


第三次实践报告
| 这个作业属于哪个课程 | <首页 - 2024数据采集与融合技术实践 - 福州大学 - 班级博客 - 博客园 (cnblogs.com)> |
|---|---|
| 这个作业要求在哪里 | <作业3 - 作业 - 2024数据采集与融合技术实践 - 班级博客 - 博客园 (cnblogs.com)> |
| 学号 | <102202104> |
作业①:爬取图片并保存到本地
作业代码与输出
使用Scrapy框架爬取了中国气象网(http://www.weather.com.cn)中的图片,分别实现了单线程和多线程的方式。控制了总页数(学号尾数2位)和总下载图片数量(尾数后3位)。
截图:
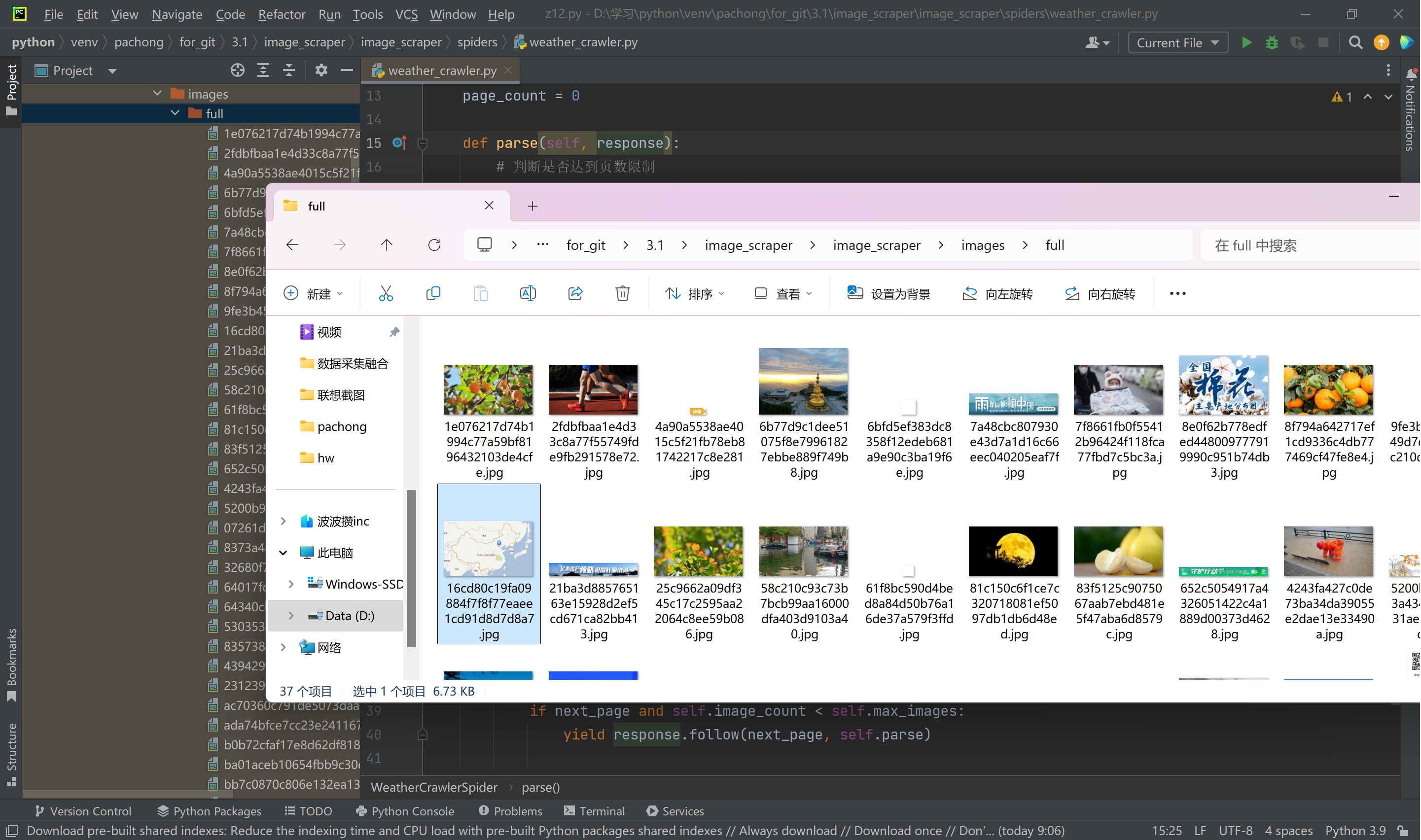
Gitee文件夹链接:https://gitee.com/wang-hengjie-100/crawl_project
