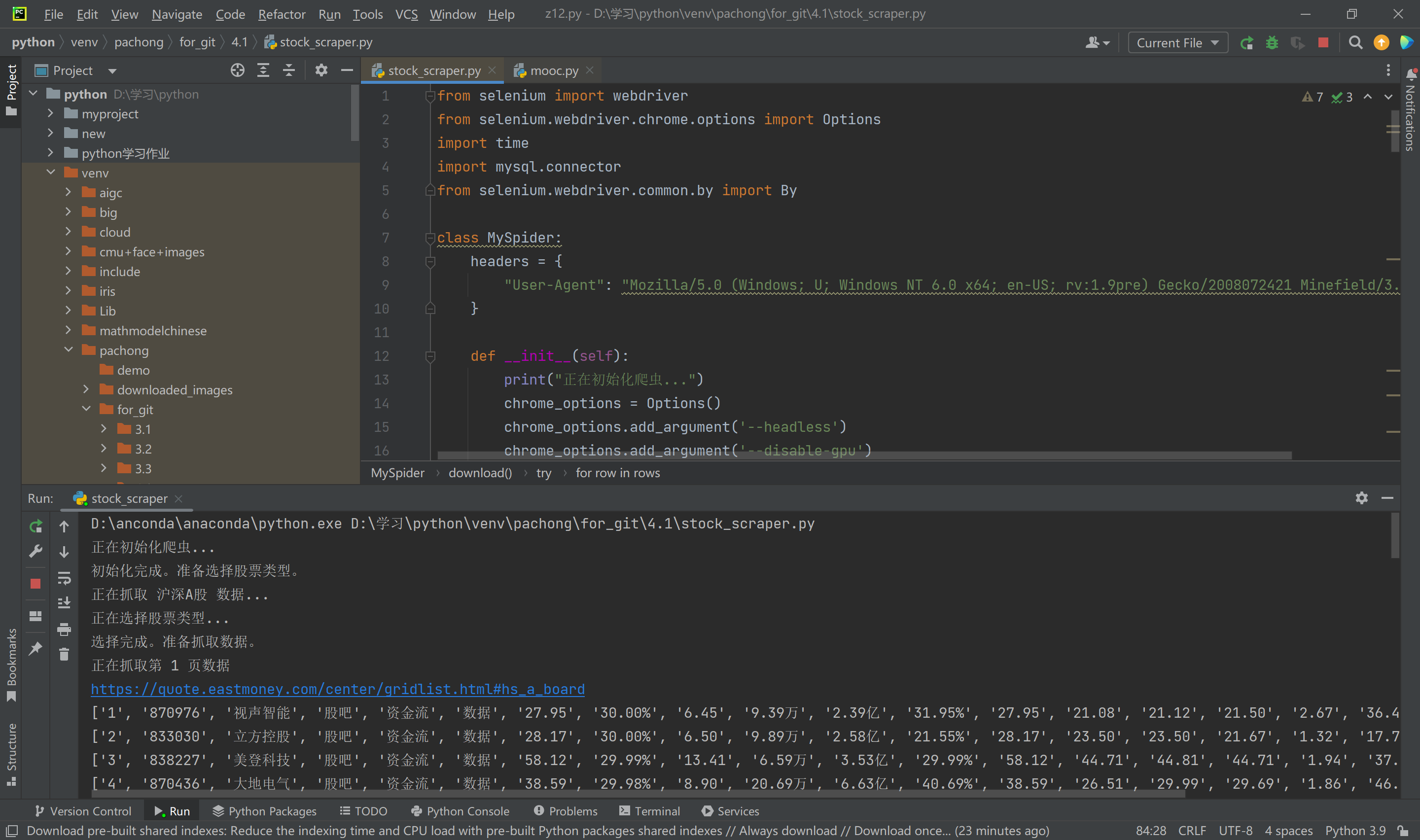
通过使用 Selenium 框架与 MySQL 数据库,爬取“沪深A股”、“上证A股”、“深证A股”三个板块的股票数据。熟悉 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等操作。
2. 实现步骤
- 配置 Selenium 和 WebDriver,打开目标网站 东方财富网。
- 使用 Selenium 查找网页元素,模拟点击加载更多股票数据。
- 提取页面中的股票数据。
- 将数据存储到 MySQL 数据库中。
- 验证数据存储并输出结果。
3. 代码实现
https://gitee.com/wang-hengjie-100/crawl_project/tree/master/4.1
结果展示:
作业心得
通过本作业,了解了如何使用 Selenium 爬取动态网页数据,尤其是 Ajax 请求的处理方式。
在实际操作中掌握了数据存储到 MySQL 数据库的步骤。
作业②:爬取中国mooc网课程资源信息并存储到MySQL
- 作业目标 通过使用 Selenium 框架爬取中国 MOOC 网站(icourse163)的课程信息,包括课程号、课程名称、学校名称、主讲教师等。
- 实现步骤 - 模拟用户登录,进入课程列表页面。 - 使用 Selenium 定位并点击加载更多按钮,爬取课程数据。 - 提取课程相关信息并存储到 MySQL 数据库。 - 验证数据存储并输出结果。