作业②:爬取股票信息并存储到MySQL数据库
使用Scrapy框架和Xpath,爬取了东方财富网(https://www.eastmoney.com/ )的股票相关信息,并将数据存储到MySQL数据库中。包含字段如股票代码、股票名称、最新报价、涨跌幅等。
截图:
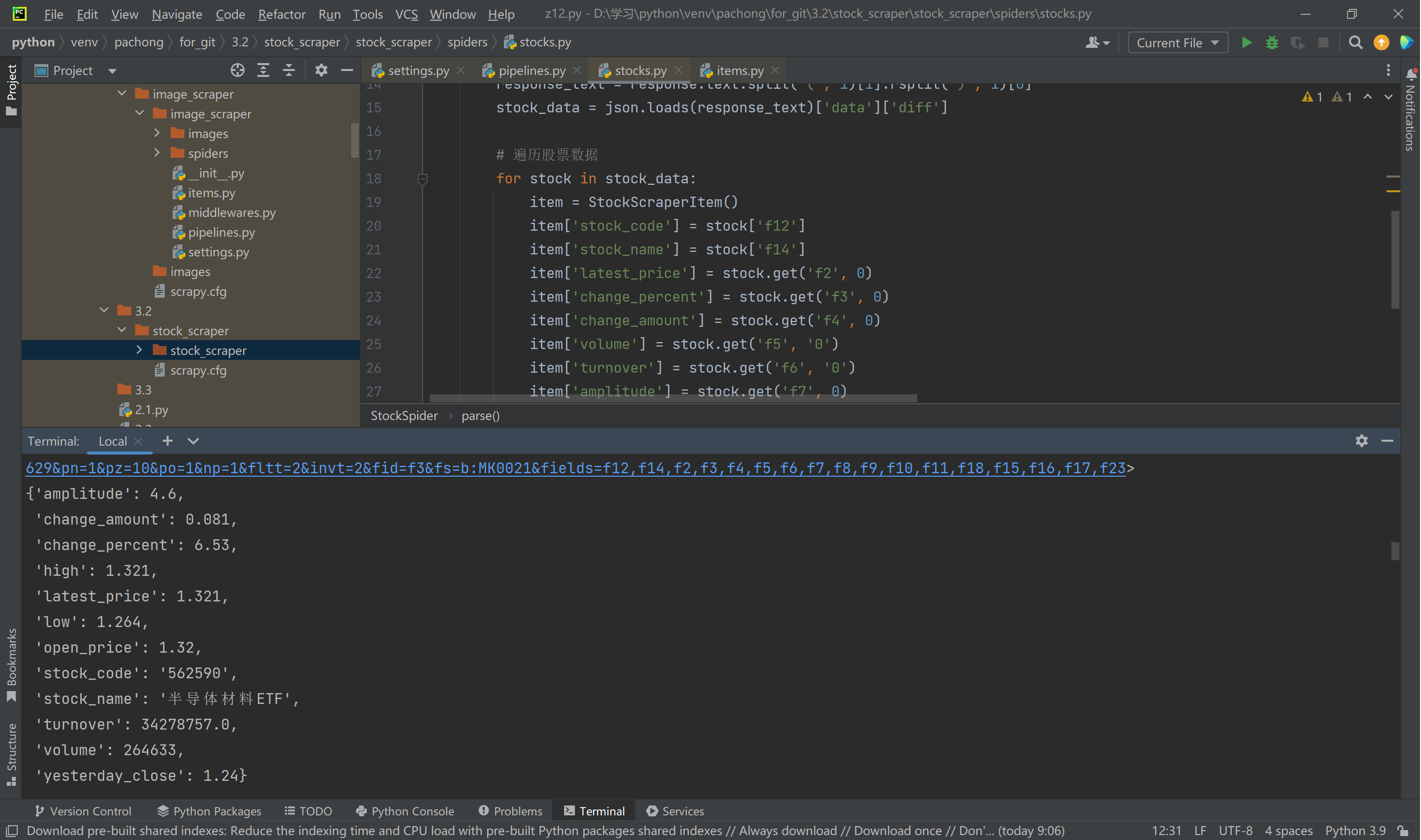
Gitee文件夹链接:https://gitee.com/wang-hengjie-100/crawl_project
作业③:爬取外汇数据并存储到MySQL数据库
爬取中国银行网(https://www.boc.cn/sourcedb/whpj/)上的外汇数据并存储到MySQL数据库,包含汇买价、汇卖价、银行买卖价等信息。
截图:
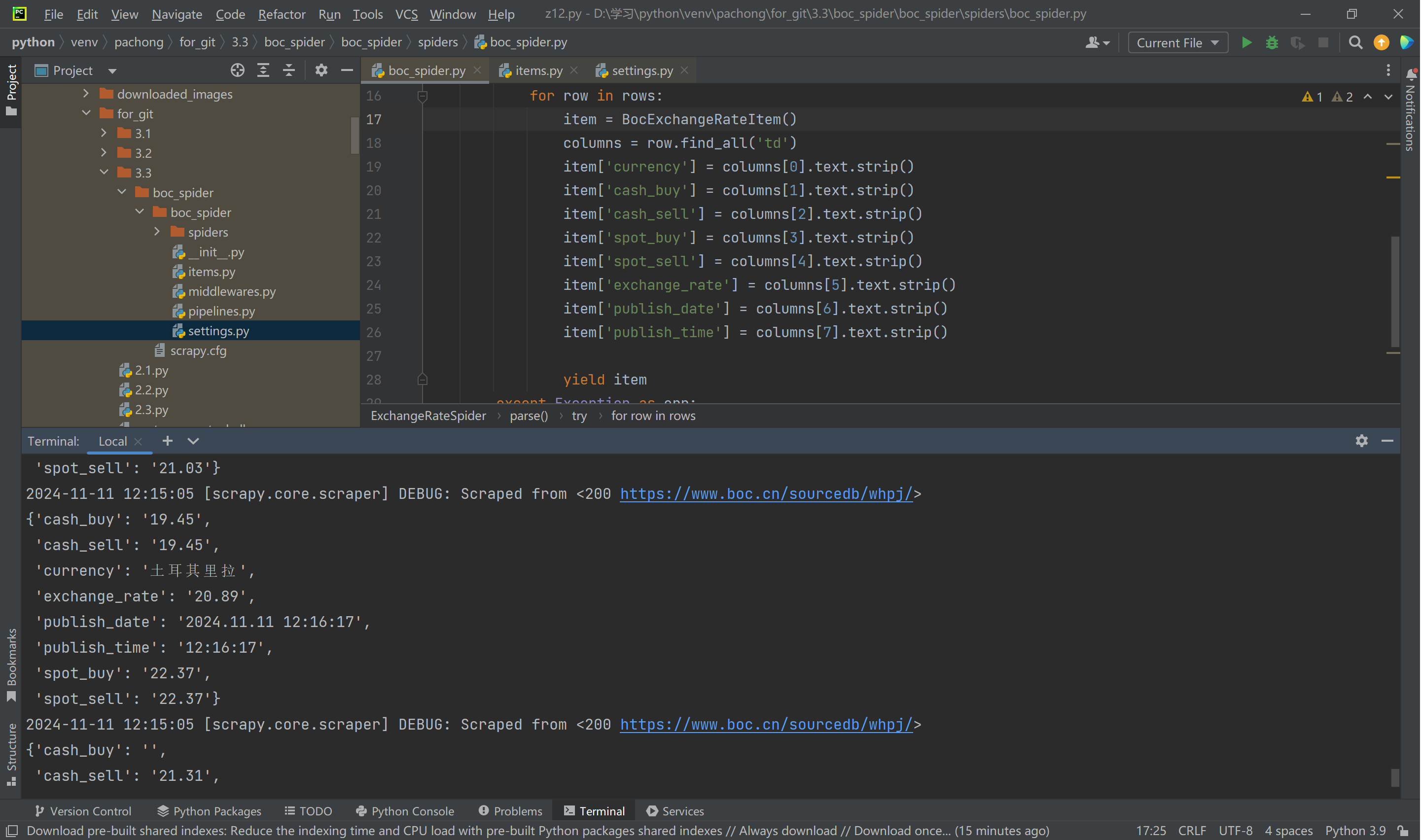