- 代码实现
https://gitee.com/wang-hengjie-100/crawl_project/tree/master/4.2
结果展示
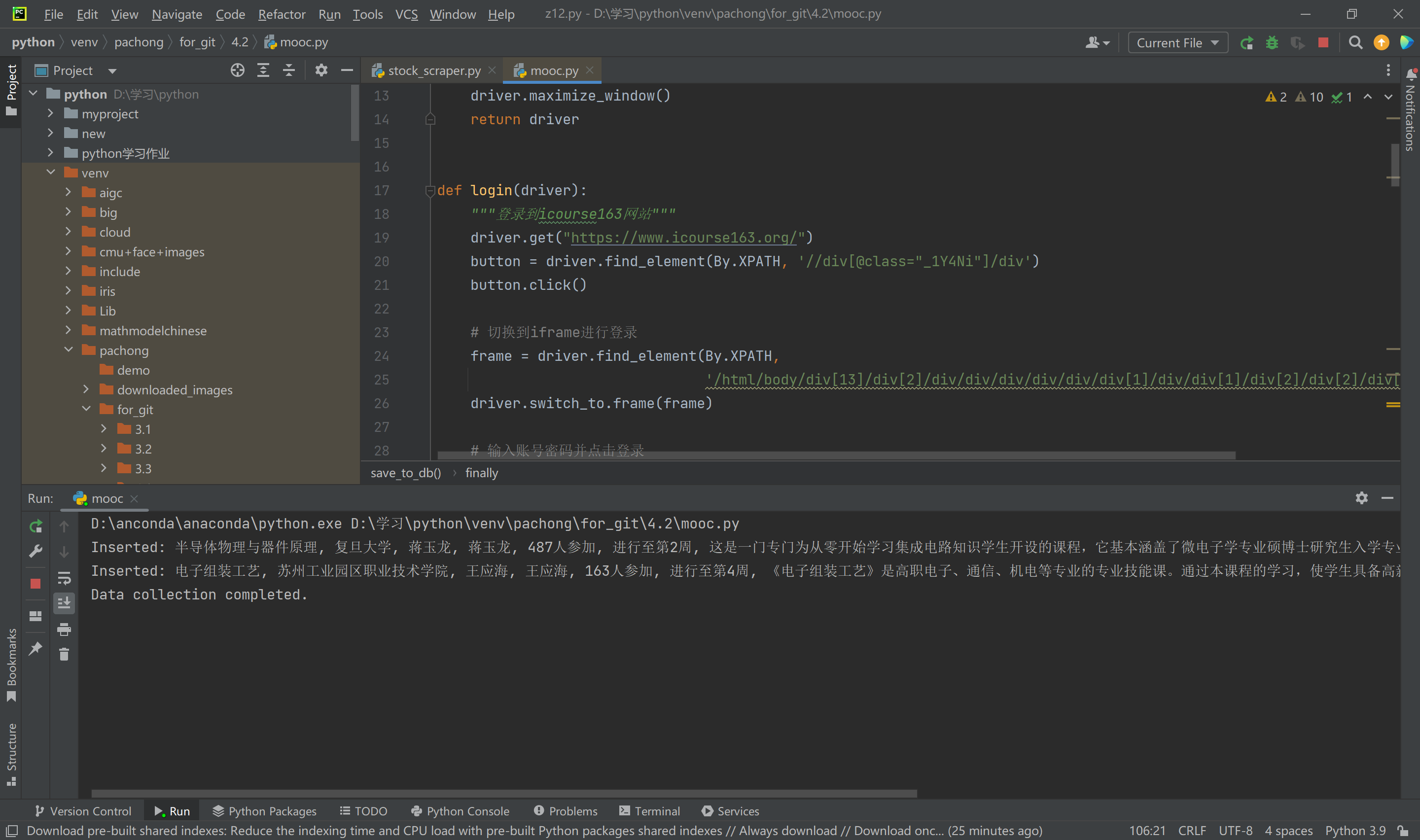
作业心得
在爬取中国 MOOC 网的过程中,学会了如何模拟用户登录,获取动态加载的课程数据。
熟悉了 Selenium 中的等待策略,以及如何与 MySQL 数据库进行交互。
通过本作业掌握了如何将爬取的多种信息存储到关系型数据库中,便于后期的数据分析与使用。
作业③:大数据相关服务与Xshell使用
1. 作业目标
完成大数据相关服务的配置与操作,包括 MapReduce、Kafka 和 Flume 等。通过实验熟悉 Xshell 使用及大数据的实时分析与处理。
2. 实验步骤
- 开通 MapReduce 服务并运行任务。
- 使用 Python 生成测试数据。
- 配置 Kafka 服务并进行数据流转。
- 安装 Flume 客户端并配置数据采集。
3. 结果展示
作业心得
- 通过本作业掌握了大数据相关服务的配置与使用,尤其是实时数据采集与流转。
- 学会了通过 Xshell 远程操作,熟悉了数据分析任务的部署与调试。
- 在实际操作中,通过配置 Kafka 和 Flume,解决了大规模数据流转和采集的问题,为进一步的分析处理奠定了基础。
 posted on
posted on