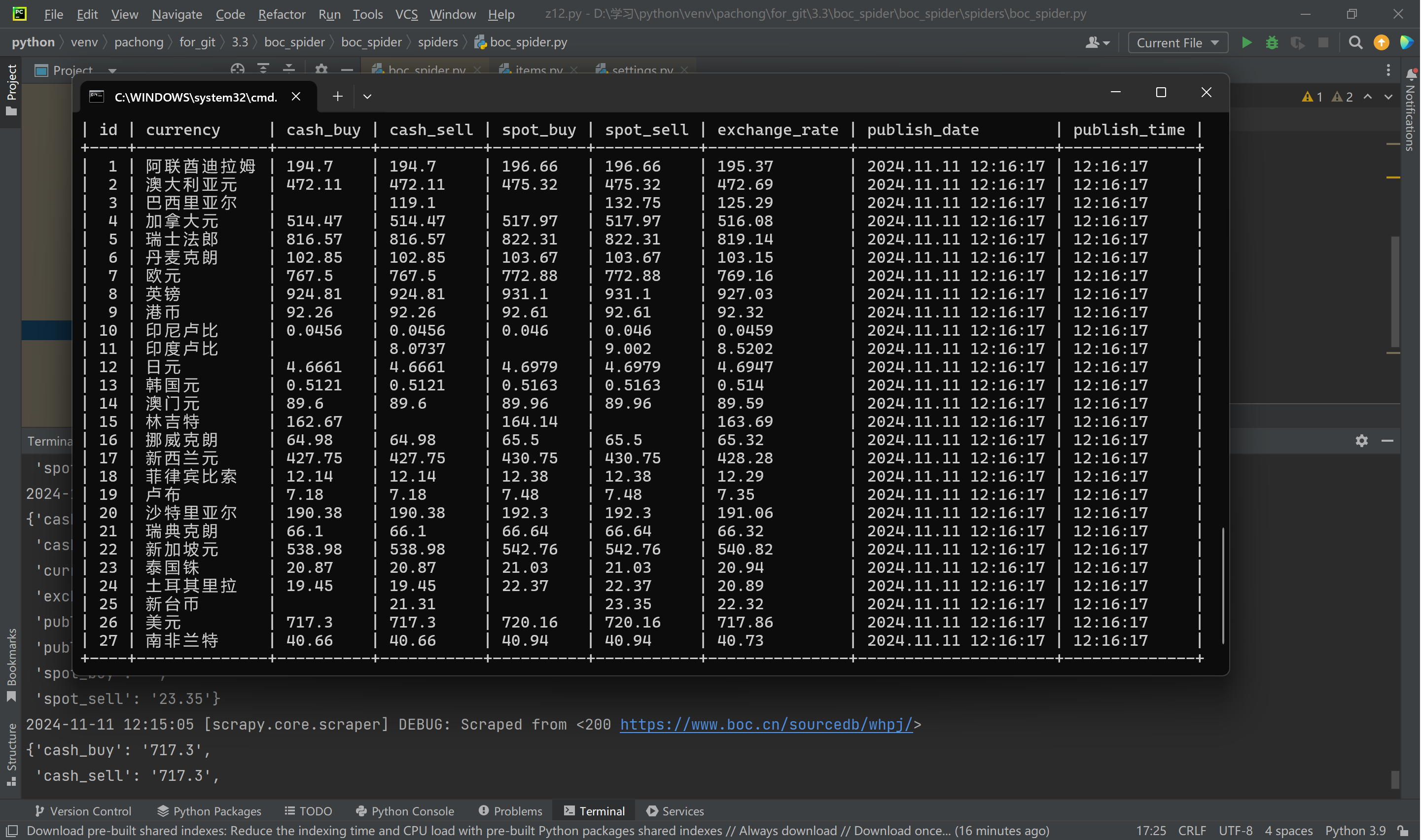
Gitee文件夹链接:https://gitee.com/wang-hengjie-100/crawl_project
作业心得
作业①:爬取图片并保存到本地
在进行这项作业时,我深入了解了Scrapy框架的使用,特别是如何控制爬取的数量和限制爬取的范围。通过实现单线程和多线程的爬取,我学会了如何通过不同的方式提高爬取效率,同时避免对目标网站造成过多的负担。图片下载功能的实现让我体验了如何处理大规模文件的保存问题,并且通过设置文件夹来管理下载的图片,保持了系统的整洁性。此外,学号尾数的限制让我更加注重爬取的控制,避免因过度爬取而导致的资源浪费。
作业②:爬取股票信息并存储到MySQL数据库
通过这项作业,我深刻理解了如何使用Scrapy框架结合Xpath进行数据的提取。XPath在选择和筛选网页元素时的灵活性给我留下了深刻印象,使得在复杂网页结构中提取股票信息变得更加简便。尤其是在将爬取的数据存储到MySQL数据库时,我学会了如何设计数据库表结构,利用Python与MySQL的连接进行数据存储。同时,作业中涉及到的数据序列化输出方法,也让我掌握了如何更好地管理爬取的数据,确保其在数据库中的存储形式整洁且可维护。
作业③:爬取外汇数据并存储到MySQL数据库
这项作业让我进一步巩固了之前学到的爬取网页数据的技巧,并且通过爬取外汇网站的数据,我了解了如何处理外汇数据的特殊性,比如实时性和更新频率。通过Scrapy的Pipeline技术,我可以轻松地将数据保存到MySQL数据库,并且在遇到重复数据时进行处理。这项作业让我熟悉了如何设计合适的字段来存储外汇数据,并确保每次爬取的数据都能够正确插入数据库。通过这一过程,我进一步理解了如何用Scrapy框架进行数据抓取、清洗和存储的全过程。
 posted on
posted on

